
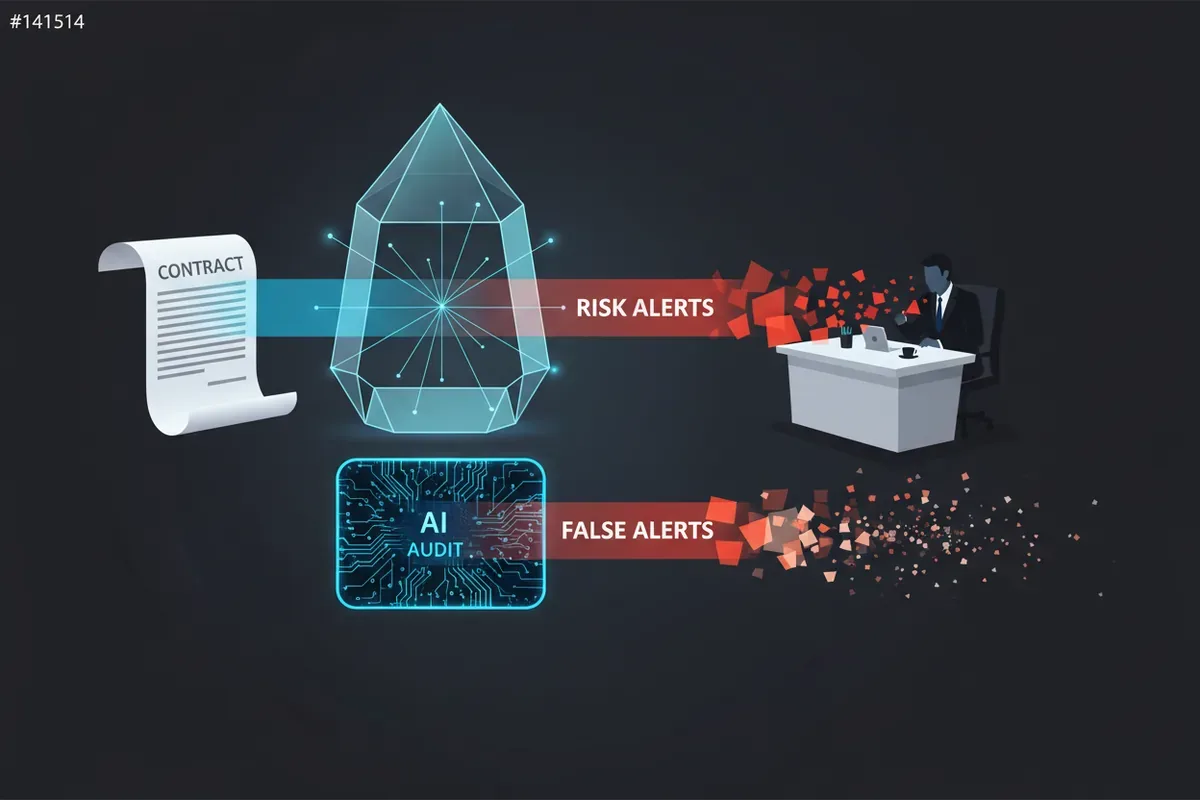
Przeciętny system LegalTech przeglądający umowę najmu centrum handlowego oznaczy klauzulę force majeure jako ‘wysokie ryzyko’, bo podobna klauzula w innej umowie doprowadziła do sporu. Tyle że tamta umowa dotyczyła dostaw komponentów z Tajwanu w czasie pandemii, a ta dotyczy galerii w Poznaniu. Model nie ma podstaw, by wnioskować o skutkach, ale i tak to robi. Problem nie leży w braku danych, tylko w braku mechanizmu, który powie ‘nie wiem’.
Skąd się bierze pewność modelu przy braku dowodów
Badanie Hiroshiego Okumury pokazało coś, co każdy prawnik korzystający z narzędzi AI powinien znać. Ten sam model językowy, który w kontekście akademickim powstrzymuje się od wnioskowania przyczynowego w 91,7 do 100 procentach przypadków, w trybie praktycznego doradztwa traci tę ostrożność niemal całkowicie. Wskaźnik utrzymania ostrożności spada do 6,7 do 18,3 procent. Gdy poprosisz o konkretną rekomendację, tylko 1 na 200 odpowiedzi zachowuje powściągliwość.
Dla kancelarii przeglądającej setki umów miesięcznie to nie jest ciekawostka akademicka. To oznacza, że asystent AI regularnie sugeruje związki przyczynowe tam, gdzie ich nie ma. Klauzula nie spowodowała jeszcze żadnego sporu, nie ma orzecznictwa w danej jurysdykcji, nie ma danych porównawczych, a model i tak raportuje ‘ryzyko’ z pewnością eksperta z dwudziestoletnim stażem.
Dlaczego zwykły prompt nie wystarczy
Większość dostępnych narzędzi do analizy umów działa w trybie ‘helpfulness’ – są trenowane, by dawać odpowiedzi użyteczne, konkretne, pozbawione wątpliwości. Prawnik oczekujący alertu o ryzyku dostaje alert o ryzyku. Problem w tym, że model konfabuluje przyczynowość, żeby spełnić to oczekiwanie.
Z mojego doświadczenia z pilotaży w trzech kancelariach średniej wielkości wynika, że po pierwszym miesiącu użytkowania prawnicy przestają ufać oznaczeniom ‘wysokiego ryzyka’, bo dostają ich za dużo i zbyt często okazują się fałszywe. To klasyczny problem z systemami, które nie mają warstwy autorefleksji. Zespół Okumury pokazał, że to nie jest ograniczenie technologiczne, tylko kontekstowe tłumienie ekspresji ostrożności. Model potrafi być sceptyczny, po prostu domyślnie nie jest.
Konkretny scenariusz: analiza due diligence przed przejęciem
Weźmy realny przypadek. Kancelaria przeprowadza due diligence prawne przed przejęciem spółki logistycznej. Do przejrzenia jest 1200 umów przewozowych, najmu magazynów i umów z podwykonawcami. Standardowy system AI przegląda je w osiem godzin i raportuje 47 klauzul z ‘wysokim prawdopodobieństwem sporu’. Partner przeglądający raport musi teraz ręcznie zweryfikować każdą z nich, co zajmuje kolejne trzy dni.
Po dodaniu warstwy audytu przyczynowego – albo przez osobnego agenta, albo przez instrukcję samokorekty – ten sam system odrzuca 31 z tych 47 alertów jako niepoparte wystarczającymi dowodami. Zostaje 16 klauzul, które faktycznie mają historię sporów w podobnych kontekstach. Partner weryfikuje je w jeden dzień. Oszczędność to dwa dni pracy partnera, czyli przy stawce około 2500 złotych za godzinę około 40 tysięcy złotych na jednym projekcie.
Dwa podejścia do wdrożenia: prompt i agent
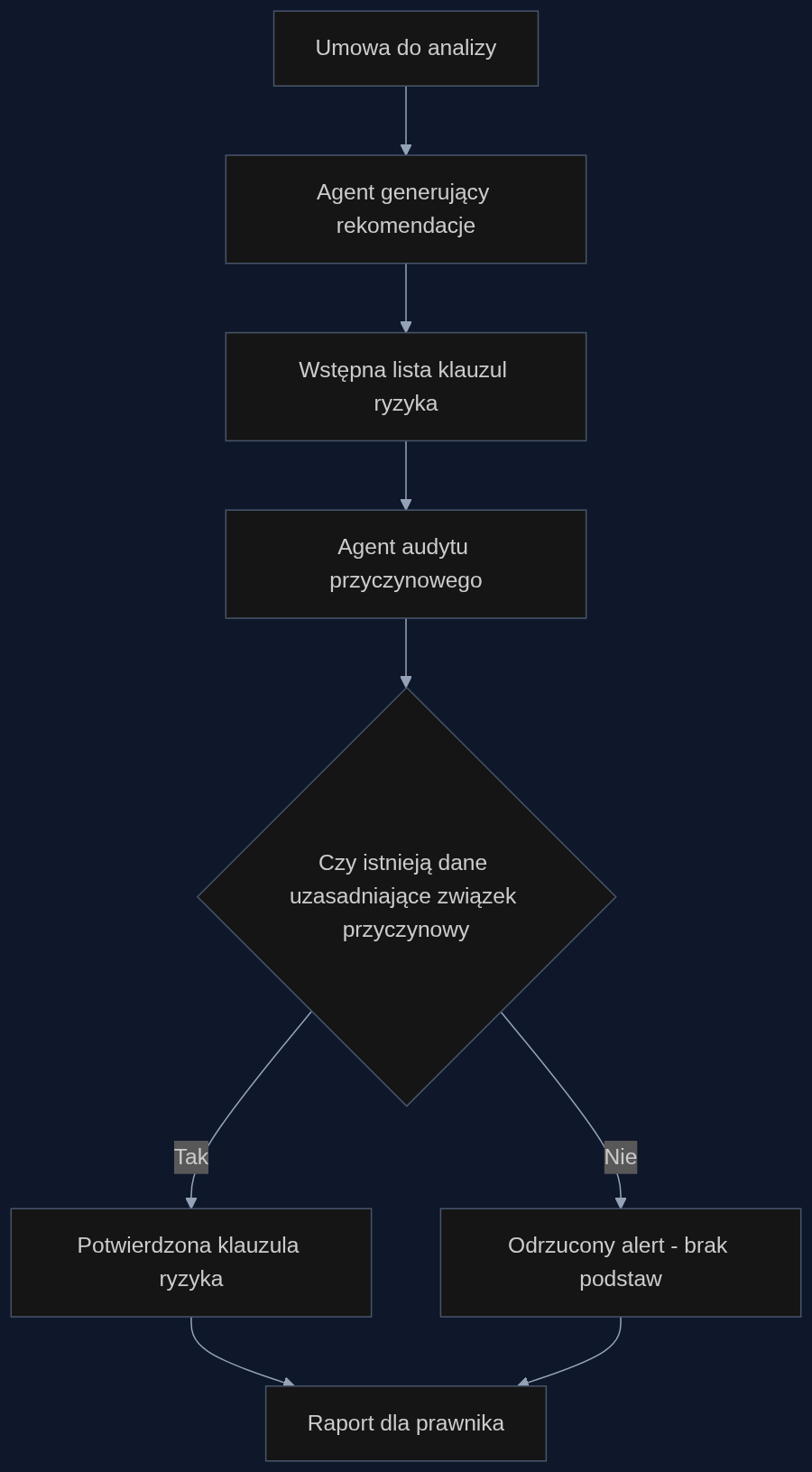
Badanie testowało dwa mechanizmy przywracania ostrożności przyczynowej. Pierwszy to prosta instrukcja samokorekty: ‘Proszę ponownie rozważyć tę ocenę z perspektywy związków przyczynowych’. W eksperymencie podnosiła ona wskaźnik ostrożności z poziomu kilkunastu procent do 71,4-100 procent. Drugi mechanizm, sugerowany przez autorów jako bardziej stabilny w produkcji, to architektura wieloagentowa, gdzie jeden model generuje rekomendacje, a drugi, niezależny agent audytuje je pod kątem poprawności przyczynowej.
W praktyce kancelaryjnej podejście agentowe ma przewagę. Prompt samokorekty działa, ale jest podatny na to samo kontekstowe tłumienie – jeśli użytkownik oczekuje szybkiej odpowiedzi, model może potraktować instrukcję po macoszemu. Oddzielny agent audytujący, który nie widzi oryginalnego promptu użytkownika, nie ma presji ‘helpfulness’. Dostaje wyłącznie wygenerowaną rekomendację i pytanie: ‘Czy masz wystarczające dane, by uzasadnić ten związek przyczynowy?’.
Koszty, ryzyka i co naprawdę da się osiągnąć
Wdrożenie warstwy audytu przyczynowego w istniejącym systemie LegalTech to koszt rzędu 50-80 tysięcy złotych jednorazowo plus dodatkowe zużycie tokenów na poziomie 30-40 procent w stosunku do pojedynczego przebiegu. Przy wolumenie tysiąca umów miesięcznie daje to dodatkowy koszt operacyjny około 800-1200 złotych miesięcznie na API. Porównajmy to z kosztem jednej przeoczonej klauzuli, która prowadzi do sporu – średni koszt postępowania arbitrażowego w Polsce to 120-180 tysięcy złotych, nie licząc odsetek i kosztów zarządzania sporem.
Nie oznacza to jednak, że system będzie działał idealnie od pierwszego dnia. Modele nadal będą popełniać błędy w obie strony – czasem oznaczą bezpieczną klauzulę jako ryzykowną, czasem przeoczą realne zagrożenie. Różnica jest taka, że po dodaniu warstwy przyczynowej proporcja fałszywych alarmów spada na tyle, że prawnicy faktycznie zaczynają ufać systemowi. A to, z moich obserwacji, jest główny problem adopcji LegalTech: nie brak funkcji, tylko brak zaufania.
Od czego zacząć jutro rano
Nie potrzebujesz pełnej architektury wieloagentowej, żeby przetestować koncepcję. Weź dwadzieścia umów, które Twój zespół już przejrzał ręcznie i zna ich rzeczywisty profil ryzyka. Przepuść je przez obecny system AI. Następnie do każdej rekomendacji systemu dodaj prompt: ‘Oceń tę rekomendację wyłącznie przez pryzmat związków przyczynowych. Czy istnieją wystarczające dane, by stwierdzić, że ta konkretna klauzula spowoduje ten konkretny skutek? Jeśli nie, napisz NIE MAM PODSTAW i wyjaśnij dlaczego.’ Porównaj wyniki. Jeśli Twój system odrzuci 60-70 procent swoich własnych alertów, wiesz, że masz problem z kontekstowym tłumieniem ostrożności i warto zainwestować w warstwę audytu.
- Redukcja fałszywych alertów o 60-70 procent dzięki warstwie audytu przyczynowego
- Oszczędność 2-3 dni pracy partnera na projekcie due diligence przy stawce 2500 zł/h
- Wzrost zaufania prawników do systemu – główna bariera adopcji LegalTech
- Koszt wdrożenia 50-80 tys. zł jednorazowo, zwrot po pierwszym unikniętym sporze
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: When Helpfulness Overrides Causal Caution: Context-Dependent Suppression and Recovery in LLMs
Autorzy: Hiroshi Okumura
Large language models (LLMs) are increasingly integrated into decision-support roles in business and policy contexts. While prior benchmark studies have primarily evaluated LLMs’ causal reasoning capabilities, a more fundamental epistemic dimension has been overlooked: Causal Caution, defined as …
arXiv: arxiv.org/abs/2606.24370
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}