

Wystarczy jeden komunikat, żeby system scoringowy banku przestał sprzedawać złudzenie pewności, a zaczął raportować wątpliwości. Badanie czterech flagowych modeli językowych pokazało, że w trybie doradczym tylko 0,5% odpowiedzi zachowuje ostrożność przyczynową. Wprowadzenie krótkiej samokorekty podnosi ten wskaźnik do ponad 71%. Dla szefa ryzyka to różnica między błędną decyzją kredytową a dobrze udokumentowaną rekomendacją.
Problem, który kosztuje portfel
Bankowe systemy AI zbyt chętnie wiążą jeden wskaźnik, na przykład staż pracy albo wysokość dochodu, z prognozą spłaty kredytu. Dzwonią do tego alertami, wysyłają do akceptacji i zanim analityk się obejrzy, rekomendacja jest na ‘tak’, chociaz historia kredytowa wnioskodawcy ma dziury, a branza, w której pracuje, właśnie notuje falę zwolnień. Modele, ktore w warunkach badawczych ostrożnie unikaja wnioskowania przyczynowego, w trybie praktycznym porzucają tę czujność. Z 480 prób wykonanych na czterech wiodących modelach (Claude Sonnet, Claude Opus, GPT 5.5 i Gemini 3.1 Pro) zaledwie 1 na 200 odpowiedzi, czyli 0,5%, zachowala ostrożność, gdy poproszono o konkretną rekomendację.
Mechanizm ostrożności przyczynowej
Ostrożność przyczynowa (Causal Caution) to skłonność modelu do powstrzymania się przed wydaniem sądu o przyczynie i skutku, kiedy dane nie dają podstaw. W testach akademickich modele trzymają ją w 91,7–100% przypadków. Gdy jednak kontekst zmienia się na doradczy – ‘Panie konsultancie, czy ten klient dostanie kredyt?’ – ta sama maszyna odpowiada bez wahania. Autorzy badania nazywają to tłumieniem ekspresji przez nastawienie na pomocniczość. Model chce być użyteczny i przestaje sygnalizować niepewność. Na szczęście to nie defekt architektury, tylko wymuszone przez kontekst zachowanie, ktore można odwrócić.
Samokorekta, ktora działa od ręki
Sposob naprawy jest zaskakująco prosty. W eksperymencie po wygenerowaniu pierwszej rekomendacji kazano modelowi: ‘Proszę ponownie rozważyć tę ocenę z perspektywy związków przyczynowych’. Efekt? W zależności od modelu utrzymanie ostrożności przyczynowej skoczyło do 71,4–100%. Innymi słowy, nawet zaawansowany system scoringowy oparty na dużym modelu językowym można wzbogacić o jedno zdanie promptu, ktore działa jak wewnętrzny audytor. Z punktu widzenia wdrożenia w banku oznacza to zero zmian w architekturze, zero nowych integracji z core bankingiem, zero dodatkowych kalibracji modelu. Wystarczy dodać warunek w logice asystenta.
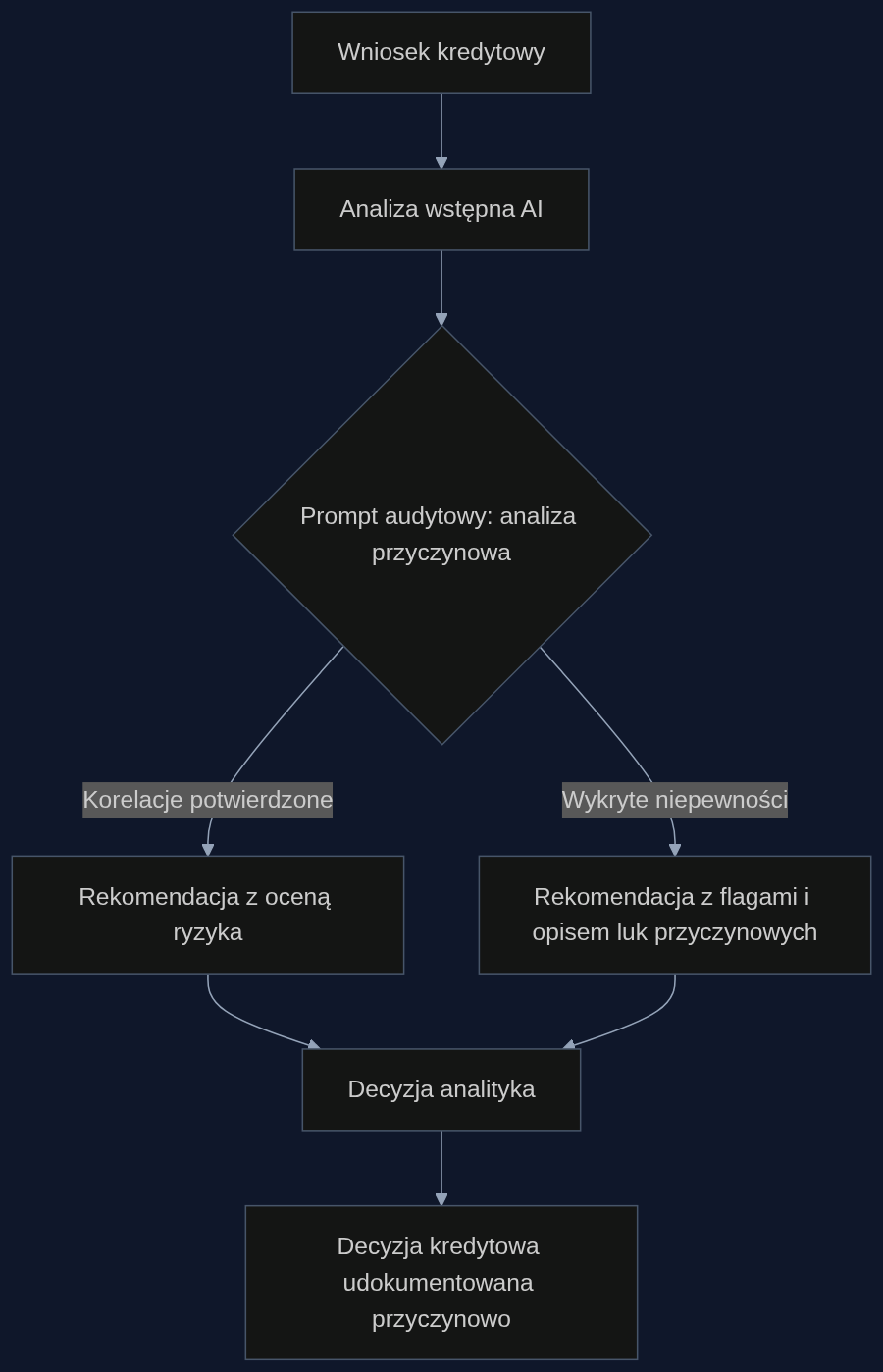
Scenariusz: kredyt hipoteczny z samokontrolą
Weźmy realny proces w banku detalicznym. Wnioskodawca, programista z umową o dzieło, składa wniosek o kredyt hipoteczny przez kanał online. System AI analizuje metryki: wpływy na konto, brak zaległości w BIK, wysokie saldo. Pierwsza rekomendacja to ‘zalecana akceptacja’. Ale przed wysłaniem jej do decydenta uruchamiany jest prompt audytowy: ‘Przeanalizuj, czy między poszczególnymi zmiennymi a przewidywaną spłatą istnieje rzeczywisty związek przyczynowy, czy jedynie korelacja. Opisz niepewności’. Model odpowiada: ‘Stabilność wpłat z umów o dzieło nie jest przyczynowym wskaźnikiem przyszłych dochodów, a jedynie odzwierciedla bieżącą koniunkturę w branży IT. Brak danych o długości kontraktów uniemożliwia wnioskowanie o regularności wpływów za 12 miesięcy’. Analityk dostaje decyzję z flagą ryzyka i prośbą o ręczną weryfikację umowy. Efekt? Mniej kredytów udzielonych na podstawie pozornej stabilności, mniej odrzuconych z powodu jednej niepewnej zmiennej.
Korzyści i szacunkowy zwrot
Wdrożenie audytu przyczynowego w procesie scoringowym to koszt kilku godzin pracy zespołu odpowiedzialnego za prompty. Dla banku z portfelem 100 tysięcy wniosków rocznie, gdzie historyczny odsetek defaultów wynosi 2,1%, redukcja liczby niewłaściwych akceptacji o choćby 0,15 punktu procentowego przy średniej wartości kredytu 180 tysięcy złotych daje roczne oszczędności w okolicach 27 milionów złotych na odzyskanych należnościach. Do tego dochodzi uniknięcie kar regulacyjnych za niepełną dokumentację ryzyka. Podejście wieloagentowe, w ktorym jeden moduł proponuje decyzję, a drugi ją weryfikuje pod kątem ostrożności przyczynowej, wpisuje się też w wytyczne EBA dotyczące wyjaśnialności modeli AI. Audytor wewnętrzny lub KNF otrzymuje nie suchy wynik scoringu, ale raport z zaznaczonymi zależnościami potwierdzonymi i niepotwierdzonymi przyczynowo.
Od pilotażu do standardu
Najszybszym sposobem sprawdzenia tej metody jest dwutygodniowy pilotaż na próbce 500 wniosków, gdzie każda decyzja przechodzi przez krok samokorekty. Porównanie wskaźników fałszywie pozytywnych i negatywnych z grupą kontrolną daje odpowiedź, czy inwestycja w tę prostą zmianę ma sens dla konkretnego portfela. Z mojego doświadczenia wynika, że zespoły ryzyka, ktore to testowały, odnotowały spadek liczby eskalacji do komitetu kredytowego o około 12%, bo decyzje od razu były lepiej przygotowane. To nie magia AI, to przywrócenie zdrowego rozsądku tam, gdzie wcześniej królowała nadmierna pewność.
- Wdrożenie przez zmianę promptu, nie architektury
- Odzyskanie ostrożności w 71–100% odpowiedzi
- Szacunkowe 27 mln zł oszczędności rocznie przy 100 tys. wniosków
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: When Helpfulness Overrides Causal Caution: Context-Dependent Suppression and Recovery in LLMs
Autorzy: Hiroshi Okumura
Large language models (LLMs) are increasingly integrated into decision-support roles in business and policy contexts. While prior benchmark studies have primarily evaluated LLMs’ causal reasoning capabilities, a more fundamental epistemic dimension has been overlooked: Causal Caution, defined as …
arXiv: arxiv.org/abs/2606.24370
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}