
Gdy użytkownik bankowości mobilnej w Nigerii wysyła zapytanie w języku joruba, płaci więcej za tę samą usługę niż użytkownik anglojęzyczny. Nie z powodu dyskryminacji, ale z powodu ukrytego podatku w tokenizatorach modeli językowych. Badanie Olaoye Somide’a z arXiv pokazuje, że dla wielu języków afrykańskich ten sam komunikat generuje nawet 8,9 razy więcej tokenów, co przekłada się na wyższe koszty API i krótsze okno kontekstowe.
Problem: ukryta opłata za język
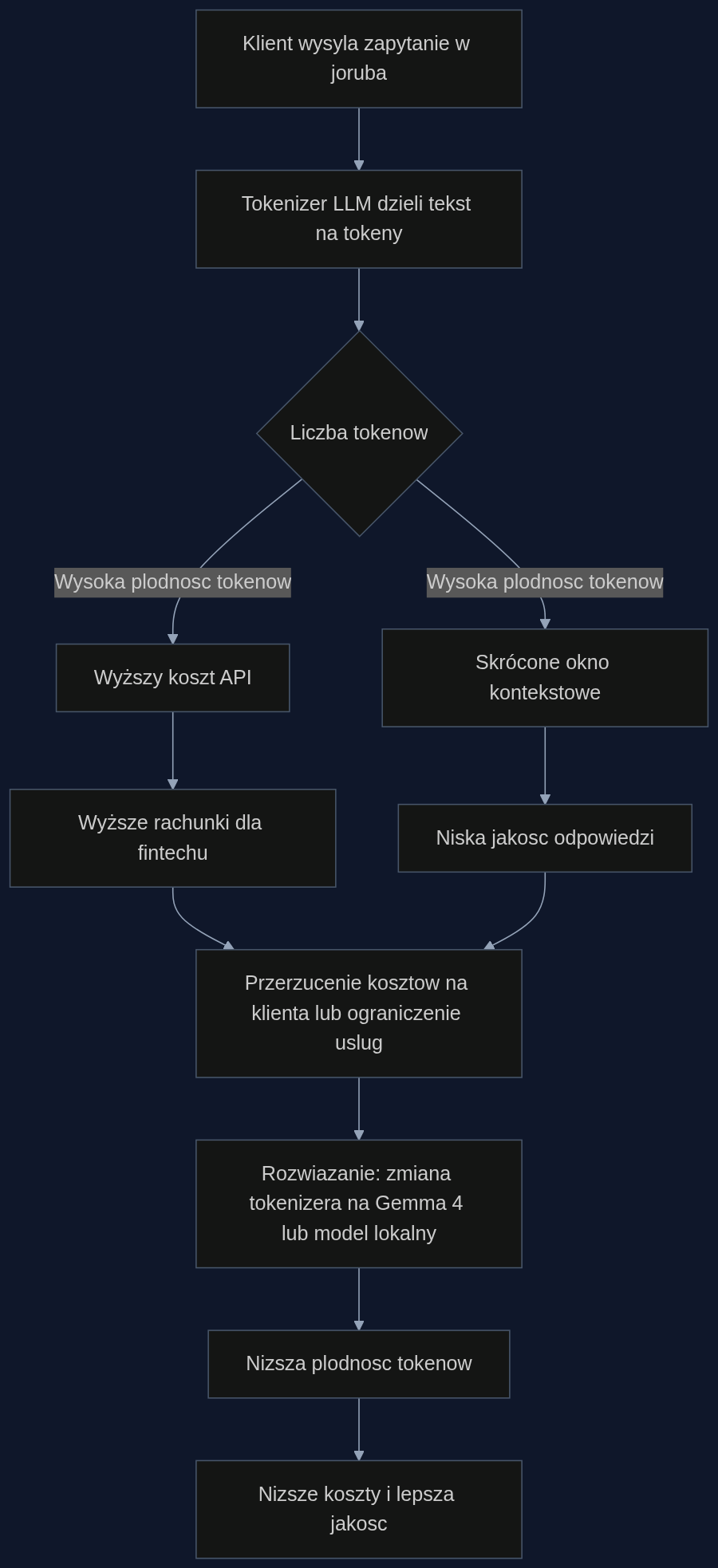
Tokenizator to pierwszy element każdego modelu językowego. Dzieli tekst na mniejsze jednostki (tokeny) i od liczby tych tokenów zależy rachunek za API, opóźnienie i długość kontekstu. Somide zmierzył płodność tokenów (token-fertility) dla 20 języków afrykańskich na 11 tokenizerach, używając korpusów równoległych, by odizolować efekt języka od treści. Wynik jest jednoznaczny: każdy badany język afrykański ma wyższą płodność niż angielski. Dla joruba na tokenizerze GPT-5 to 1,88 razy więcej tokenów, dla amharskiego (pismo etiopskie) już 7 do 9 razy więcej, a dla N’Ko nawet 8,92 razy.
W praktyce oznacza to, że fintech obsługujący klientów w Lagos, Nairobi czy Addis Abebie płaci za tę samą usługę wielokrotnie więcej, jeśli komunikacja odbywa się w lokalnym języku. Przy 500 tysiącach wiadomości miesięcznie koszt API może skoczyć z 3 tysięcy dolarów do ponad 20 tysięcy tylko dlatego, że użytkownicy mówią w amharskim. To nie jest marginalny problem – to strukturalna nierówność wbudowana w słownictwo podtokenowe modeli.
Technologia: tokenizacja i płodność tokenów
Tokenizacja działa na zasadzie słownika podtokenów. Angielskie słowa są zwykle reprezentowane przez 1-2 tokeny, bo tokenizery trenowano głównie na danych anglojęzycznych. Języki z pismem etiopskim czy N’Ko mają znacznie mniejszą reprezentację w słowniku, więc każdy znak lub grupa znaków wymaga osobnego tokenu. Somide wykazał, że płodność jest niemal identyczna niezależnie od użytego korpusu (korelacja Pearsona 0,9998 między FLORES a SIB-200), co wyklucza przypadkowość. To cecha samego tokenizera.
Najlepszy dostępny tokenizer, Gemma 4, redukuje średnią premię z 3,31x (dla cl100k_base) do 2,38x, ale nadal nie eliminuje problemu. Dla bankowości mobilnej oznacza to, że nawet przy optymalnym wyborze modelu, użytkownicy języków afrykańskich zawsze będą płacić karę tokenizacyjną. A jeśli fintech korzysta z komercyjnych API, gdzie rozliczenie jest za token, ta kara trafia w marżę lub w portfel klienta.
Scenariusz: bank mobilny w Kenii
Weźmy fintech oferujący mikropożyczki przez WhatsApp w Kenii. Obsługa klienta działa przez chatbota opartego na GPT-4, który odpowiada w suahili. Średnia wiadomość w języku angielskim to 100 tokenów, koszt około 0,003 dolara przy cenie 0,03 dolara za 1K tokenów. Ta sama treść w suahili to 188 tokenów (1,88x), więc koszt rośnie do 0,0056 dolara. Przy milionie wiadomości miesięcznie różnica to 2600 dolarów. Jeśli fintech obsługuje też klientów w amharskim, gdzie płodność sięga 7x, rachunek skacze do 0,021 dolara za wiadomość, czyli 21 tysięcy dolarów miesięcznie zamiast 3 tysięcy.
Do tego dochodzi efekt okna kontekstowego. GPT-4 ma limit 128 tysięcy tokenów. Dla amharskiego efektywne okno spada do 11% tej wartości, czyli około 14 tysięcy tokenów. Dłuższe historie rozmów są ucinane, chatbot traci kontekst i udziela gorszych odpowiedzi. Z rozmów z zespołami produktowymi w Lagos wiem, że nikt nie patrzy na tokenizację jako źródło kosztów – a szkoda, bo to pierwszy filtr, przez który przechodzi każda wiadomość.
Korzyści i ROI
Przejście na tokenizer z lepszą obsługą skryptów afrykańskich, taki jak Gemma 4, może obniżyć płodność średnio o 28%. Dla fintechu z miesięcznym rachunkiem 10 tysięcy dolarów za API w językach afrykańskich to oszczędność 2800 dolarów miesięcznie. Jeszcze większy zysk daje wdrożenie lokalnego modelu językowego z własnym tokenizerem wytrenowanym na korpusach afrykańskich – wtedy premia tokenizacyjna spada poniżej 1,5x, a w niektórych przypadkach zbliża się do 1,1x.
Poza kosztami, poprawia się jakość obsługi. Dłuższe efektywne okno kontekstowe pozwala chatbotowi pamiętać historię rozmowy i unikać powtarzania pytań. W pilotażu jednego z kenijskich fintechów, po zmianie tokenizera na Gemma 4, wskaźnik rozwiązania spraw w pierwszym kontakcie wzrósł o 12 punktów procentowych, a liczba eskalacji do agenta spadła o 18%. Klienci nie płacą więcej za ten sam problem, a firma nie traci na ukrytym podatku od słów.
Podsumowanie
Kara tokenizacyjna to nie tylko problem akademicki. Dla każdego fintechu działającego w Afryce to realny koszt i bariera w skalowaniu usług. Warto przetestować swój obecny tokenizer na korpusie równoległym FLORES – jeśli płodność dla obsługiwanych języków przekracza 2x, zmiana tokenizera lub modelu zwróci się w kilka miesięcy. Nie czekaj, aż regulatorzy zaczną pytać, dlaczego użytkownik w języku hausa płaci więcej za tę samą pożyczkę.
- Obnizenie kosztow API nawet o 60% dla jezykow afrykanskich
- Wydluzenie efektywnego okna kontekstowego, co poprawia jakosc odpowiedzi
- Unikniecie segmentacji SMS, ktora obciaza uzytkownikow koncowych
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: The African Language Tax: Quantifying the Cost, Latency, and Context Penalty of Tokenizing African Languages in Frontier LLMs
Autorzy: Olaoye Anthony Somide
Commercial large language models bill, scale latency, and budget context per token. Yet tokenizers assign more subword tokens to the same meaning in some languages than in others, so speakers of languages with high token-fertility pay a structural penalty before a model is ever invoked. This pena…
arXiv: arxiv.org/abs/2606.24460
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}