
Karmimy modele coraz większą ilością danych, a one nadal mylą się w prostym wnioskowaniu. Trzech badaczy z Cambridge i Edynburga przekonuje, że to nie kwestia rozmiaru — to wada wrodzona podejścia, które stawia na wzorce zamiast na reguły.
Sylogizm, który człowiek rozumie od razu
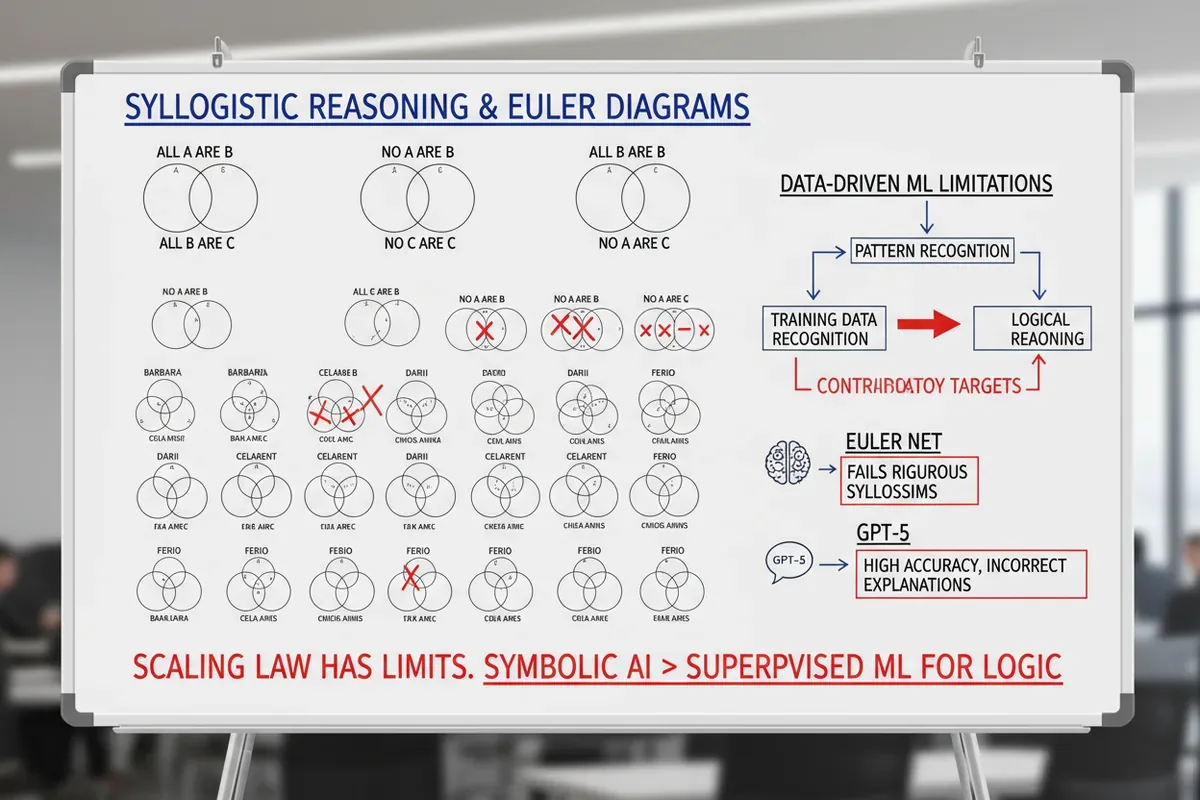
Każdy człowiek bez wahania powie, że jeśli ‘wszystkie psy to ssaki, a wszystkie ssaki to zwierzęta’, to ‘psy to zwierzęta’. Dla sztucznej inteligencji to wcale nie jest proste. Sylogizm, najprostsza forma logicznego rozumowania, w której na podstawie dwóch przesłanek wyciąga się trzeci wniosek, od lat spędza sen z powiek inżynierom AI. Okazuje się, że nauka maszynowa oparta na danych nie potrafi w pełni ogarnąć nawet tych prostych reguł, a powiększanie sieci czy zwiększanie ilości danych nie rozwiązuje problemu.
Autorzy pracy pokazują, dlaczego tak się dzieje. Przyglądają się, jak działa nadzorowane uczenie głębokie w zadaniach logicznych i wskazują dwa powody, dla których ono zawodzi. Po pierwsze, dane treningowe nie są w stanie odróżnić wszystkich 24 typów poprawnego rozumowania sylogistycznego. Po drugie, sieć neuronowa jest uczona ‘od końca do końca’, od przesłanek do wniosku, co tworzy sprzeczne cele między częścią odpowiedzialną za rozpoznawanie wzorców a tą, która miałaby prowadzić logiczną dedukcję.
Neuronowa sieć, która miała myśleć jak Euklides
Euler Net to architektura zaprojektowana specjalnie do rozumowania logicznego. Łączy diagramy Eulera (kółka reprezentujące zbiory) z głębokim uczeniem, aby naśladować sposób, w jaki ludzie wizualizują relacje między kategoriami. Pomysł był obiecujący: sieć miała uczyć się reprezentacji zbiorów i ich przecięć, a potem na tej podstawie wyciągać poprawne wnioski logiczne. Testy pokazały jednak, że Euler Net nie osiąga rygoru symbolicznego. W wielu przypadkach się myli, zwłaszcza gdy sylogizm wymaga subtelniejszej interpretacji, jak relacje ‘niektóre’ czy ‘żadne’.
Dlaczego? Bo uczenie głębokie polega na dopasowywaniu wzorców, a nie na przestrzeganiu sztywnych reguł. Kiedy sieć widzi podobny układ słów, aktywuje znajomą ścieżkę, nawet jeśli formalnie przekształcenie prowadzi do fałszywego wniosku. To trochę tak, jakby uczeń zapamiętał, że ‘wszystkie A to B’ i ‘wszystkie B to C’ daje ‘A to C’, a potem ten sam schemat zastosował do zdań, gdzie ten wniosek nie zachodzi, bo nie rozumie, co naprawdę znaczą kwantyfikatory.
Dane treningowe nie są w stanie odróżnić wszystkich 24 typów poprawnego rozumowania sylogistycznego.
Tiansi Dong, Mateja Jamnik, Pietro Liò
Abstrakt
ChatGPT myli słowa z logiką
Aby pokazać, że duże modele językowe też cierpią na tę przypadłość, badacze przepytali ChatGPT w wersji GPT-5 i GPT-5-nano. Poprosili je o ocenę, czy z podanych przesłanek da się wyciągnąć logiczny wniosek (sprawdzalność układu zdań). Co istotne, te same logiczne treści podali w czterech różnych ‘formach powierzchniowych’: zwykłych angielskich słowach, podwójnych słowach (‘dog dog’, ‘cat cat’), prostych symbolach (A, B, C) i długich losowych symbolach (‘xnbcy’, ‘pqrst’).
Wyniki rozjechały się w sposób, który trudno uznać za przypadek. Gdy logika była ubrana w znajome słowa, model radził sobie nieźle. Przy losowych symbolach dokładność potrafiła spaść nawet o kilkadziesiąt procent. Wygląda na to, że ChatGPT nie przeprowadza faktycznego rozumowania: po prostu odgaduje wzorce na podstawie powierzchownych cech tekstu. Co więcej, nawet gdy GPT-5 osiągał 100% trafności w jakimś wariancie, jego wyjaśnienia, dlaczego dane zdania są spełnialne, pozostawały błędne. Model udzielał poprawnej odpowiedzi, ale z niewłaściwych powodów.
Prawo skalowania uderza w sufit
Od lat pokłada się nadzieję w tzw. prawie skalowania: im więcej danych i mocy obliczeniowej, tym modele stają się mądrzejsze. Autorzy artykułu twierdzą, że w przypadku logicznego rozumowania ten proces utknął w martwym punkcie. ‘Systemy nadzorowanego uczenia maszynowego nie osiągną rygoru symbolicznego rozumowania logicznego’, piszą wprost. Jeśli mają rację, to znaczy, że żaden, nawet największy model trenowany wyłącznie na danych nie nauczy się naprawdę wnioskować, będzie jedynie coraz sprawniej udawał.
To ma konsekwencje wykraczające poza akademickie dyskusje. Jeśli algorytm, który ma podejmować decyzje medyczne, prawne czy finansowe, opiera się tylko na statystycznym dopasowaniu wzorców, to w nieoczywistych przypadkach może zawieść w sposób trudny do przewidzenia. Nie pomoże tu dołożenie kolejnych terabajtów danych: źródło problemu leży głębiej, w samej naturze nadzorowanego uczenia.
- Dane treningowe nie zawierają informacji koniecznych do odróżnienia wszystkich poprawnych schematów sylogistycznych.
- Uczenie ‘od końca do końca’ zmusza sieć do godzenia sprzecznych celów: elastyczności wzorców i sztywności reguł.
- ChatGPT potrafi rozpoznawać logikę w znajomych słowach, ale zawodzi, gdy treść zostanie przedstawiona w innej formie.
- Nawet 100% trafności nie gwarantuje poprawnego rozumowania — modele podają dobre odpowiedzi z błędnych powodów.
Praktyczne zastosowania
Aby lepiej zrozumieć opisywaną innowację, przygotowaliśmy cztery przykłady praktycznego zastosowania tej technologii w różnych branżach:



Podsumowanie
Artykuł podkreśla, że modele AI świetnie sprawdzają się w zadaniach opartych na statystycznych wzorcach, jak tłumaczenie czy generacja tekstu, ale nie można im ufać w kwestiach wymagających niezawodnego logicznego wnioskowania. W medycynie, prawie czy systemach bezpieczeństwa, gdzie błędna decyzja ma poważne konsekwencje, konieczne jest łączenie sieci neuronowych z jawnym wnioskowaniem symbolicznym. Bez tego opieranie się wyłącznie na modelach uczonych na danych może prowadzić do kosztownych błędów, nawet gdy statystyki sugerują wysoką skuteczność.
Metryka artykułu źródłowego
Tytuł oryginalny: Data-driven Machine Learning Cannot Reach Symbolic-level Logical Reasoning — The Limit of the Scaling Law
Autorzy: Tiansi Dong, Mateja Jamnik, Pietro Li\`o
Data publikacji: 26 czerwca 2026
arXiv: arxiv.org/abs/2606.26454
Napisanie tego artykułu zostało wspomagane przez sztuczną inteligencję. Treść opiera się na oryginalnym artykule naukowym, a jej dokładność została zweryfikowana automatycznie.
{kind=link}