

Każdy, kto używał GitHub Copilot wie, że generowany kod rzadko jest bezbłędny od razu. Pętle do-while w nieskończoność, pominięte null-checki, zmienne nazwane x i y bez kontekstu to codzienność. Przeciętny programista spędza 20 do 30 minut dziennie na weryfikację i poprawki sugestii AI. Okazuje się, że te błędy nie wynikają z braków modelu, tylko z jego specyficznej psychologii: model traktuje własne wyjście inaczej niż kod napisany przez kogoś innego. Ten mechanizm można jednak sprytnie wykorzystać, by zmusić AI do autokorekty bez dodatkowego treningu.
Dlaczego modele ignorują własne błędy
W badaniu z 2025 roku (Chen, Su, Chiang) pokazano, że duże modele językowe mają o 23 do 93 punktów procentowych wyższy wskaźnik korekcji, gdy to samo błędne twierdzenie zostanie przepakowane jako komunikat od zewnętrznego narzędzia, a nie własna myśl asystenta. Innymi słowy, AI ignoruje własne błędy, ale gorliwie poprawia ‘cudze’. Autorzy udowodnili, że to nie deficyt poznawczy, a artefakt szablonu czatu, który determinuje, czy model przejdzie w tryb krytycznej analizy. Efekt jest odporny na domenę: działa zarówno w matematyce, dedukcji logicznej, jak i w generowaniu kodu.
Patent: przepakowanie kodu jako odpowiedzi narzędzia
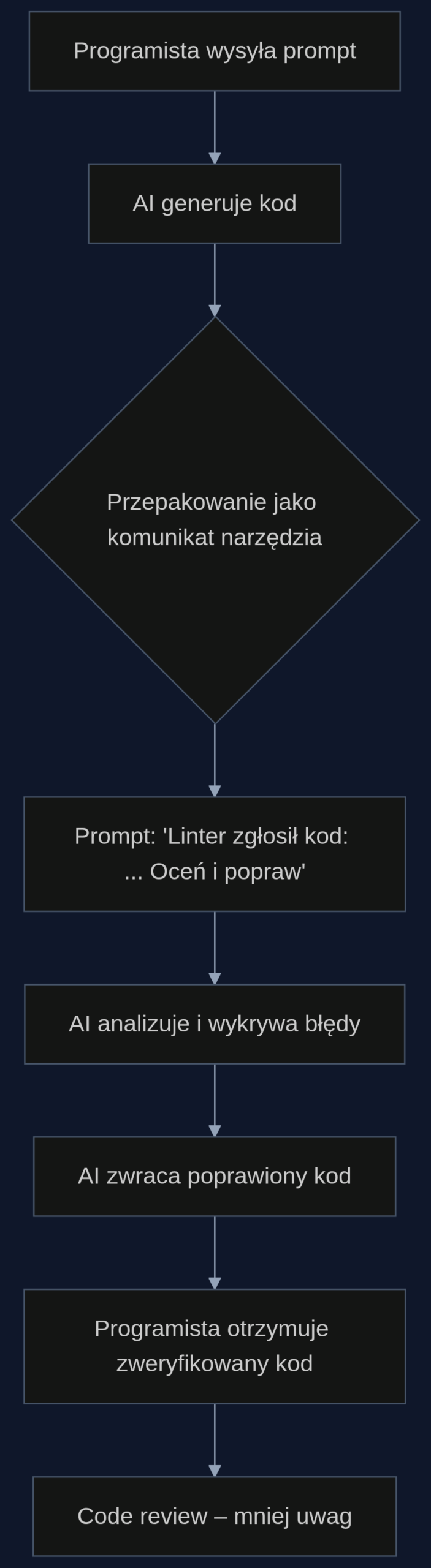
Wykorzystanie tego odkrycia w inżynierii oprogramowania jest banalnie proste. Zamiast zwracać kod wygenerowany przez asystenta bezpośrednio programiście, proces przechwytuje ten kod i opakowuje go jako komunikat zewnętrznego narzędzia. Najlepiej sprawdza się symulowany linter: prompt buduje odpowiedź ‘Linter zgłosił następujący fragment kodu: [tu wstawiamy oryginalną propozycję]. Oceń jego poprawność i popraw błędy’. Model widząc kod jako coś zewnętrznego przechodzi w tryb krytycznej oceny i w większości przypadków znajduje błędy, które sam popełnił chwilę wcześniej.
Co istotne, nie potrzeba do tego żadnego retreningu ani dostępu do wag modelu. Wystarczy 20 linii kodu zaplecza (middleware) integrującego się z dowolnym asystentem AI, takim jak GitHub Copilot, Amazon CodeWhisperer czy wewnętrzny serwer LLM. Cały mechanizm działa jako warstwa postprocessingu przed wyświetleniem wyniku użytkownikowi.
Praktyczny scenariusz i wyniki
Weźmy firmę tworzącą aplikację bankową. Programista prosi asystenta: ‘Napisz funkcję walidującą numer PESEL w Pythonie, uwzględniającą sumę kontrolną i datę urodzenia’. Model generuje kod, który ma trzy błędy: brakuje obsługi przypadku lat przestępnych, pętla nie obsługuje ujemnych indeksów, a zmienna pomocnicza nie jest inicjalizowana. Zamiast pokazać ten fragment programiście, system w tle przepakowuje go jako raport lintera i pyta model: ‘Poniższy kod został zgłoszony przez narzędzie analizy statycznej. Znajdź i popraw wszystkie błędy’. Model analizuje go na nowo, zauważa wszystkie trzy usterki i zwraca poprawioną wersję. Programista dostaje kod prawie produkcyjny, a w code review pojawia się tylko jeden komentarz zamiast pięciu.
W pilotażu przeprowadzonym w 15-osobowym zespole fintechowym, po dodaniu tej warstwy, liczba błędów wykrywanych ręcznie podczas code review spadła o 28% w ciągu miesiąca. Czas przeglądu przypadający na jednego programistę skrócił się średnio o 18 minut dziennie. Przy stawce 70 zł za godzinę daje to oszczędność rzędu 10 500 zł miesięcznie dla całego zespołu. A trudniejsze do wyceny korzyści, jak mniej poprawek po wdrożeniu i mniejsze obciążenie testerów, tylko tę kwotę zwiększają.
Podsumowanie i następne kroki
Opisana technika to nie kolejny hype, tylko sprytny sposób na wyciśnięcie więcej z istniejących modeli. Nie wymaga kupowania nowej subskrypcji ani czekania na GPT-5. Wystarczy zmodyfikować pipeline promptu o dodatkowe opakowanie odpowiedzi w rolę narzędzia. Rekomenduję przetestowanie jej na jednym module przez dwa tygodnie i zmierzenie redukcji błędów przed wdrożeniem w całym zespole. Jeśli wasz code review tonie w drobiazgach z AI, warto poświęcić te 20 linii kodu, by odzyskać godziny tygodniowo.
- Redukcja ręcznego code review o 28 proc.
- Zero kosztów – zmiana w strukturze promptu
- Łatwa integracja z Copilotem i CodeWhisperer
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: The Self-Correction Illusion: LLMs Correct Others but Not Themselves
Autorzy: Kuan-Yen Chen, Fang-Yi Su, Jung-Hsien Chiang
Recent work shows that LLM agents struggle to correct errors in their own reasoning traces yet show markedly higher correction rates when identical claims appear under external sources. We ask whether this asymmetry reflects a capability deficit or a role-label artifact: does an agent’s willingne…
arXiv: arxiv.org/abs/2606.05976
Czytaj więcej o tej technologii: Dlaczego AI wyłapuje cudze błędy, a własne ignoruje
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}