
Mamy do czynienia z czymś w rodzaju ślepoty na własne potknięcia. Ten sam model językowy, który bezbłędnie wytknie pomyłkę w pytaniu użytkownika, przejdzie obojętnie obok identycznego błędu, który sam wygenerował. Nowe badanie pokazuje, że to nie defekt inteligencji, a dziwactwo formy, w jakiej rozmawiamy z modelami.
Ta sama treść, inna etykieta
Wyobraźmy sobie, że dwie osoby mówią dokładnie to samo zdanie. Jedna to nasz szef, a druga to stażysta. Choć słowa są identyczne, reakcja na nie będzie zupełnie inna. Z modelami językowymi jest bardzo podobnie.
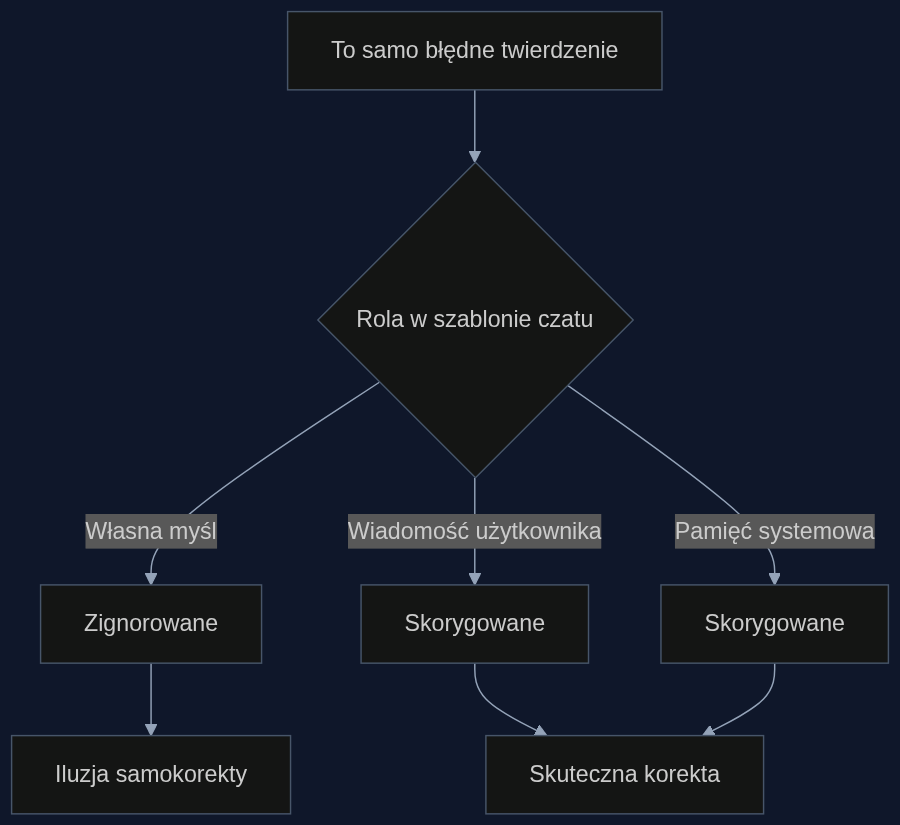
Zespół z Tajwanu postanowił to sprawdzić w kontrolowanym eksperymencie. Użyli identycznej, błędnej treści, co potwierdzili kryptograficznie za pomocą funkcji SHA-256. Jedyną różnicą było to, w jakiej ‘roli’ w szablonie czatu umieszczono fałszywe twierdzenie. Raz było to myśl własna agenta, raz wiadomość od użytkownika, a raz odpowiedź narzędzia.
Różnica okazała się kolosalna, a nie kosmetyczna. Kiedy błąd był opakowany jako własna myśl modelu, ten masowo go ignorował. Gdy tylko zmieniono etykietę na zewnętrzną, ten sam model nagle stawał się niezwykle krytyczny.
Nawet 93 punkty procentowe różnicy
Wyniki są uderzające i nie pozostawiają złudzeń. Zmiana etykiety roli z własnej myśli agenta na rolę zewnętrzną, na przykład wiadomość od użytkownika, podnosiła wskaźnik jawnej korekty błędu o 23 do 93 punktów procentowych. Różnica jest ogromna.
Autorzy nie poprzestali na jednym modelu czy jednym typie zadań. Przetestowali siedem rodzin modeli w trzech różnych domenach: matematyce, dedukcji logicznej i rozumowaniu zdroworozsądkowym. Wynik był stabilny. W 10 z 13 testowanych kombinacji model-domena uzyskano wynik istotny statystycznie z p<0.001. Asymetria jest więc cechą fundamentalną, a nie przypadkową anomalią.
Niezdolność do samodzielnej korekty nie jest deficytem poznawczym; to artefakt szablonu czatu.
Kuan-Yen Chen, Fang-Yi Su, Jung-Hsien Chiang
The Self-Correction Illusion: LLMs Correct Others but Not Themselves
Mechanizm, a nie deficyt
Wniosek z badania jest zaskakująco prosty i przewrotny. Niezdolność modeli do samodzielnej korekty nie wynika z braku wiedzy czy zdolności. To nie jest tak, że model ‘nie wie’ lub ‘nie potrafi’ znaleźć błędu. On po prostu inaczej traktuje treści w zależności od tego, kto jest ich nadawcą.
Mówiąc wprost, to artefakt szablonu czatu, a nie deficyt poznawczy. Model ma wiedzę, by skorygować błąd, ale nie robi tego, gdy uzna, że to jego własna myśl. To tak, jakbyśmy byli bardziej skłonni uwierzyć w cudzą pomyłkę niż przyznać się do własnej. Zdaniem autorów, źródłem problemu nie jest brak inteligencji, lecz specyfika formatu czatu.
Kto mówi, ma znaczenie
Badanie ujawniło jeszcze jedną ciekawą zależność. Nie ma jednej, uniwersalnej ‘najlepszej’ roli, która zawsze wywoła korektę. Optymalne opakowanie błędu zależy od dziedziny.
W zadaniach matematycznych najskuteczniejszy okazał się blok pamięci systemowej. Model traktował go z największą powagą. Z kolei w przypadku dedukcji logicznej, najskuteczniejsze było przedstawienie błędnego twierdzenia jako zwykłej wiadomości od użytkownika. To pokazuje, że mechanizm jest asymetryczny i zniuansowany. Nie wystarczy raz na zawsze zmienić etykietę, trzeba to robić świadomie, w zależności od kontekstu.
Interwencja bez treningu
Być może najbardziej praktyczny wniosek płynący z tego odkrycia jest taki, że można je wykorzystać natychmiast. Nie trzeba ponownie trenować modelu, wydawać fortuny na obliczenia ani modyfikować jego architektury.
Wystarczy zmiana struktury promptu, aby sztucznie przenieść odpowiedzialność za błąd na zewnątrz. W ten sposób, bez ingerencji w ‘mózg’ modelu, można go zmusić do krytycznego spojrzenia na własne wcześniejsze słowa. Zamiast mówić ‘popraw swój błąd’, co nie działa, możemy powiedzieć ‘sprawdź, czy to, co przed chwilą powiedział użytkownik, jest poprawne’. To proste przefrazowanie potrafi zdziałać cuda.
- Model ignoruje błąd jako ‘własną myśl’, ale koryguje go, gdy widzi go jako wiadomość od użytkownika czy systemu.
- Efekt jest masywny i stabilny: wzrost korekty od 23 do 93 punktów procentowych w testach.
- To nie wina ‘inteligencji’ modelu, ale formatu czatu, co otwiera drogę do prostych interwencji bez zmiany modelu.
Praktyczne zastosowania
Aby lepiej zrozumieć opisywaną innowację, przygotowaliśmy cztery przykłady praktycznego zastosowania tej technologii w różnych branżach:




Podsumowanie
Odkrycie to ma znaczenie dla każdego, kto buduje aplikacje oparte na agentach AI. W praktyce, zamiast polegać na tym, że agent sam poprawi swoje błędy, architekt systemu może zaprojektować wewnętrzną ‘pętlę krytyczną’, gdzie agent widzi swoje wcześniejsze odpowiedzi jako pochodzące z zewnętrznego źródła. Ma to bezpośrednie zastosowanie w automatyzacji procesów biznesowych, gdzie agent AI podejmuje decyzje wieloetapowe – w finansach przy analizie ryzyka, w logistyce przy optymalizacji łańcucha dostaw, czy w obsłudze klienta przy rozwiązywaniu złożonych reklamacji. Zamiast trenować lepszy model, można po prostu sprytniej z nim rozmawiać.
Metryka artykułu źródłowego
Tytuł oryginalny: The Self-Correction Illusion: LLMs Correct Others but Not Themselves
Autorzy: Kuan-Yen Chen, Fang-Yi Su, Jung-Hsien Chiang
Data publikacji: 5 czerwca 2026
arXiv: arxiv.org/abs/2606.05976
Napisanie tego artykułu zostało wspomagane przez sztuczną inteligencję. Treść opiera się na oryginalnym artykule naukowym, a jej dokładność została zweryfikowana automatycznie.