
Kiedy aplikacja mobilna z 70 milionami linii kodu wysypuje się użytkownikowi na ekran, inżynierowie spędzają godziny na odtwarzaniu błędu, żeby w ogóle zacząć szukać przyczyny. Zespół z WeChata pokazał system Holmes, który pomija cały ten teatr. Czyta zrzuty rejestrów, logi i ślady stosu zebrane w momencie awarii, a potem w średnio 77 sekund wskazuje winowajcę na poziomie konkretnej funkcji.
Problem, którego nie widać gołym okiem
Wyobraź sobie, że dostajesz raport o awarii z samego rana. Stack trace wskazuje na funkcję w zamkniętym frameworku Androida, do którego nie masz kodu źródłowego. Logi milczą. Żeby odtworzyć błąd, potrzebujesz tego samego modelu telefonu, tej samej wersji systemu i dokładnie takiej samej sekwencji kliknięć, jaką wykonał użytkownik. Powodzenia.
To nie jest rzadki przypadek. W dużych aplikacjach jak WeChat, gdzie kod open-source miesza się z zamkniętymi bibliotekami systemowymi, ślad awarii często urywa się na granicy między światami. Deweloper widzi tylko, że coś poszło nie tak w środku cudzego kodu, i nie ma jak zajrzeć głębiej. Tradycyjne debugery są tutaj ślepe.
Holmes podchodzi do tego inaczej. Zamiast próbować odtworzyć awarię, sięga po dane, które już istnieją: zrzuty rejestrów procesora, kod asemblera wygenerowany przez kompilator, stany wszystkich wątków w momencie kraksy. Te artefakty są brzydkie i niskopoziomowe, ale nie kłamią. Pokazują dokładnie, co procesor miał w rękach, kiedy wszystko się posypało.
Trzy fazy, które zastępują śledczego
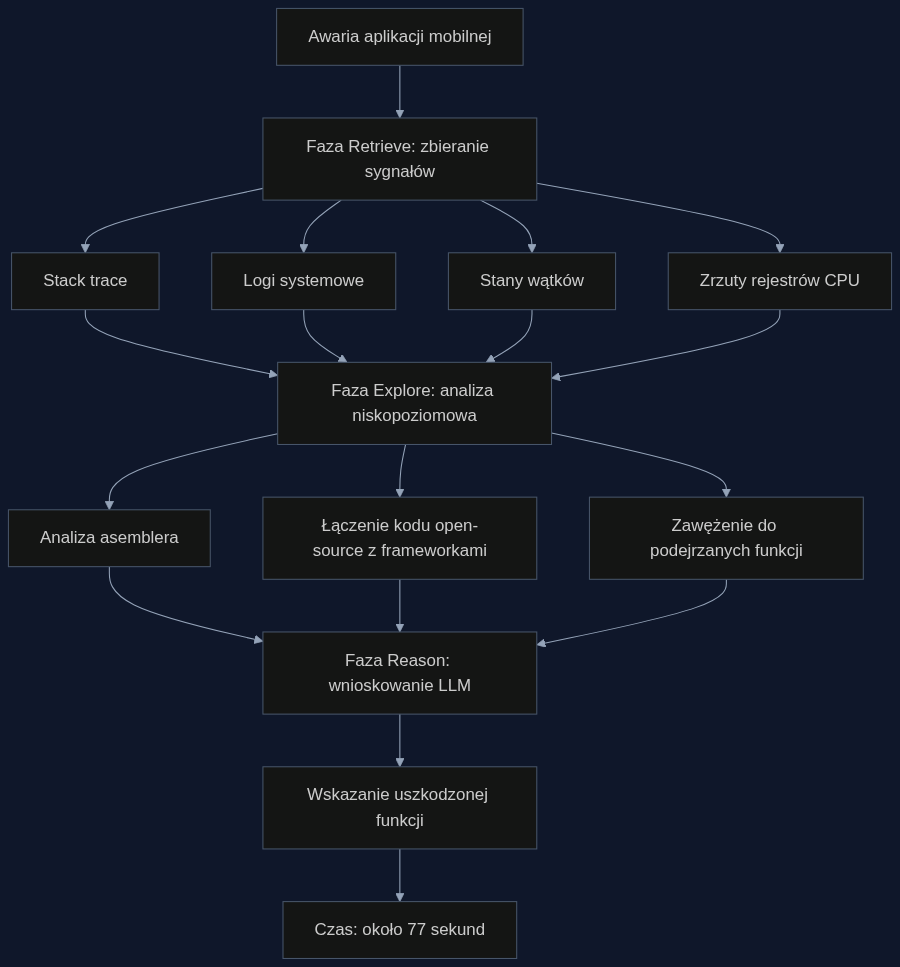
Architektura Holmesa opiera się na pomyśle, który autorzy nazwali Retrieve-Explore-Reason. Za tą nazwą kryje się praktyczny podział pracy między agentami.
W fazie Retrieve agenci zbierają wszystko, co system wyrzucił w momencie awarii. Stack trace to dopiero początek. Dochodzą logi systemowe, stany wątków, zawartość rejestrów CPU. Ten multimodalny zestaw sygnałów daje pełniejszy obraz niż pojedynczy ślad stosu, który zazwyczaj jest jedyną wskazówką dostępną dla człowieka.
Faza Explore to moment, w którym system schodzi na poziom asemblera. Analizuje, co dokładnie robił procesor w momencie awarii, jakie wartości trzymał w rejestrach i jak przepływ sterowania przeskakiwał między funkcjami. Dzięki temu potrafi połączyć kod open-source aplikacji z zamkniętym frameworkiem systemowym, nawet jeśli na poziomie kodu źródłowego nie ma między nimi widocznego mostu. Z 70 milionów linii kodu zawęża pole poszukiwań do garści podejrzanych funkcji. Ostatnia faza, Reason, przekazuje ten zawężony kontekst modelowi LLM, który składa z niego przyczynowo-skutkową historię awarii.
Holmes, wieloagentowy system, który automatyzuje analizę przyczyn źródłowych, syntetyzując multimodalne sygnały środowiska uruchomieniowego – ślady stosu, logi i stany wątków – aby zrekonstruować kontekst awarii bez potrzeby jej odtwarzania.
Jia Li, Wenyuan Ma, Ting Peng, Haibin Zheng, Yuetang Deng
Abstrakt pracy
77 sekund kontra godziny. I to nie jest marketingowy slajd
Autorzy przetestowali Holmesa na rzeczywistych awariach zebranych z produkcyjnej wersji WeChata. Ground truth ustalili na podstawie analiz przeprowadzonych przez doświadczonych inżynierów, którzy spędzili nad każdym przypadkiem godziny. System trafił w uszkodzoną funkcję w 87,6% przypadków.
Średni czas dochodzenia spadł z godzin do około 77 sekund. To redukcja o ponad 98%. Nie chodzi tu o przyspieszenie pisania kodu czy generowanie boilerplate’u, tylko o skrócenie najbardziej frustrującej części pracy inżyniera: siedzenia nad logami o drugiej w nocy i zgadywania, co poszło nie tak.
Jest w tym jednak pewien haczyk. System działa na danych post-mortem, czyli takich, które musi najpierw zebrać. Jeśli mechanizm zbierania zrzutów nie zadziała, Holmes nie ma na czym pracować. Autorzy nie ukrywają tego ograniczenia, ale w praktyce WeChata infrastruktura do zbierania crash logów już istniała. Holmes dostał ją w spadku po poprzednich narzędziach.
Dlaczego asembler wraca do łask
Przez ostatnią dekadę wydawało się, że programiści mogą żyć szczęśliwie, nie zaglądając poniżej warstwy kodu wysokiego poziomu. Abstrakcje miały nas przed tym chronić. Holmes pokazuje, że w diagnostyce awarii asembler i rejestry procesora to jedne z niewielu rzeczy, które nie oszukują.
Kiedy aplikacja napisana w Javie lub Kotlinie wywołuje funkcję z natywnej biblioteki C++, a ta z kolei wpada w zamknięty framework systemowy, żadne narzędzie na poziomie kodu źródłowego nie prześledzi tej ścieżki w całości. Ale procesor nie widzi granic między językami. Wykonuje instrukcje, przesuwa wskaźnik stosu, zapisuje wartości do rejestrów. Holmes czyta właśnie to.
Wcześniejsze próby analizy asemblera w debugowaniu były zbyt kosztowne obliczeniowo i wymagały ręcznej ekspertyzy. Modele LLM obniżyły ten próg: potrafią sensownie interpretować niskopoziomowy bałagan, zamiast zostawiać go wyłącznie inżynierom od bezpieczeństwa i reverse engineeringu.
- 87,6% skuteczności w lokalizacji uszkodzonej funkcji na rzeczywistych awariach z WeChata
- Średni czas diagnostyki spada z godzin do około 77 sekund (redukcja o ponad 98%)
- Architektura Retrieve-Explore-Reason zawęża przestrzeń poszukiwań w 70-milionowych liniach kodu
- Wykorzystanie rejestrów CPU i asemblera pozwala łączyć kod open-source z zamkniętymi frameworkami systemowymi
Praktyczne zastosowania
Aby lepiej zrozumieć opisywaną innowację, przygotowaliśmy cztery przykłady praktycznego zastosowania tej technologii w różnych branżach:




Podsumowanie
Holmes nie jest narzędziem do debugowania w trakcie pisania kodu. Jego miejsce jest w pipeline’ach monitoringu aplikacji mobilnych po stronie producenta. Dla zespołów utrzymujących duże aplikacje z mieszanym kodem (Java, Kotlin, C++, frameworki systemowe) oznacza to automatyzację triażu awarii, która dziś pochłania godziny pracy senior developerów. Drugi obszar to narzędzia DevOps: integracja z systemami raportowania crashy, gdzie Holmes może automatycznie przypisywać awarie do konkretnych funkcji jeszcze zanim człowiek otworzy ticket. Trzeci to platformy mobilne z zamkniętym ekosystemem, gdzie ograniczony dostęp do kodu źródłowego frameworków uniemożliwia tradycyjne debugowanie, a analiza artefaktów niskopoziomowych omija tę barierę.
Metryka artykułu źródłowego
Tytuł oryginalny: Holmes: Multimodal Agentic Diagnosis for Mixed-Language Mobile Crashes at Industrial Scale
Autorzy: Jia Li, Wenyuan Ma, Ting Peng, Haibin Zheng, Yuetang Deng
Data publikacji: 23 czerwca 2026
arXiv: arxiv.org/abs/2606.21963
Napisanie tego artykułu zostało wspomagane przez sztuczną inteligencję. Treść opiera się na oryginalnym artykule naukowym, a jej dokładność została zweryfikowana automatycznie.