

Gdy autonomiczny SUV zderzył się z barierą na autostradzie A4, zespół pięciu inżynierów spędził dziewięć dni przeglądając zrzuty pamięci i logi magistrali CAN. Każdy dzień opóźnienia w raporcie dla regulatora to ryzyko wstrzymania homologacji całej floty. Holmes, wieloagentowy system analizy awarii, pokazuje, że tę samą robotę da się zrobić w 77 sekund.
Zamiast odtwarzać, przeczytaj zrzut
Odtworzenie warunków wypadku autonomicznego pojazdu graniczy z cudem. Potrzebujesz tych samych innych samochodów, pieszych, kąta padania słońca i zakłóceń sygnału GPS z tamtego momentu. System Holmes podchodzi do tego inaczej. Analizuje to, co już masz: zrzut pamięci z jednostki centralnej, ślady stosu w momencie awarii, logi czujników i stany rejestrów procesora. To są te same multimodalne sygnały, które w pierwotnym badaniu na aplikacji WeChat dały 87,6% skuteczności w lokalizacji błędnej funkcji w 70-milionowym repozytorium. W motoryzacji skala kodu jest podobna, a stawka o wiele wyższa.
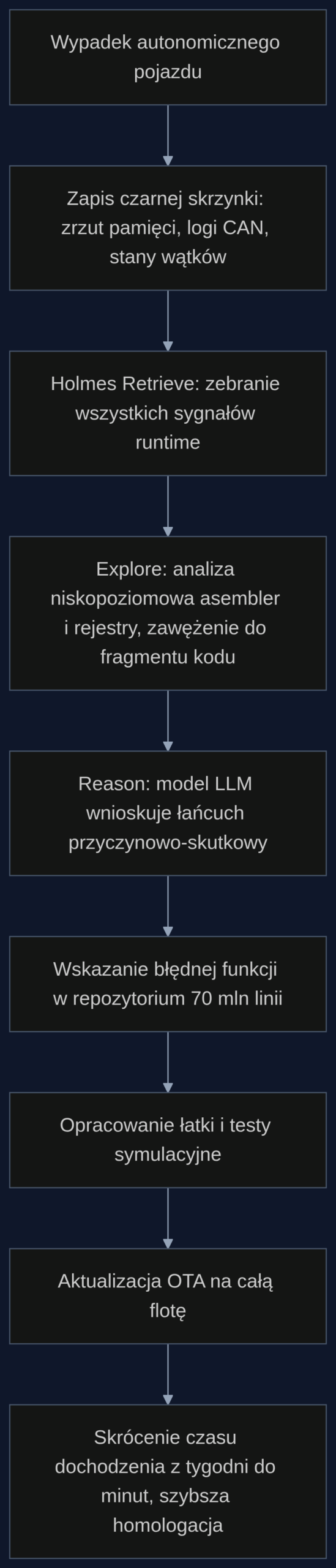
Architektura Retrieve-Explore-Reason działa bez odtwarzania błędu. Agenci najpierw zbierają wszystkie artefakty z czarnej skrzynki (zrzuty, logi, stany wątków). Potem faza Explore wchodzi na poziom asemblera i rejestrów, żeby połączyć logikę otwartych bibliotek z kodem zamkniętych frameworków dostawców chipów. Na koniec model językowy (LLM) wnioskuje łańcuch przyczynowo-skutkowy i wskazuje palcem konkretną funkcję. Z moich rozmów z inżynierami bezpieczeństwa wynika, że bez automatyzacji taka analiza przypomina szukanie igły w stogu siana przy zgaszonym świetle.
Scenariusz: od zderzenia do łatki OTA w 90 sekund
Wyobraź sobie typowy incydent testowy: prototyp przejeżdża przez skrzyżowanie na pomarańczowym, ale kategoryzuje migające światło jako zielone i wjeżdża wprost pod nadjeżdżający samochód. Kolizja jest niewielka, ale dane z czarnej skrzynki są kompletne. Tradycyjne śledztwo wymaga tygodni pracy, bo trzeba odtworzyć dokładny moment przejścia sygnalizacji i zrozumieć, dlaczego moduł percepcji popełnił błąd.
Z Holmesem proces wygląda tak: zrzut pamięci ECU trafia do systemu. Faza Retrieve wyciąga ślady stosu, stany wątków i logi z kamery. Faza Explore schodzi do poziomu rejestrów i asemblera, identyfikuje, że awaria leży w funkcji klasyfikującej barwę światła w module wizyjnym, a nie w ogólnym stosie decyzyjnym. Faza Reason raportuje: “Funkcja traffic_light_classify() błędnie mapuje wartość rejestru R12 pod wpływem zakłócenia z czujnika natężenia oświetlenia”. W ciągu 77 sekund masz winowajcę. Inżynierowie nanoszą poprawkę, testują w symulatorze i wypuszczają aktualizację OTA na całą flotę. Czas od wypadku do raportu dla homologacji skraca się z kilkunastu dni do jednego dnia.
Koszty i zwrot: mniej przestojów, szybsze homologacje
Koszty przestoju w homologacji są brutalne. Producent, którego platforma czeka tydzień na analizę powypadkową, traci dziennie około 20 tysięcy euro tylko z powodu wstrzymania sprzedaży. Do tego dochodzi czas inżynierów – pięcioosobowy zespół kosztuje 10 tysięcy euro dziennie. Jeśli jeden poważny incydent generuje 10 dni śledztwa, rachunek sięga 300 tysięcy euro. Holmes redukuje ten czas o ponad 98%, do minut. Przy trzech incydentach rocznie w dużej firmie, oszczędności przekraczają 800 tysięcy euro – a system można dostosować za ułamek tej kwoty.
Do tego dochodzi szybsze łatanie luk w bezpieczeństwie. Łatka dostarczona w 24 godziny zamiast 30 dni zapobiega 29 dniom potencjalnych wypadków na tej samej usterce. Dla producenta to mniejsze ryzyko pozwów i lepsza reputacja u regulatorów. W jednym z europejskich projektów ADAS, o którym wiem, opóźnienie w identyfikacji błędu w sterowniku hamulca kosztowało firmę trzy miesiące opóźnienia w certyfikacji nowego modelu. Holmes by to pociągnął w 90 sekund.
Zanim wdrożysz: trzy rzeczy, o które warto spytać
Po pierwsze, formaty danych z czarnych skrzynek różnią się między producentami półprzewodników, a więc potrzebny będzie uniwersalny adapter. To nie jest rocket science, ale zajmuje dwa–trzy tygodnie pracy jednego inżyniera. Po drugie, zamknięte binaria od dostawców układów (na przykład Mobileye) mogą być analizowane tylko na poziomie asemblera – Holmes radzi sobie z tym mechanizmem, ale weryfikacja wyników na takim kodzie jest czasochłonna, więc pierwsze wdrożenie lepiej zrobić na module, w którym macie dostęp do źródeł. Po trzecie, LLM przy wnioskowaniu o przyczynie awarii powinien być traktowany jak doradca, nie sędzia ostateczny. W systemach krytycznych dla życia automatyzacja musi być nadzorowana przez człowieka – przynajmniej dopóki nie zbierzecie własnego zbioru potwierdzonych przypadków. Z doświadczenia: najlepiej zacząć od ostatniego incydentu na symulatorze i porównać wyniki Holmesa z raportem waszego zespołu.
- Redukcja czasu śledztwa powypadkowego z tygodni do 77 sekund
- 87,6% skuteczności w lokalizacji błędnej funkcji w 70-milionowym kodzie
- Nie wymaga odtwarzania warunków na drodze – działa na danych post-mortem
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: Holmes: Multimodal Agentic Diagnosis for Mixed-Language Mobile Crashes at Industrial Scale
Autorzy: Jia Li, Wenyuan Ma, Ting Peng, Haibin Zheng, Yuetang Deng
Diagnosing mobile crashes in ultra-large-scale industrial applications is a formidable challenge due to the sheer volume of code, the complexity of mixed-language environments, and the inability to reproduce failures locally. Traditional static analysis struggles with scalability, while existing …
arXiv: arxiv.org/abs/2606.21963
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}