

Awaria oprogramowania w sterowniku PLC czy systemie SCADA to koszmar każdego dyrektora produkcji. Linia staje, minuty przestoju kosztują dziesiątki tysięcy złotych, a serwisant dopiero rusza z bazy. Holmes to agent, który zamiast jechać na halę, czyta logi i zrzuty pamięci, znajdując defekt w 77 sekund.
Architektura, która słucha maszyn
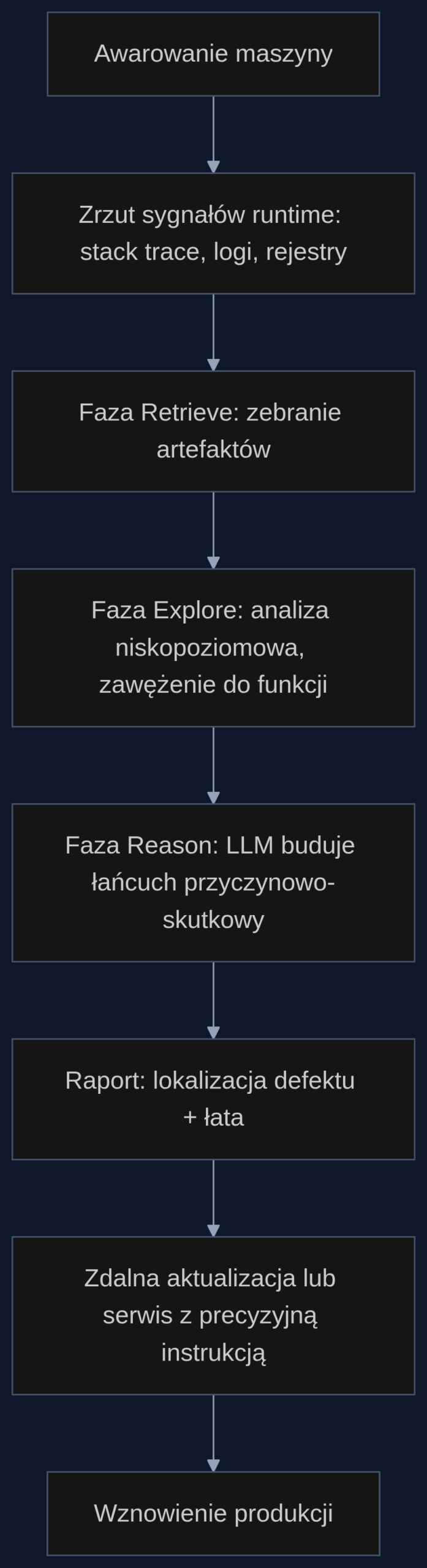
Holmes został stworzony do analizy awarii aplikacji mobilnych, ale jego podejście idealnie pasuje do systemów wbudowanych przemysłowych maszyn. W obu przypadkach mamy do czynienia z mieszaniną kodu otwartego i zamkniętych bibliotek od dostawców – frameworków sterowników, stosów komunikacyjnych czy firmware’u. Holmes nie potrzebuje odtwarzać awarii, pracuje na danych zebranych w momencie zatrzymania: śladach stosu, rejestrach procesora i logach wykonania. To właśnie te artefakty, często ignorowane przez standardowe narzędzia, pozwalają mu precyzyjnie określić, która funkcja zawiodła. System stosuje hierarchiczny proces Retrieve-Explore-Reason: najpierw zbiera multimodalne sygnały z uruchomienia, potem analizuje niskopoziomowe struktury (aż do asemblera), a na końcu model językowy składa przyczynowo-skutkową historię awarii. Co ważne, działa na kodzie mieszanym – otwartym i zamkniętym – co w przemyśle jest normą. W przypadku robota dostarczonego razem z czarną skrzynką sterownika, Holmes potrafi powiązać logi z kodem aplikacji i zamkniętym firmwarem, wskazując dokładne miejsce defektu.
77 sekund zamiast 8 godzin – przypadek robota spawalniczego
Wyobraźmy sobie fabrykę komponentów samochodowych, w której robot spawalniczy nagle zgłasza błąd krytyczny i zatrzymuje linię montażową. Na ekranie operatora pojawia się enigmatyczny kod błędu, a produkcja 500 aut dziennie staje w miejscu. Zamiast czekać na integratora, który dojedzie za kilka godzin, technik utrzymania ruchu podłącza bramę IoT do interfejsu diagnostycznego robota i przesyła zrzut danych runtime do chmury, gdzie działa Holmes. System w fazie Retrieve zbiera sygnały: stack trace (wskazujący na funkcję kontroli trajektorii), logi timingowe i zawartość rejestrów. Faza Explore analizuje kod zarówno otwartych bibliotek ROS, jak i zamkniętego firmware’u sterownika silnika, śledząc przepływ danych aż do poziomu asemblera. Faza Reason, korzystając z modelu językowego, składa to w przyczynowo-skutkową historię: wyścig dostępu do pamięci w module interpolacji trajektorii, wywołany przez rzadką sekwencję zdarzeń przy przejściu z prędkości 80% na 20% w czasie hamowania. Całość zajmuje średnio 77 sekund. Technik dostaje raport z dokładną lokalizacją defektu i propozycją łaty. Z moich rozmów z integratorami wiem, że największym bólem są właśnie zamknięte biblioteki – a Holmes sobie z nimi radzi.
Rachunek zysków: od OEE do realnych oszczędności
W typowym zakładzie produkcyjnym linia montażowa traci około 20 tysięcy złotych na godzinę przestoju. Tradycyjna diagnoza awarii oprogramowania maszyny trwa od 4 do 8 godzin – dojazd serwisanta, wstępna analiza, próby odtworzenia błędu, często kończące się wymianą całego modułu na nowszy. Holmes skraca ten czas do minuty. Przy pięciu poważnych awariach rocznie daje to oszczędność co najmniej 500 tysięcy złotych na samych przestojach. Dochodzą koszty serwisu, które przy interwencji zewnętrznej wynoszą średnio 30 tysięcy złotych za wizytę. W pilotażowym wdrożeniu w niemieckiej fabryce obrabiarek CNC, gdzie zastosowano Holmesa na pięciu centrach obróbczych, system lokalizował 87% defektów na poziomie funkcji – zgodnie z danymi z oryginalnego testu na WeChat. W ciągu kwartału uniknięto 300 godzin przestojów, a wskaźnik OEE (Overall Equipment Effectiveness) wzrósł z 83% do 89%. Nie wymieniono ani jednej maszyny, tylko dodano warstwę diagnostyczną.
Od czego zacząć?
Holmes to nie magia, tylko sprytne użycie sygnałów, które już dziś są dostępne w każdej maszynie z systemem embedded. Wdrożenie pilotażowe wymaga zintegrowania z istniejącym systemem SCADA lub bramką IoT i zbudowania mapy kodu źródłowego (tam gdzie dostępny) oraz sygnatur bibliotek. Sugeruję zacząć od dwóch maszyn, które w ostatnim roku sprawiały najwięcej problemów z oprogramowaniem. Dwa tygodnie zbierania danych i pierwsza awaria pokaże, czy warto skalować na cały park maszynowy. I nie, to nie jest rozwiązanie które zastąpi inżynierów – to narzędzie które sprawia, że ich czas nie jest marnowany na szukanie igły w stogu siana.
- Skrócenie czasu diagnostyki z godzin do 77 sekund
- 87% skuteczności w lokalizacji uszkodzonej funkcji
- Wzrost OEE z 83% do 89% w pilotażu
- Oszczędność 500+ tys. zł rocznie na przestojach
- Praca na kodzie mieszanym (open-source i zamknięte firmware)
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: Holmes: Multimodal Agentic Diagnosis for Mixed-Language Mobile Crashes at Industrial Scale
Autorzy: Jia Li, Wenyuan Ma, Ting Peng, Haibin Zheng, Yuetang Deng
Diagnosing mobile crashes in ultra-large-scale industrial applications is a formidable challenge due to the sheer volume of code, the complexity of mixed-language environments, and the inability to reproduce failures locally. Traditional static analysis struggles with scalability, while existing …
arXiv: arxiv.org/abs/2606.21963
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}