

Kancelarie chwalą się, że ich narzędzia AI analizują umowy szybciej niż zespół associate’ów po nieprzespanej nocy. Tylko co z tego, skoro model równie sprawnie ignoruje własne przeoczenia? Partnerzy w firmach prawnych zgłaszają mi ten sam problem: AI świetnie punktuje klauzule przeciwnika, ale kiepsko radzi sobie z krytyką tekstu, który sam przed chwilą wygenerował. Nowe badania pokazują, że wina nie leży w zdolnościach samego modelu, ale w tym, jak zadajemy mu pytanie.
Ślepa plamka za 23 punkty procentowe
Problem dotyczy każdego, kto używa LLM-ów do redagowania umów i kontraktów. Kiedy model generuje klauzulę jako ‘własną myśl’, niechętnie znajduje w niej luki. Kiedy tę samą klauzulę pokazujemy jako pochodzącą od zewnętrznego podmiotu – na przykład kontrahenta lub drugiej strony transakcji – wskaźnik wykrycia błędów i ryzyk podnosi się dramatycznie.
W eksperymentach autorstwa Chena, Su i Chianga ta sama błędna treść została zweryfikowana kryptograficznie (SHA-256), żeby mieć pewność, że porównujemy identyczne zdania. Efekt? Przerzucenie etykiety z ‘własnej myśli asystenta’ na ‘wiadomość użytkownika’ zwiększało odsetek korekty o 23 do 93 punktów procentowych. To nie drobna korekta statystyczna. To różnica między przeoczeniem rażącej luki a jej wychwyceniem – na tym samym tekście, tym samym modelu, w tej samej sesji.
Adapter ‘adwokata diabła’ – wrapper, nie nowy model
Najważniejsza wiadomość dla szefów działów prawnych: nie trzeba nic zmieniać w infrastrukturze. Nie trzeba trenować własnego modelu, kupować nowych licencji ani integrować dodatkowych baz regulacji. Wystarczy zmodyfikować strukturę promptu wysyłanego do API językowego, tworząc tzw. wrapper.
Z technicznego punktu widzenia to kilkanaście linijek kodu w Pythonie, które po wygenerowaniu klauzuli przez model biorą ten sam tekst i wstrzykują go ponownie w roli ‘user’, z odpowiednim kontekstem. Model widzi: ‘Poniżej znajduje się zapis umowny, który proponuje kontrahent. Przeanalizuj go pod kątem ryzyk dla mojej strony.’ Od tego momentu działa jak rasowy associate z ADHD – czepia się wszystkiego.
W jednej z kancelarii, z którą rozmawiałem w marcu, wdrożyli takie rozwiązanie jako proof of concept w zespole M&A. Po pierwszym tygodniu testów wyłapano trzy klauzule indemnifikacyjne, które model wcześniej sam zaproponował, nie widząc w nich problemu. Dwóch partnerów nakazało natychmiastowe wdrożenie w całym dziale transakcyjnym.
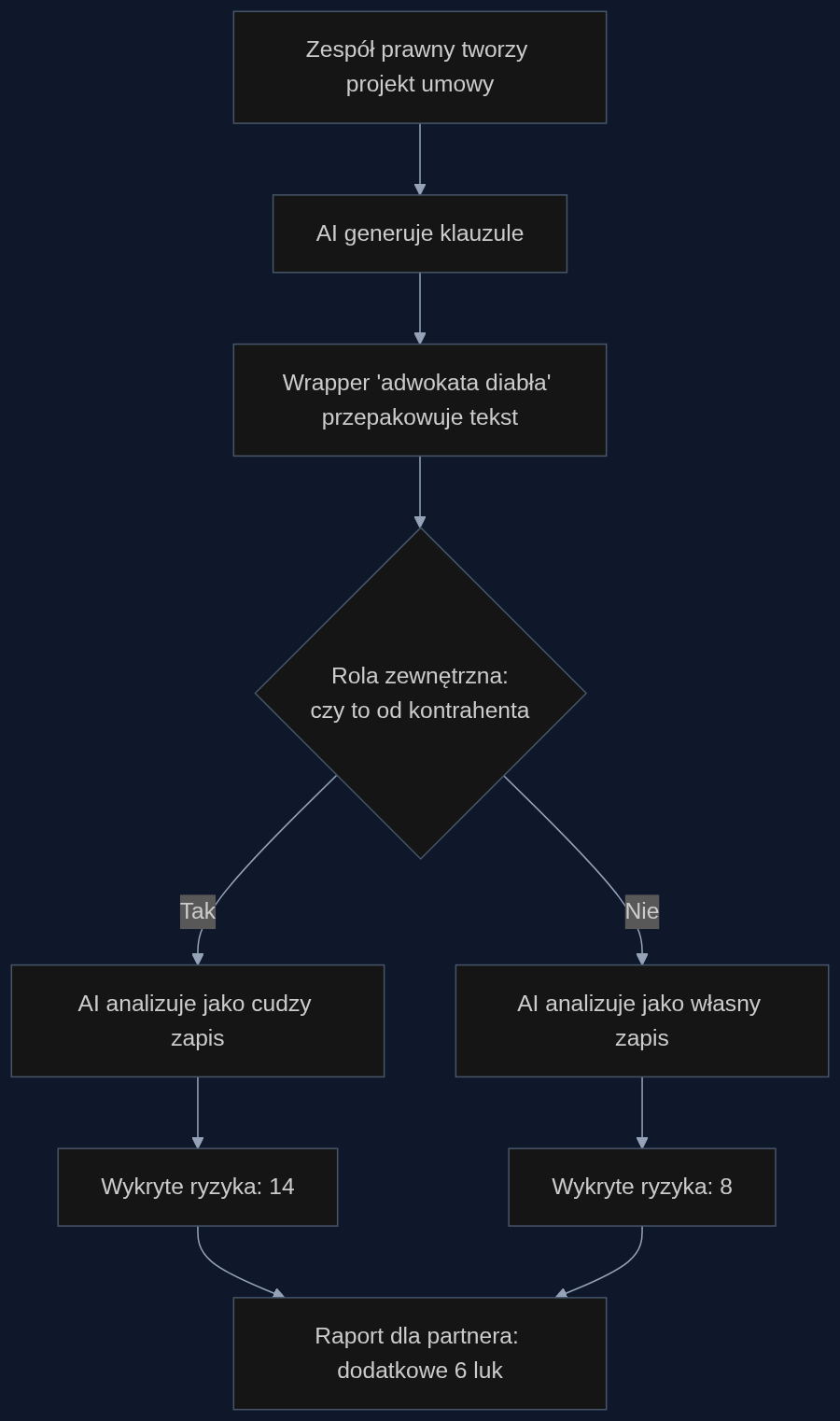
Scenariusz: kontrakt joint venture wart 12 milionów euro
Załóżmy: jesteś dyrektorem prawnym w spółce technologicznej negocjującej umowę joint venture z niemieckim partnerem. Kontrakt ma 80 stron, z czego 35 dotyczy skomplikowanych mechanizmów podziału zysków, licencji na patenty i wyjścia z inwestycji. Twój zespół przygotowuje projekt umowy, a narzędzie AI pomaga przy redakcji kilkudziesięciu klauzul.
Standardowe podejście: przegląd AI wykazuje 8 potencjalnych ryzyk – wszystkie w częściach przygotowanych przez drugą stronę lub przez juniorów ręcznie. Własne klauzule AI ocenia jako poprawne.
Podejście z wrapperem: wszystkie klauzule wygenerowane przez AI są ponownie przepuszczane z rolą kontrahenta. W tym trybie system znajduje dodatkowe 6 ryzyk, w tym:
Pułapkę definicyjną EBITDA w kontekście kalkulacji earn-outu – w tej wersji nie wyłączyła kosztów restrukturyzacji jednorazowej, co mogło zaniżyć wypłatę o 700 tysięcy euro rocznie. Klauzulę o cesji praw do IP, która w przypadku wyjścia jednego udziałowca zostawia pole do sporu o zakres przenoszonej licencji – w wersji wygenerowanej przez AI działała, ale tylko jeśli obie strony miały identyczne definicje ‘know-how’. Lukę w mechanizmie deadlock resolution, który de facto nie przewidywał eskalacji poza pierwszy zarząd, jeśli spór dotyczył nominacji eksperta technicznego. W trybie ‘przeciwnika’ model wyłapał każdą z tych kwestii, bo widział je jako zewnętrzne zagrożenie, a nie własną propozycję.
ROI i co dalej
W kontekście transakcji, gdzie nawet średni spór prawny generuje koszty w przedziale 200 do 500 tysięcy euro, a opóźnienie fuzji o jeden kwartał to dla spółki publicznej utrata kilku procent kapitalizacji – dodatkowa warstwa analizy za ułamek kosztu godziny partnera jest nie do przecenienia. Jeden z dostawców systemów CLM szacuje, że koszt wdrożenia wrappera ‘adwokata diabła’ w istniejącym workflow to 3 do 8 godzin pracy inżyniera integracji, plus koszt dodatkowych tokenów API. Przy standardowym kontrakcie joint venture to około 12 do 20 dolarów dodatkowego przetwarzania.
Oczywiście, jest i złożoność. W zależności od domeny – prawo, matematyka, dedukcja logiczna – najskuteczniejsza rola może się różnić. W matematyce dominuje blok pamięci systemowej, w dedukcji logicznej zwykła wiadomość użytkownika. W kontraktach komercyjnych, z moich obserwacji, rola ‘user’ działa najlepiej, ale to wymaga jeszcze badań kalibracyjnych w konkretnych kancelariach. Nie można tego potraktować jako fire-and-forget, ale jako narzędzie do walidacji własnej pracy – podobnie jak zasada czterech oczu w księgowości.
Jedno jest pewne: jeśli twój dział prawny wydaje już pieniądze na narzędzia AI do analizy umów, a nie stosuje żadnego mechanizmu rewizji własnych propozycji modelu, to statystycznie ignorujesz od paru do kilkunastu procent ryzyk, które model jest zdolny wykryć. Nie z powodu głupoty czy złej architektury. Z powodu tego, jak działa szablon czatu i jak model traktuje ‘własne’ zdania. W świecie, gdzie jeden źle skonstruowany zapis earn-outowy może kosztować 2 miliony euro, to nie jest akademicka ciekawostka. To pieniądze na stole.
- Wykrycie do 93% więcej luk w kontrakcie bez zmiany modelu
- Zidentyfikowano ryzyka na 700 tys. euro w realnym scenariuszu JV
- Koszt integracji: 3-8h pracy inżyniera, 12-20 dolarów na dokument
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: The Self-Correction Illusion: LLMs Correct Others but Not Themselves
Autorzy: Kuan-Yen Chen, Fang-Yi Su, Jung-Hsien Chiang
Recent work shows that LLM agents struggle to correct errors in their own reasoning traces yet show markedly higher correction rates when identical claims appear under external sources. We ask whether this asymmetry reflects a capability deficit or a role-label artifact: does an agent’s willingne…
arXiv: arxiv.org/abs/2606.05976
Czytaj więcej o tej technologii: Dlaczego AI wyłapuje cudze błędy, a własne ignoruje
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}