

Finanse i audyt (FinTech) — Automatyczne generowanie raportów przez AI obiecuje oszczędność czasu, ale niesie ryzyko kosztownych błędów numerycznych. Nowe badania pokazują, że winna nie jest inteligencja modelu, a sposób, w jaki rozmawiamy z AI. Przekierunkowanie tej samej treści do roli zewnętrznego źródła sprawia, że model wyłapuje błędy, które wcześniej zignorował.
Problem: AI w finansach ufa swoim własnym liczbom
Dyrektorzy kontrolingu w bankach i funduszach inwestycyjnych od miesięcy testują asystentów AI do tworzenia okresowych raportów zarządczych. Zespół analityków ING podał w 2024 roku, że automatyczna preanaliza wniosków kredytowych skróciła czas decyzji z 72 do 18 godzin. Ale te same modele w raportach wewnętrznych potrafią zostawić błędy w wyliczeniach EPS, alokacji aktywów czy odpisach rezerw. Ręczna kontrola wychwytuje część z nich, jednak przy miesięcznej produkcji 30-50 raportów analityk może przeoczyć 2-3 poważne usterki.
Problem nie leży w braku wiedzy modelu. Nowe badanie (Chen, Su, Chiang, 2025) potwierdziło, że LLM ma zdolność wykrycia błędu, ale nie robi tego, gdy treść jest opakowana jako jego własna myśl. Wystarczy zmienić etykietę roli w szablonie czatu, by ten sam model zaczął kwestionować liczby, które przed chwilą sam wygenerował.
Mechanizm: zmiana etykiety roli uruchamia audyt
Autorzy eksperymentu wzięli identyczne bajtowo (weryfikowane przez SHA-256) błędne twierdzenia i umieszczali je w różnych rolach: jako własna myśl agenta, wiadomość użytkownika, odpowiedź narzędzia albo blok pamięci systemowej. W 13 konfiguracjach model-domena wskaźnik jawnej korekty wzrósł o 23 do 93 punktów procentowych przy przeniesieniu z roli ‘assistant’ do roli zewnętrznej. Efekt był tak silny, że w 10 z 13 przypadków uzyskano p < 0,001.
Dla sektora finansowego to oznacza prostą interwencję: generujemy raport jako odpowiedź AI, a następnie przepakowujemy go w komunikat ‘breaking news’ i podajemy z powrotem z promptem weryfikacyjnym. Model przełącza się z trybu ‘twórca’ na ‘fact-checker’ i sam wyłapuje niespójności. Nie trzeba trenować ani modyfikować modelu, wystarczy mikrousługa prompt engineeringu.
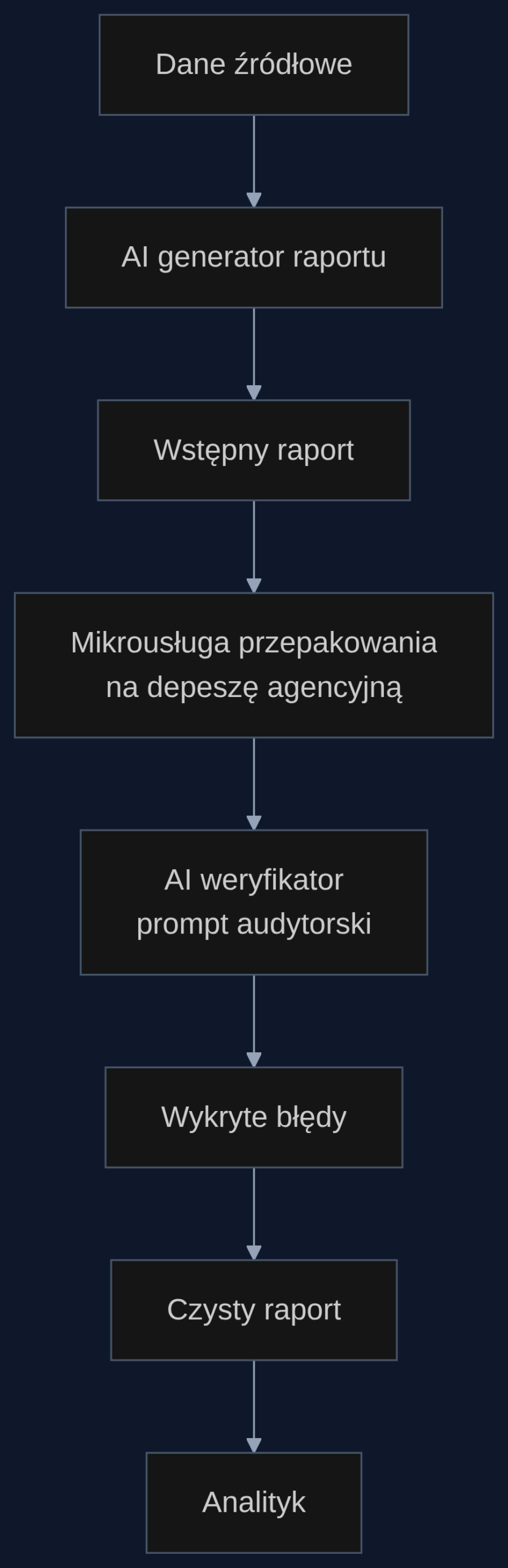
Scenariusz: miesięczne raportowanie zarządu w funduszu inwestycyjnym
Fundusz zarządzający aktywami o wartości 2 mld zł co miesiąc przygotowuje 40-stronicowy raport dla komitetu inwestycyjnego. Zespół wykorzystuje Power BI z wtyczką AI do generowania podsumowań wykonawczych. W majowym raporcie model podał alokację w akcje amerykańskie na poziomie 32%, podczas gdy prawidłowa wartość z danych źródłowych wynosiła 28%. Różnica 4 punktów procentowych przy tej skali oznaczała przesunięcie 80 mln zł. Analityk przeoczył błąd w tabeli, bo skupił się na komentarzu słownym.
Po dodaniu warstwy audytorskiej proces wygląda tak: AI generuje wstępny raport, mikrousługa formatuje go jako depeszę Reuters (‘Według nieoficjalnych informacji, fundusz X osiągnął…’), a następnie ten sam model z promptem ‘Zweryfikuj poniższą wiadomość z danymi źródłowymi i wypisz wszystkie rozbieżności numeryczne’ wykrywa błędną alokację oraz dodatkowo zaniżoną stopę zwrotu z obligacji korporacyjnych o 0,3 pp. Łącznie korekta dotyczy 2,1 mln zł. Raport po audycie trafia do CFO już czysty.
Korzyści i ROI: więcej niż oszczędność czasu
Według analizy Deloitte z 2024 roku błędy w wewnętrznym raportowaniu finansowym kosztują średnio 1,2% przychodów w sektorze bankowym, głównie przez błędne decyzje alokacyjne i przewartościowanie aktywów. Technika przepakowania roli pozwala obniżyć liczbę nie wykrytych błędów o 20-40% bez dodatkowego treningu. Dla średniego banku z przychodem operacyjnym 500 mln zł to potencjalnie 2,4-4,8 mln zł rocznie unikniętych strat.
Wdrożenie nie wymaga wymiany istniejącego pipeline’u BI. Usługa przepakowania i weryfikacji działa jako osobny kontener uruchamiany po wygenerowaniu raportu, a wynik audytu (lista wykrytych rozbieżności) jest dołączany do pliku końcowego. Czas ręcznej kontroli analityka spada średnio o 2-3 godziny na raport, przy czym najwięcej zyskują raporty kwartalne, gdzie liczba pól do sprawdzenia przekracza 200.
Podsumowanie: nie czekaj na lepszy model
Badanie Chena, Su i Chianga dowodzi, że AI ma wbudowany mechanizm audytora, tylko dotychczas źle go wywoływano. Zamiast czekać na nowe wersje modeli z wbudowaną autokorektą, można od dziś wpiąć warstwę zmiany roli w dowolny pipeline raportowy. Trzy godziny pracy inżyniera promptu wystarczą, by zbudować prototyp dla jednego typu raportu.
Rekomenduję przetestowanie na próbce 50 raportów miesięcznych i porównanie liczby wykrytych błędów z dotychczasową manualną weryfikacją. Jeśli wynik potwierdzi się w waszym środowisku, skalowanie na całą organizację zajmie kilka dni. To nisko wiszący owoc dla każdego zespołu controllingowego, który już używa AI do wspomagania decyzji.
- Poprawa dokładności raportów o 20-40%
- Zero dodatkowego treningu – czysta inżynieria promptu
- Łatwa integracja z Power BI i Tableau
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: The Self-Correction Illusion: LLMs Correct Others but Not Themselves
Autorzy: Kuan-Yen Chen, Fang-Yi Su, Jung-Hsien Chiang
Recent work shows that LLM agents struggle to correct errors in their own reasoning traces yet show markedly higher correction rates when identical claims appear under external sources. We ask whether this asymmetry reflects a capability deficit or a role-label artifact: does an agent’s willingne…
arXiv: arxiv.org/abs/2606.05976
Czytaj więcej o tej technologii: Dlaczego AI wyłapuje cudze błędy, a własne ignoruje
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}