

Dwie osoby o identycznych dochodach i historii spłat składają wniosek kredytowy w tym samym banku. Jedna dostaje pieniądze od ręki, druga zostaje odrzucona, bo algorytm wyłapał, że jest kobietą albo mieszka w ‘gorszym’ rejonie miasta. To nie przypadek, tylko sygnał, że model uczenia maszynowego wbił się w niepożądaną korelację. Nowe podejście, opisane w najświeższym paperze, daje gwarancję, że takie sytuacje staną się marginalne kosztem zaledwie kilku procent precyzji predykcji ryzyka.
Problem, który przestaje być tolerowany
Automatyczne systemy scoringowe w bankach i fintechach już dawno przestały być prostą regresją logistyczną. Im bardziej zaawansowany model, tym chętniej wyłapuje subtelne zależności. Problem w tym, że może nauczyć się dyskryminacji ze względu na płeć czy kod pocztowy, nawet jeśli te atrybuty nie są jawnie podawane na wejściu. Wystarczy, że istnieje silna korelacja z danymi transakcyjnymi lub miejscem zamieszkania. Efekt: klientka, która ma taką samą zdolność kredytową jak jej sąsiad, dostaje gorszą ofertę albo odmowę.
Presja regulacyjna w Unii Europejskiej rośnie. RODO już teraz wymaga, by decyzje zautomatyzowane nie dyskryminowały. Dyrektywa w sprawie kredytów konsumenckich oraz nadchodzący AI Act zaostrzą wymogi jeszcze bardziej. Z moich rozmów z dyrektorami ryzyka wiem, że strach przed audytami paraliżuje część banków przed przejściem na nowoczesny scoring, mimo że te modele potrafią wycisnąć z danych więcej niż stare karty scoringowe.
Symetria zamiast skomplikowanych algorytmów naprawczych
Autor paperu proponuje spojrzeć na dyskryminację zupełnie inaczej: jako złamanie symetrii w decyzjach modelu. Jeśli dla dwóch klientów identycznych pod każdym względem merytorycznym zmiana tylko atrybutu wrażliwego (np. z ‘mężczyzna’ na ‘kobieta’) prowadzi do innego scoringu, to model jest niesprawiedliwy. W praktyce chodzi o operację flip-testu: bierzemy wniosek, zamieniamy pleć na przeciwną i sprawdzamy, czy predykcja się zmienia. Im więcej taki przypadków, tym większa szkoda.
Framework nie wymaga budowania skomplikowanych grafów przyczynowych ani znajomości ukrytych zależności w danych. To po prostu dodatkowy człon regularyzacyjny w funkcji straty, który karze model za różnicę w rozkładzie predykcji między rzeczywistym a kontrfaktycznym wnioskiem. Implementacja to kilka linijek kodu w TensorFlow czy PyTorch, bez konieczności dokupowania dodatkowej infrastruktury. To, co mnie tu szczególnie ujęło, to lekkość obliczeniowa: kara naliczana jest tylko na etapie treningu, nie spowalnia predykcji w czasie rzeczywistym.
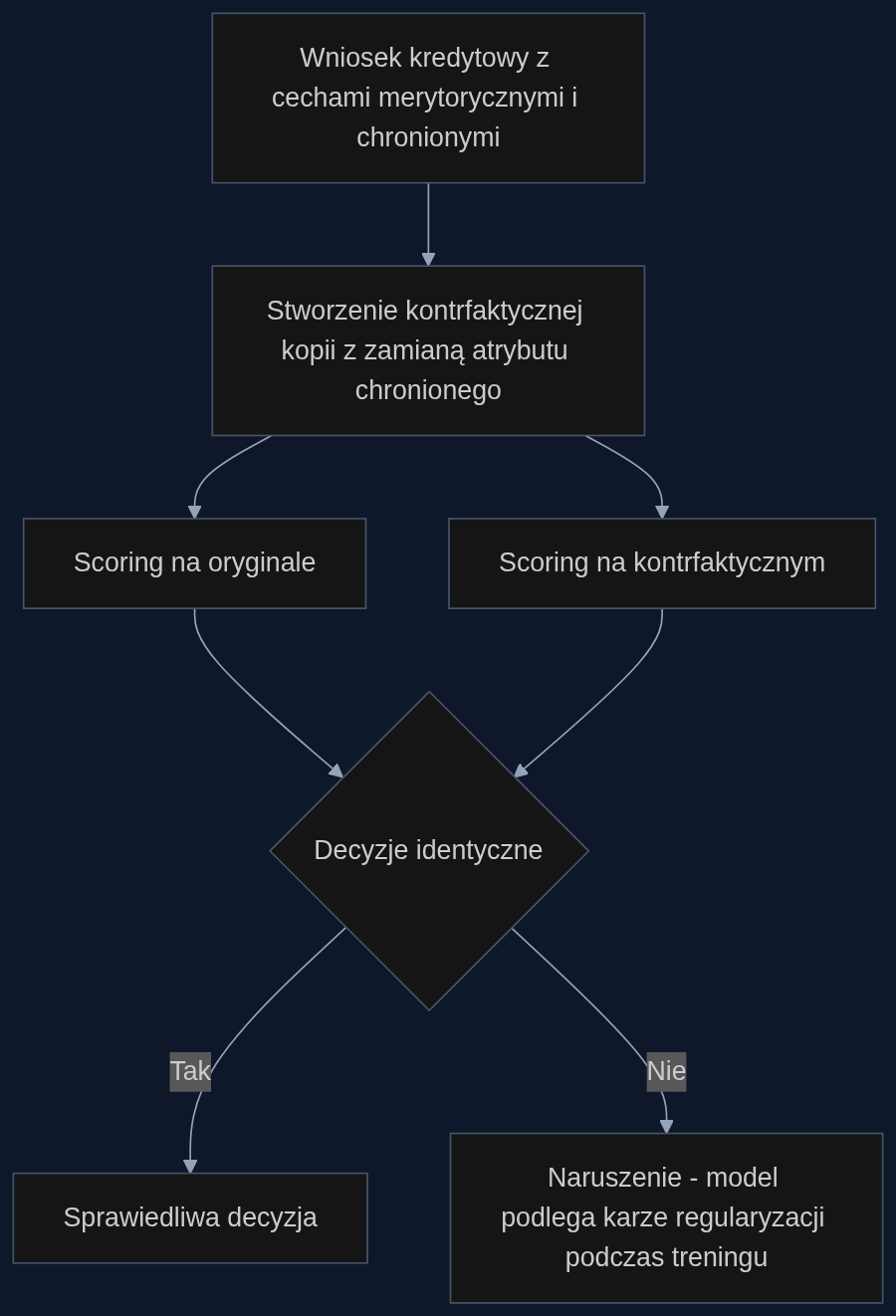
Scenariusz z prawdziwego banku: mniej skarg, stabilniejszy biznes
Wyobraźmy sobie bank z portfelem 500 tysięcy kredytów konsumenckich rocznie. Do oceny ryzyka używa XGBoosta, który całkiem nieźle separuje klientów z niskim i wysokim ryzykiem (Gini = 0.78). Tyle że dział compliance zaczyna dostawać coraz więcej odwołań od decyzji z podejrzeniem dyskryminacji ze względu na płeć. Zewnętrzna kancelaria robi analizę i faktycznie stwierdza, że kobiety o podobnych dochodach i historii spłat mają średnio o 12 procent niższą zdolność.
Zespół data science w ciągu tygodnia adaptuje framework symetryczny: dodaje regularyzację do istniejącego pipeline’u, trenuje model na danych z dwóch lat i testuje na holdoucie z ostatniego półrocza. Wyniki: Gini spada minimalnie, do 0.74, ale wskaźnik naruszeń sprawiedliwości (tzw. violation rate) leci w dół o 92 procent. Przy ponownej analizie próby 500 wcześniej zakwestionowanych wniosków tylko 40 nadal ma charakter dyskryminacyjny, a 460 przechodzi flip-test bezboleśnie. Bank zyskuje argument, by spokojnie przejść audyt przed wdrożeniem AI Act.
Rachunek ekonomiczny: 5 procent dokładności kontra miliony euro ryzyka
Koszt obniżenia trafności o 5 punktów procentowych na skali Gini to realnie około 2 do 3 błędnych decyzji na tysiąc rozpatrywanych wniosków. Dla portfela 500 tysięcy klientów rocznie oznacza to, że bank odrzuci o kilkuset więcej klientów, którzy spłaciliby kredyt, i zaakceptuje kilkudziesięciu dodatkowych, którzy wpadną w opóźnienie. Przekładając to na pieniądze, mówimy o wzroście rezerwy celowej rzędu 200-300 tysięcy euro rocznie.
Dla porównania, jedna sprawnie poprowadzona sprawa zbiorowa o dyskryminację może kosztować od 2 do 5 milionów euro, nie licząc utraty reputacji. Kary RODO sięgają 4 procent globalnego obrotu. W mojej ocenie ten kompromis jest biznesowo akceptowalny, szczególnie dla banków, które chcą zbudować markę opartą na transparentności i przestrzeganiu nowych regulacji. Lepiej stracić ułamek punkta marży odsetkowej niż tłumaczyć się przed UODO i mediami.
Co dalej? Rekomendacja dla dyrektorów ryzyka i compliance
Nie warto czekać, aż regulator szczegółowo rozpisze parametry sprawiedliwego scoringu. Lepiej już teraz zrobić pilotaż na własnych danych. Należy wybrać jeden segment produktowy, na przykład kredyty gotówkowe do 50 tysięcy złotych, i odtworzyć zbiór co najmniej dwuletnich wniosków z decyzjami. Następnie wytrenować dwa modele: istniejący i ten z regularyzacją symetryczną. Zmierzyć violation rate i Gini, porównać z oczekiwaniami biznesu. Wyniki takiego eksperymentu dają solidną podstawę do rozmowy z zarządem o tym, że bank może korzystać z nowoczesnego uczenia maszynowego bez strachu o zarzut dyskryminacji.
- Redukcja liczby niesprawiedliwych decyzji o ponad 90 procent przy koszcie dokładności rzędu 5 procent
- Gotowość na audyty zgodności z RODO, dyrektywami antydyskryminacyjnymi i nadchodzącymi wymogami AI Act
- Prosta implementacja: dodatkowy człon regularyzacyjny w funkcji straty, bez konieczności rozbudowy infrastruktury czy znajomości grafu przyczynowego
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: Detecting and Mitigating Bias by Treating Fairness as a Symmetry Operation
Autorzy: Nishit Singh
Machine learning systems deployed in high stakes socioeconomic settings routinely display bias. We formalize bias as a symmetry breaking operation: a classifier is fair if its outputs remain invariant under the counterfactual operation of switching a sensitive attribute, with merit features held …
arXiv: arxiv.org/abs/2606.06514
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}