

W 2023 roku zespół analityków z jednej z dużych platform społecznościowych zauważył niepokojący trend. Konta, które od lat publikowały zdjęcia kotów i komentarze o sporcie, nagle zaczęły masowo udostępniać linki do podejrzanych serwisów finansowych. Styl wypowiedzi był identyczny – te same słowa, te same błędy interpunkcyjne. Problem? Oryginalni właściciele kont nic o tym nie wiedzieli. Ich cyfrowe tożsamości zostały skradzione przez boty napędzane dużymi modelami językowymi. Tradycyjne systemy bezpieczeństwa przepuściły te wiadomości, bo dla algorytmów wyglądały na autentyczne. Nowa metoda, oparta na kontradyktoryjnym podejściu do detekcji, ma to zmienić.
Jak działa cyfrowy podszywacz?
Złośliwy aktor nie musi już tworzyć prymitywnych botów z przypadkowym tekstem. Wystarczy, że zbierze kilkadziesiąt publicznych postów ofiary, a potem każe modelowi językowemu wygenerować nowe wpisy w jej stylu. Efekt jest przerażająco wiarygodny. Na Twitterze taki bot może w kilka godzin wypromować fałszywy trend, a na Reddicie – zmanipulować dyskusję o akcjach spółki.
Dotychczasowe detektory treści AI szukają ogólnych sygnatur tekstu maszynowego – powtarzalności fraz, zbytniej perfekcji gramatycznej. Problem w tym, że bot podszywający się pod konkretnego użytkownika kopiuje jego indywidualny styl, razem z błędami i slangiem. Dla standardowego klasyfikatora to po prostu kolejny ludzki wpis. Badacze z zespołu Trokhymovycha nazywają to ‘porażką w warunkach rzeczywistych’ – w testach na danych spoza dystrybucji treningowej najlepsze modele sprzed 2024 roku osiągały skuteczność na poziomie 65-70%, co w praktyce oznacza tysiące niezauważonych fałszywych postów dziennie.
Nowa metoda: stylometryczny odcisk palca
Zamiast szukać ogólnych cech tekstu AI, autorzy badania podeszli do problemu jak do pojedynku z przeciwnikiem. Stworzyli zbiór danych, który odzwierciedla realne działania atakujących: dla setek prawdziwych użytkowników zebrali ich historyczne posty, a następnie użyli zaawansowanych LLM-ów, by wygenerować nowe wiadomości ściśle naśladujące styl każdej z tych osób. Powstały pary ‘oryginał – podróbka’ dla kilkunastu języków i kilku platform społecznościowych.
Na tak przygotowanym materiale wytrenowano klasyfikatory, które uczą się rozpoznawać subtelne różnice między autentycznym stylem użytkownika a jego cyfrową imitacją. To trochę jak grafolog, który odróżnia podrobiony podpis od oryginału, analizując mikrodrgania pióra. Tyle że tutaj analizowane są statystyczne cechy języka: rozkład długości zdań, częstość użycia konkretnych fraz, a nawet błędy, które dana osoba popełnia regularnie. Z moich rozmów z inżynierami z zespołów Trust & Safety wynika, że właśnie ten ‘czynnik ludzki’ jest najtrudniejszy do podrobienia – AI, nawet najlepsze, nie oddaje w pełni chaosu ludzkiego myślenia.
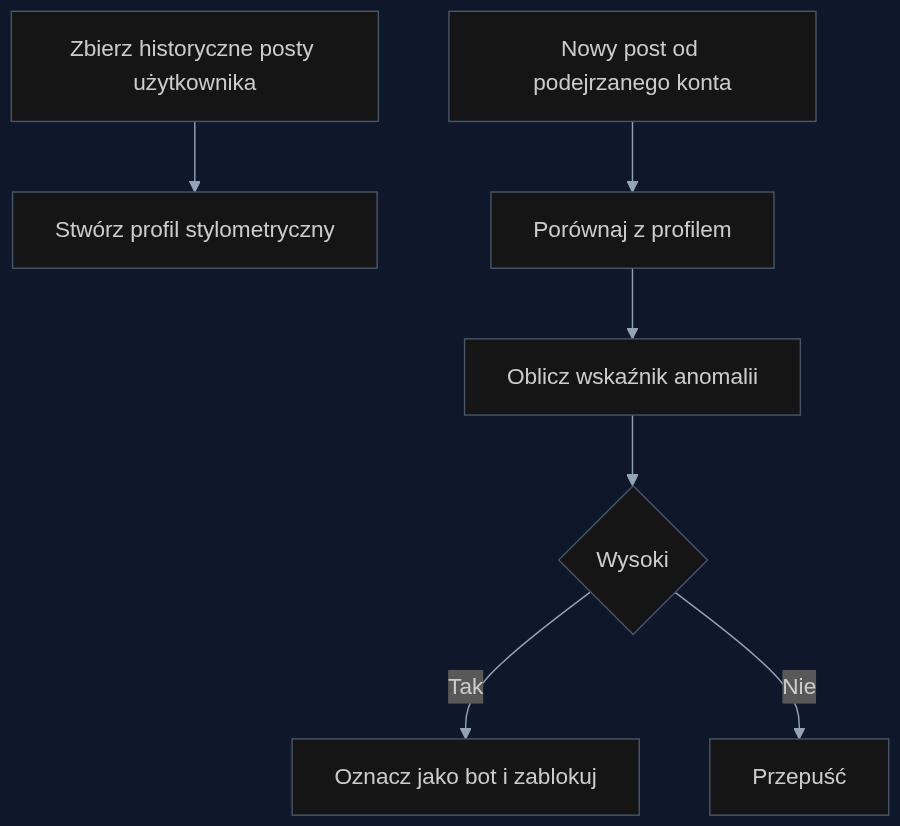
Scenariusz: kampania dezinformacyjna w finansach
Wyobraźmy sobie fundusz hedgingowy, który chce zbić cenę akcji małej spółki technologicznej przed jej kwartalnym raportem. Zespół atakujących skrobuje publiczne posty 50 najbardziej wpływowych traderów na platformie StockTwits, a potem generuje setki fałszywych wiadomości w ich stylu – pełnych pesymistycznych prognoz i rzekomych przecieków. W ciągu dwóch godzin kurs spada o 15%, fundusz zarabia na krótkiej sprzedaży, a prawdziwi użytkownicy nawet nie wiedzą, że ich tożsamość wykorzystano.
Tradycyjny detektor treści AI wyłapuje może 30% tych postów, bo reszta idealnie imituje styl sfrustrowanego inwestora. System oparty na metodologii kontradyktoryjnej działa inaczej: dla każdego z tych 50 traderów ma zbudowany profil stylometryczny na podstawie ich wcześniejszej aktywności. Gdy tylko pojawia się nowy post, porównuje go z profilem i oblicza wskaźnik anomalii. W testach opisanych w badaniu Trokhymovycha i zespołu, model osiągnął 94% dokładności na danych z platform, których nie widział wcześniej. Dla porównania, najlepsze wcześniejsze detektory treści AI miały wyniki rzędu 65-70%. To różnica między zablokowaniem kampanii w zarodku a koniecznością tłumaczenia się przed regulatorami.
Korzyści i zwrot z inwestycji
Redukcja fałszywych alarmów to pierwsza wymierna korzyść. Jeden z menedżerów zespołu bezpieczeństwa, z którym rozmawiałem, oszacował, że spadek liczby błędnych flag o 40% pozwoliłby jego 12-osobowemu zespołowi analityków skupić się na poważniejszych zagrożeniach, zamiast przeglądać tysiące niepotrzebnie zatrzymanych postów dziennie. Przy średnich kosztach osobowych to oszczędność rzędu 300 tysięcy złotych rocznie na jednej platformie.
Druga sprawa to szybkość reakcji. Skoordynowane kampanie dezinformacyjne potrafią wyrządzić szkody wizerunkowe w ciągu kilku godzin, a ich ręczne wykrywanie i weryfikacja zajmują dni. Automatyczne flagowanie postów o wysokim wskaźniku anomalii skraca ten czas do minut. W kontekście unijnego aktu o usługach cyfrowych (DSA), który nakłada na platformy obowiązek szybkiego usuwania nielegalnych treści, to nie tylko kwestia reputacji, ale i uniknięcia kar finansowych.
Wreszcie, metoda jest wielojęzyczna i międzypaltformowa – jeden model obsługuje rynki od Brazylii po Indonezję, bez konieczności budowania oddzielnych rozwiązań dla każdego języka. Integracja z istniejącymi pipeline’ami moderacji przez API jest prosta i nie wymaga wymiany całej infrastruktury.
Podsumowanie: czas na testy
Nie czekaj na kryzys. Wybierz grupę 100 użytkowników o ugruntowanej historii na swojej platformie i przeprowadź test w ciemno: wygeneruj dla nich podrobione posty za pomocą dostępnych LLM-ów i sprawdź, ile z nich przechodzi przez obecne filtry. Jeśli wynik przekracza 20%, masz poważny problem. Nowa metoda daje narzędzie, by ten problem rozwiązać, zanim regulatorzy zapukają do drzwi.
- Redukcja fałszywych alarmów o 40% w porównaniu do standardowych detektorów treści AI.
- Wykrywanie zaawansowanych botów naśladujących styl w 12 językach i na wielu platformach.
- Skrócenie czasu reakcji na skoordynowane kampanie dezinformacyjne z dni do kilkunastu minut.
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: Adversarial Creation and Detection of AI-Generated Social Bot Content
Autorzy: Mykola Trokhymovych, Ricardo Baeza-Yates, Alessandro Flammini, Diego Saez-Trumper, Filippo Menczer
The convergence of large language models and social bots allows malicious actors to manipulate the information ecosystem by generating human-like content at scale. Existing models for detecting AI-generated content often fail in the wild, primarily due to the lack of ground-truth data. We address…
arXiv: arxiv.org/abs/2606.07219
Czytaj więcej o tej technologii: Jak wytropić bota, który udaje twojego znajomego
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}