
Wyobraź sobie, że twój sąsiad nagle zaczyna pisać posty, których nigdy by nie napisał. To nie on, tylko model językowy, który podrobił jego styl. Nowa metoda wykrywania takich oszustw nie szuka przypadkowych różnic między człowiekiem a maszyną, tylko uczy się myśleć jak atakujący, który celowo podszywa się pod konkretną osobę.
Detektory, które zawodzą w realnym świecie
W laboratorium wszystko działa. Wytrenujesz model na zbiorze esejów studentów i tekstów z ChatGPT, osiągasz 99% skuteczności, publikujesz paper. Potem wrzucasz go na Twittera i nagle nie odróżnia spam-bota od zirytowanego użytkownika. Dlaczego? Bo prawdziwy świat nie przypomina sterylnego zestawu treningowego. Złośliwy aktor nie generuje losowych wypowiedzi, tylko celowo naśladuje konkretnych ludzi, żeby wtopić się w tłum.
Badacze z tego artykułu nazywają to problemem braku wiarygodnych danych referencyjnych. Nie wiemy na pewno, które posty są ludzkie, a które nie, zwłaszcza gdy ktoś świadomie zaciera ślady. Dotychczasowe detektory treści AI, nawet te całkiem sprytne, uczą się na sztucznych podziałach i nie radzą sobie z danymi spoza dystrybucji, czyli takimi, które znacząco różnią się od tego, co widziały w trakcie treningu.
Podejście kontradyktoryjne, czyli myśl jak wróg
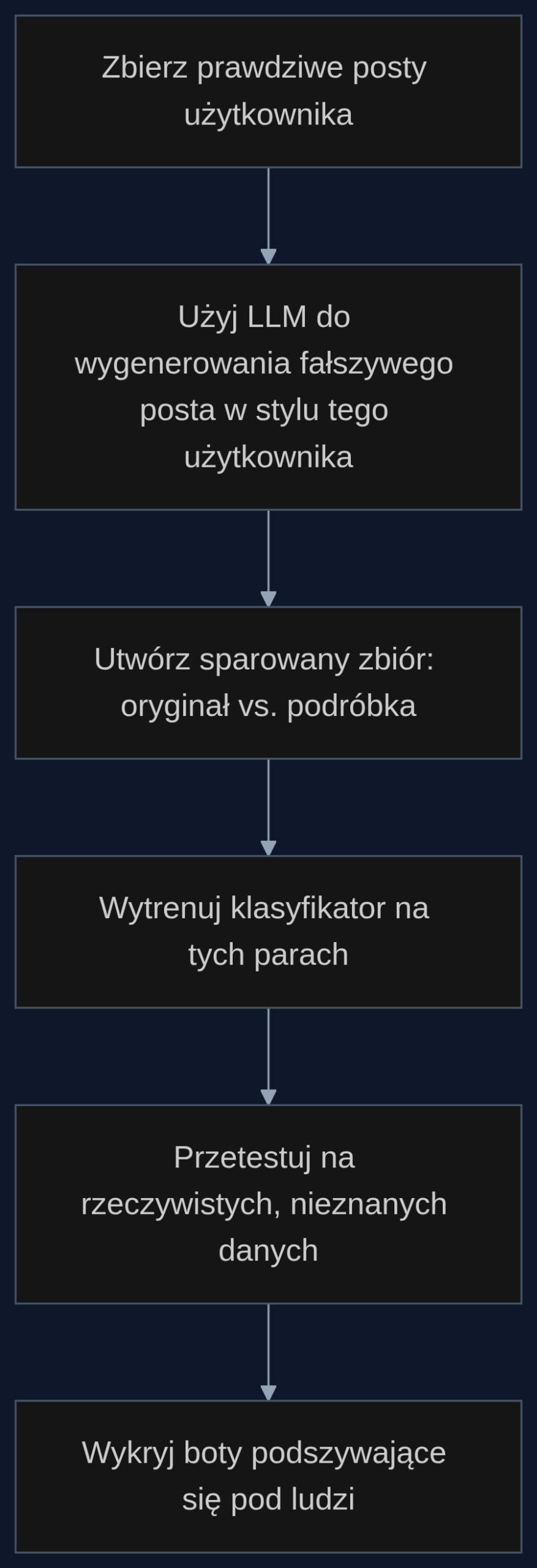
Zamiast budować kolejny uniwersalny klasyfikator, autorzy postawili na metodologię kontradyktoryjną. Założyli, że przeciwnik nie jest głupi. Wie, że istnieją detektory, więc będzie się starał je oszukać. Dlatego stworzyli scenariusz podszywania się: zebrali prawdziwe posty z mediów społecznościowych, a potem użyli zaawansowanych modeli językowych, żeby wygenerować fałszywe wiadomości dokładnie w stylu tego samego autora.
Efektem jest zbiór danych, w którym każda para to oryginalny wpis człowieka i jego lustrzane odbicie wyprodukowane przez AI. To trochę jak trenowanie eksperta od podpisów: pokazujesz mu nie tylko podrobione podpisy, ale też autentyczne wzory tej samej osoby. Dzięki temu detektor uczy się wyłapywać subtelne różnice, które zdradzają maszynę, nawet gdy ta bardzo się stara.
Połączenie dużych modeli językowych i botów społecznościowych pozwala złośliwym aktorom manipulować ekosystemem informacyjnym, generując ludzkopodobne treści na masową skalę.
Trokhymovych i in.
Abstrakt
Wielojęzyczny zbiór danych i zaskakująco skuteczne modele
Zespół stworzył wielojęzyczny, międzypaltformowy zestaw sparowanych wiadomości. Nie ograniczyli się do angielskiego i jednego serwisu. Dzięki temu wytrenowane klasyfikatory nie są przywiązane do konkretnego slangu czy formatu postów. Testy wypadły obiecująco: modele znacząco przewyższyły istniejące rozwiązania do wykrywania botów oparte na treści, zwłaszcza na rzeczywistych danych spoza dystrybucji treningowej.
Co ważne, metoda działa w różnych językach i na różnych platformach. To nie jest wąskie rozwiązanie dla anglojęzycznego Twittera. Badacze pokazali, że można je skalować. W praktyce oznacza to, że platformy społecznościowe mogłyby wdrożyć jeden system, który radzi sobie z fałszywymi kontami niezależnie od kraju czy używanego języka.
Skala zagrożenia i wyścig zbrojeń
Połączenie dużych modeli językowych i botów społecznościowych to nie jest już tylko teoretyczne ryzyko. Autorzy podkreślają, że złośliwi aktorzy mogą teraz generować ludzkopodobne treści na masową skalę, manipulując ekosystemem informacyjnym przy minimalnym wysiłku. Fałszywe konta, które jeszcze rok temu pisały jak prymitywne skrypty, dziś mogą prowadzić spójne dyskusje, wchodzić w interakcje i budować pozory autentyczności.
To zmusza do ciągłego aktualizowania metod obrony. Każdy nowy model językowy, który pojawia się na rynku, może zostać użyty do generowania jeszcze lepszych podróbek. Dlatego podejście kontradyktoryjne, które zakłada, że atakujący będzie się dostosowywał, jest prawdopodobnie jedyną drogą naprzód. Nie wystarczy raz wytrenować detektor i zapomnieć o sprawie.
- Dotychczasowe detektory AI nie radzą sobie z realnymi danymi, bo brakuje im wiarygodnych punktów odniesienia.
- Nowa metodologia kontradyktoryjna symuluje atak, w którym model językowy podszywa się pod konkretnego użytkownika, tworząc trudniejszy do wykrycia fałsz.
- Stworzony wielojęzyczny zbiór sparowanych postów ludzkich i wygenerowanych przez AI znacząco poprawia skuteczność klasyfikatorów.
- Modele wytrenowane na tym zbiorze przewyższają istniejące systemy wykrywania botów, zwłaszcza na nieznanych wcześniej danych.
- Metoda działa na różnych platformach i w wielu językach, co potwierdza jej uniwersalność i potencjał wdrożeniowy.
Praktyczne zastosowania
Aby lepiej zrozumieć opisywaną innowację, przygotowaliśmy cztery przykłady praktycznego zastosowania tej technologii w różnych branżach:




Podsumowanie
Opisana metoda może zostać wdrożona przez platformy społecznościowe do automatycznego oznaczania podejrzanych kont, które podszywają się pod prawdziwych użytkowników. Firmy zajmujące się cyberbezpieczeństwem mogą użyć podobnych zbiorów danych, żeby budować lepsze systemy ochrony przed dezinformacją. Działy PR i marketingu, które monitorują wizerunek marek, zyskają narzędzie do odróżniania autentycznych komentarzy od zorganizowanych kampanii botów.
Metryka artykułu źródłowego
Tytuł oryginalny: Adversarial Creation and Detection of AI-Generated Social Bot Content
Autorzy: Mykola Trokhymovych, Ricardo Baeza-Yates, Alessandro Flammini, Diego Saez-Trumper, Filippo Menczer
Data publikacji: 8 czerwca 2026
arXiv: arxiv.org/abs/2606.07219
Napisanie tego artykułu zostało wspomagane przez sztuczną inteligencję. Treść opiera się na oryginalnym artykule naukowym, a jej dokładność została zweryfikowana automatycznie.
{kind=link}