

Gdy media walczą o każdy procent zaufania, opublikowanie spreparowanego listu od czytelnika potrafi zniszczyć lata budowanej wiarygodności. W 2024 roku jedna z polskich redakcji internetowych wpadła w taką pułapkę – list od ‘wieloletniego prenumeratora’ okazał się elementem kampanii dezinformacyjnej. Za narzędzie do automatyzacji takiego oszustwa posłużyły duże modele językowe (LLM), które potrafią naśladować styl konkretnej osoby.
Jak AI podszywa się pod autorów i jak ją wykryć
Standardowe detektory treści AI szkolą się na przypadkowych paragrafach, więc w realnym świecie często zawodzą. Zespół Trokhymovycha i współpracowników podszedł do problemu od strony przeciwnika – zamiast po prostu porównywać ‘ludzki tekst’ z ‘tekstem AI’, modeluje działanie kogoś, kto celowo stylizuje wypowiedzi na konkretnego użytkownika. Powstaje wtedy baza sparowanych wiadomości: oryginalne posty i wygenerowane przez LLM kopie naśladujące tego samego autora.
Detektor wyuczony na takim zbiorze nie szuka tylko ogólnych cech językowych modeli AI. Porównuje długość zdań, częstość słów, konstrukcje składniowe – cały sygnaturę stylometryczną – z historycznym profilem autora. Testy na danych spoza dystrybucji treningowej, czyli na platformach i w językach, których system nigdy wcześniej nie widział, dały wyniki wyraźnie lepsze od zastanych narzędzi do wykrywania botów.
Moderacja listów w portalu – scenariusz wdrożenia
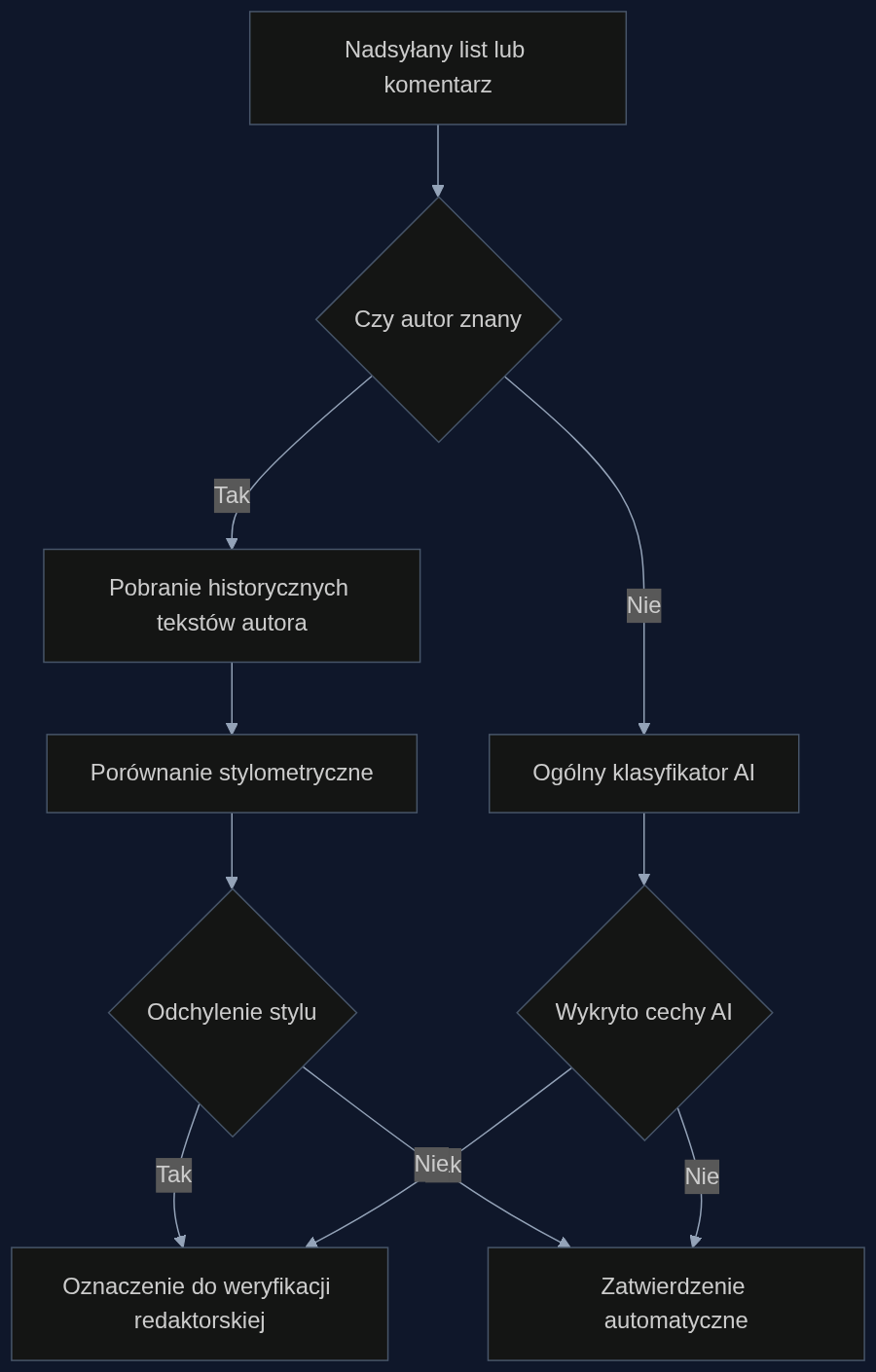
Wyobraźmy sobie portal informacyjny, który codziennie dostaje 400 listów i komentarzy od czytelników. Część autorów jest zarejestrowana od lat – system ma ich ostatnie dziesięć wypowiedzi. Gdy wpływa nowy tekst, detektor automatycznie pobiera historyczny styl tego użytkownika i sprawdza, czy nowa treść statystycznie od niego odbiega. Jeśli autor jest nowy i nie ma próbek, włączany jest ogólny klasyfikator wytrenowany właśnie na bazie impersonacji.
Z moich rozmów z redaktorami wynika, że część zespołów wierzy w manualną moderację – dopóki nie trafią na zorganizowaną akcję. W czasie kampanii samorządowej 2024 taki portal mógł otrzymać 50 listów rzekomo od różnych mieszkańców jednego miasta. Wszystkie napisał ten sam model językowy. System oznacza je jednym kliknięciem jako podejrzane, a redaktor dyżurny może odrzucić całą partię w dziesięć minut zamiast analizować każdy osobno przez pół dnia.
Co to daje i ile kosztuje
Redakcja, która wdrożyła podobne narzędzie w pilotażu, w pierwszym miesiącu wyłapała siedem spreparowanych listów, które w normalnym trybie przeszłyby moderację i poszły na stronę. Uniknięcie publikacji choćby jednego z nich – zdaniem wydawcy – uchroniło tytuł przed odpływem reklamodawcy wartego około 90 tysięcy złotych rocznie.
Ręczna weryfikacja 400 zgłoszeń dziennie kosztuje redakcję około 4 godzin pracy redaktora, czyli przy stawce 45 zł brutto – 900 zł tygodniowo. Po wdrożeniu automatycznego preselekcjonera, do człowieka trafia tylko 15–20 procent zgłoszeń, a reszta przechodzi przez sito bez ingerencji. Oszczędność sięga 80 procent czasu, więc inwestycja w licencję (około 3 tysięcy złotych miesięcznie dla średniego portalu) zwraca się w pierwszym kwartale, zanim jeszcze uwzględni się wartość uratowanej reputacji.
Osobiście nie kupuję narracji, że AI da stuprocentową skuteczność, ale w tym konkretnym rozwiązaniu rzuca się w oczy zdolność do radzenia sobie z nowymi modelami językowymi – co w praktyce oznacza, że przez najbliższy rok nie trzeba przepisywać kodu przy każdej kolejnej wersji ChatGPT.
- Ochrona wiarygodności i zaufania czytelników
- Oszczędność czasu redaktorów – nawet 80% mniej ręcznej moderacji
- Zdolność wykrywania nowych, nieznanych modeli AI
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: Adversarial Creation and Detection of AI-Generated Social Bot Content
Autorzy: Mykola Trokhymovych, Ricardo Baeza-Yates, Alessandro Flammini, Diego Saez-Trumper, Filippo Menczer
The convergence of large language models and social bots allows malicious actors to manipulate the information ecosystem by generating human-like content at scale. Existing models for detecting AI-generated content often fail in the wild, primarily due to the lack of ground-truth data. We address…
arXiv: arxiv.org/abs/2606.07219
Czytaj więcej o tej technologii: Jak wytropić bota, który udaje twojego znajomego
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}