
Sterowanie plazmą w reaktorze fuzyjnym przypomina próbę utrzymania galaretki za pomocą gumek recepturek — jest gorąca, niestabilna i nie znosi błędów. Nowy benchmark RL4F pozwala algorytmom uczyć się tej sztuki na historycznych danych, całkowicie eliminując ryzyko kosztownej katastrofy. Tylko która metoda uczenia radzi sobie najlepiej?
Problem z uczeniem się na żywym reaktorze
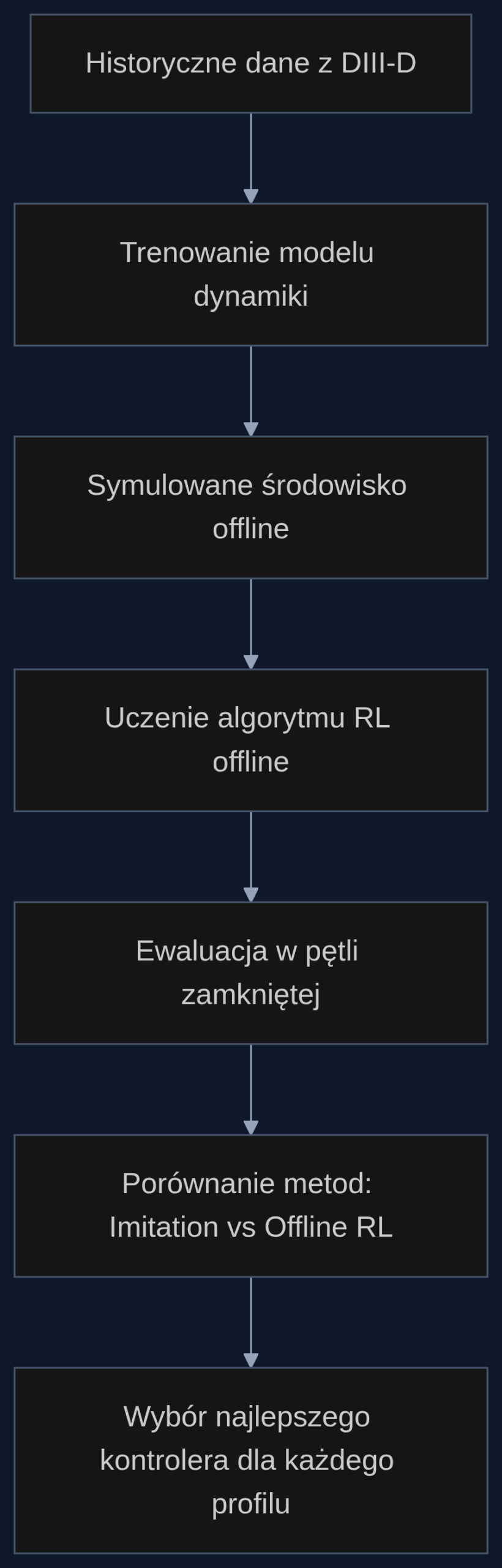
Uczenie maszynowe w kontroli fuzji jądrowej od zawsze stało przed fundamentalnym problemem: jak trenować algorytm, nie topiąc przy okazji reaktora? W tradycyjnym podejściu, znanym jako uczenie przez wzmacnianie online, agent AI uczy się metodą prób i błędów, co w przypadku tokamaka oznacza ryzykowne eksperymenty na urządzeniu wartym miliardy dolarów. Każda nieudana próba może skończyć się niestabilnością plazmy, a w skrajnym przypadku uszkodzeniem ścian komory.
Zespół Yanga Fu z Carnegie Mellon University podszedł do problemu inaczej. Zamiast pozwalać AI eksperymentować na żywym reaktorze, stworzył środowisko testowe, które wiernie symuluje zachowanie plazmy na podstawie historycznych danych z tokamaka DIII-D w San Diego. To trochę jak nauka jazdy na symulatorze, który do złudzenia przypomina prawdziwe auto, zanim wsiądziesz do bolidu F1.
RL4F, czyli cztery zadania dla przyszłych kontrolerów fuzji
Benchmark RL4F (Reinforcement Learning for Fusion) stawia przed algorytmami cztery konkretne wyzwania. Każde z nich to tak zwane śledzenie pełnego profilu, czyli zadanie utrzymania nie tylko średniej wartości parametru, ale całego jego rozkładu przestrzennego wzdłuż promienia plazmy. Wyobraź sobie, że próbujesz jednocześnie kontrolować temperaturę w piekarniku na dziesięciu różnych półkach, z których każda ma własny termostat.
Cztery profile do opanowania to rotacja plazmy, jej gęstość, temperatura oraz ciśnienie. Każde zadanie wymaga od algorytmu innego rodzaju precyzji. Kontrola temperatury może być wybaczająca dla drobnych wahań, ale ciśnienie to zupełnie inna historia: błędy mogą tu szybko eskalować. Benchmark udostępnia dane treningowe, symulator oparty na wyuczonej dynamice oraz zestaw miar ewaluacyjnych, które pozwalają porównać różne podejścia w uczciwy sposób.
Metody offline RL oparte na modelu osiągają najlepszą średnią wydajność w większości zadań, jednak żadna pojedyncza metoda nie dominuje we wszystkich zadaniach, co podkreśla znaczenie modelowania dynamiki w złożonych zadaniach kontroli plazmy o długim horyzoncie czasowym.
Yang Fu, Haomin Bao, Rohit Sonker, Xiaoyan Hu, Aravind Venugopal, Jeff Schneider, Jiayu Chen
RL4F paper abstract
Kto wygrał wyścig? Starcie metod offline
Autorzy przetestowali szeroki wachlarz podejść: od prostego naśladownictwa (uczenia się z demonstracji ekspertów) po zaawansowane metody offline RL. Okazało się, że proste kopiowanie zachowań inżynierów z DIII-D działa zaskakująco dobrze, ale prawdziwą przewagę daje modelowanie dynamiki systemu.
Metody oparte na modelu offline, które najpierw uczą się przewidywać, jak plazma zareaguje na dane sterowanie, a dopiero potem planują działania, osiągnęły najlepszą średnią wydajność w większości zadań. “Metody offline RL oparte na modelu osiągają najlepszą średnią wydajność w większości zadań, jednak żadna pojedyncza metoda nie dominuje we wszystkich czterech zadaniach”, piszą autorzy. To ciekawy wniosek: nie ma jednej idealnej techniki, a wybór metody powinien zależeć od konkretnego profilu plazmy, który chcemy kontrolować.
Dynamika jest kluczem, a diabeł tkwi w szczegółach
Co dokładnie oznacza, że metoda jest oparta na modelu? Wyobraź sobie szachistę, który nie tylko analizuje bieżącą pozycję, ale także myśli kilka ruchów naprzód. Metody model-based offline RL działają podobnie: uczą się dynamiki plazmy na podstawie danych, tworząc wirtualne środowisko, w którym mogą bezpiecznie planować sekwencje działań.
Testy pokazały, że ta zdolność przewidywania jest niezbędna przy zadaniach o długim horyzoncie czasowym. Plazma to system, w którym dzisiejsza decyzja o zmianie pola magnetycznego może mieć konsekwencje dopiero za kilkadziesiąt milisekund. Dla algorytmu bez modelu dynamiki to jak nawigacja we mgle, widzi tylko to, co tu i teraz. Model dynamiki działa jak radar, pokazując nie tylko obecny stan, ale i przewidywane stany przyszłe.
- Benchmark RL4F używa wyłącznie istniejących danych z tokamaka DIII-D, co całkowicie eliminuje ryzyko uszkodzenia reaktora podczas uczenia.
- Testy objęły zarówno proste metody naśladownictwa, jak i zaawansowane algorytmy offline RL oparte na modelu dynamiki.
- Modelowanie dynamiki plazmy okazało się kluczowe przy zadaniach o długim horyzoncie, gdzie algorytm musi przewidywać skutki swoich działań na wiele kroków naprzód.
- Kod, dane i ramy ewaluacyjne udostępniono jako open-source, co pozwala innym zespołom badawczym na niezależne testowanie własnych algorytmów.
Praktyczne zastosowania
Aby lepiej zrozumieć opisywaną innowację, przygotowaliśmy cztery przykłady praktycznego zastosowania tej technologii w różnych branżach:




Podsumowanie
Technologia ta ma bezpośrednie zastosowanie w fuzji jądrowej, szczególnie w projektowaniu kontrolerów dla istniejących tokamaków (DIII-D, JET) i przyszłych reaktorów (ITER, SPARC). Poza fizyką plazmy, architektura RL4F może być adaptowana do sterowania innymi złożonymi systemami fizycznymi, gdzie eksperymenty online są niebezpieczne lub kosztowne, jak autonomiczne pojazdy czy zaawansowane procesy chemiczne. Otwarty kod źródłowy benchmarku przyspieszy rozwój algorytmów offline RL w środowiskach wysokiego ryzyka.
Metryka artykułu źródłowego
Tytuł oryginalny: Offline Reinforcement Learning for Plasma Control in Nuclear Fusion: Codebase and Benchmark
Autorzy: Yang Fu, Haomin Bao, Rohit Sonker, Xiaoyan Hu, Aravind Venugopal, Jeff Schneider, Jiayu Chen
Data publikacji: 9 czerwca 2026
arXiv: arxiv.org/abs/2606.07550
Napisanie tego artykułu zostało wspomagane przez sztuczną inteligencję. Treść opiera się na oryginalnym artykule naukowym, a jej dokładność została zweryfikowana automatycznie.