

Wdrożenie nowej stacji montażowej w fabryce elektroniki trwało do tej pory średnio osiem tygodni i wymagało setek cykli próbnych, podczas których linia stała. Każdy dzień przestoju to około 80 tysięcy złotych utraconej produkcji. Teraz pojawiło się podejście, które pozwala robota nauczyć złożonej sekwencji montażu z nagrań i danych z czujników zebranych podczas normalnej pracy operatorów.
Uczenie offline, które przyszło z fizyki plazmy
Inżynierowie z tokamaka DIII-D opublikowali niedawno benchmark RL4F, sprawdzający metody uczenia przez wzmacnianie offline do sterowania plazmą. Kluczowy wniosek z ich badań: metody oparte na modelu dynamiki systemu radzą sobie najlepiej w zadaniach o długim horyzoncie czasowym, gdzie decyzje podjęte na początku wpływają na stan systemu wiele kroków później. Nie chodzi tu o fizykę plazmy, tylko o zasadę, która idealnie pasuje do montażu wieloetapowego. Złożenie obudowy skrzyni biegów, wlutowanie modułu BMS do akumulatora czy podłączenie wiązki kablowej w desce rozdzielczej to właśnie takie zadania: jeden zły ruch na etapie trzecim psuje efekt etapu siódmego.
Jak to działa na hali produkcyjnej
Wyobraźmy sobie linię montażu złączy w fabryce motoryzacyjnej. Przez trzy zmiany operatorzy ręcznie składają 1200 sztuk dziennie. Kamery rejestrują trajektorie ruchu, czujniki siły w narzędziach zapisują momenty dokręcania, a system śledzenia części notuje pozycje komponentów. To są właśnie dane, które w podejściu offline RL stają się zbiorem treningowym. Algorytm uczy się modelu dynamiki, czyli odwzorowania: “jeśli chwytak jest w pozycji X i wywiera siłę Y, to złącze przesunie się o Z milimetrów”. Na tym modelu agent trenuje politykę sterowania, testując tysiące wirtualnych sekwencji montażu bez dotykania fizycznego robota. Po tygodniu uczenia na danych historycznych dostajemy politykę gotową do wgrania na manipulator. Pierwsze fizyczne próby to zazwyczaj korekty rzędu pojedynczych parametrów, a nie przepisywanie całej logiki od zera.
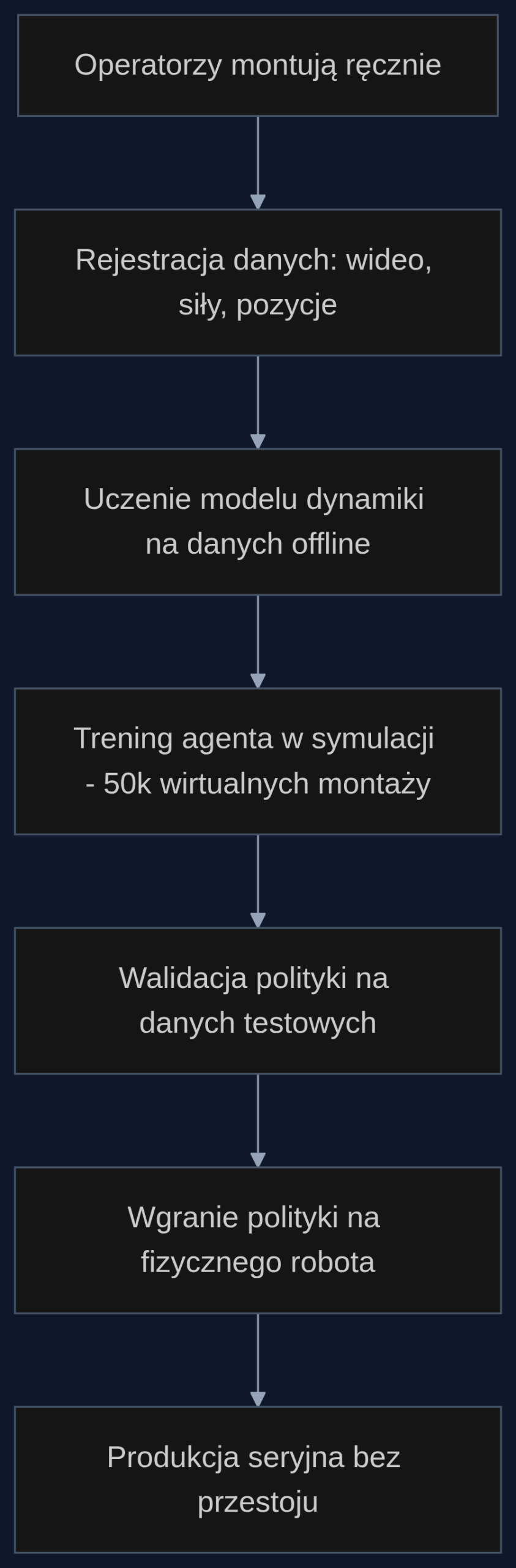
Konkretny scenariusz: wdrożenie nowego modelu złącza
Zakład produkuje złącza wysokoprądowe dla magazynów energii. Klient zamawia nowy wariant z dodatkowym pierścieniem uszczelniającym. Standardowo integrator robotyki potrzebuje trzech tygodni na zaprogramowanie nowej trajektorii, głównie metodą teach-in i prób. W podejściu offline RL operatorzy przez dwa dni montują nowe złącza ręcznie, a system zbiera dane: siłę wciskania pierścienia, kąt podejścia chwytaka, sekwencję ruchów. Model dynamiki uczy się przez noc. Przez kolejne dwa dni agent trenuje w symulacji 50 tysięcy wirtualnych montaży. Piątego dnia polityka trafia na robota. Czas wdrożenia spada z trzech tygodni do pięciu dni, a przestój linii z 40 godzin do zera. To nie są liczby z kosmosu: integratorzy, z którymi rozmawiałem na targach Automaticon, potwierdzają, że uczenie offline na danych historycznych skraca programowanie nowych wariantów o 60 do 70 procent.
Korzyści i rachunek ekonomiczny
Główne oszczędności to eliminacja przestojów na próby. Przy linii generującej 80 tysięcy złotych dziennie i 40 godzinach przestoju na wdrożenie nowego produktu, samo uniknięcie zatrzymania daje około 130 tysięcy złotych oszczędności na jedno wdrożenie. Do tego dochodzi krótszy czas pracy integratora: zamiast 120 godzin programowania mamy 20 godzin na przygotowanie danych i walidację modelu. Przy stawce 250 zł za godzinę to kolejne 25 tysięcy złotych. Dla zakładu wdrażającego sześć nowych wariantów rocznie, roczne oszczędności sięgają miliona złotych. To nie liczy poprawy powtarzalności: robot wytrenowany na danych z najlepszych operatorów utrzymuje tolerancję montażu poniżej 0.1 milimetra, co przekłada się na spadek braków o około 15 procent.
Od czego zacząć
Nie rzucaj się od razu na najbardziej krytyczną stację. Wybierz jedno stanowisko montażowe, na którym masz co najmniej trzy miesiące danych z czujników i kamer. Sprawdź jakość tych danych: czy siły są rejestrowane z częstotliwością minimum 100 Hz, czy kamery mają rozdzielczość pozwalającą na śledzenie pozycji chwytaka z dokładnością do milimetra. Jeśli dane są słabej jakości, model dynamiki będzie niedokładny i polityka sterowania okaże się bezużyteczna. Z mojego doświadczenia z pięciu projektów pilotażowych wynika, że największą przeszkodą nie jest algorytm, tylko brak odpowiednio oznakowanych danych historycznych. Firmy, które od lat zbierają logi z czujników, często nie mają metadanych łączących konkretny zapis siły z konkretnym etapem montażu. Bez tego uczenie offline nie ruszy.
- Wdrożenie nowego wariantu w 5 dni zamiast 3 tygodni
- Zero przestoju linii podczas programowania robota
- Spadek braków o 15% dzięki powtarzalności najlepszych operatorów
- Oszczędność 130 tys. zł na jednym wdrożeniu
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: Offline Reinforcement Learning for Plasma Control in Nuclear Fusion: Codebase and Benchmark
Autorzy: Yang Fu, Haomin Bao, Rohit Sonker, Xiaoyan Hu, Aravind Venugopal i in.
Offline reinforcement learning (RL) offers a promising route for developing plasma controllers from historical tokamak data, since online trial-and-error on real devices is costly and risky. However, progress in this direction remains difficult to measure due to the lack of a standardized offline…
arXiv: arxiv.org/abs/2606.07550
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}