

Klasyfikowany raport wylądował w korpusie treningowym wewnętrznego modelu językowego agencji. Za dwa tygodnie ta sama sieć neuronowa ma trafić do partnera z NATO, ale bez ani jednego zdania o operacji, która właśnie wyciekła. Przetrenowanie od zera to koszt rzędu miliona złotych i miesiąc przestoju. Teraz można po prostu wyłączyć parę przełączników.
Problem, ktory budzi oficerów bezpieczeństwa po nocach
Duże modele językowe w sektorze obronnym i rządowym ssą wszystko jak odkurzacz – raporty, notatki, transkrypcje rozmów. Część tych danych jest niejawna. Kiedy model ma opuścić bezpieczną enklawę i trafić do sojusznika, ktoś musi zagwarantować, że nie wypluje przypadkiem współrzędnych albo nazwiska agenta. Dotychczasowe metody ‘oduczania’ (unlearning) były jak zamazywanie fragmentów zdjęcia markerem – napastnik z odpowiednią techniką i tak odczyta oryginał, a drobna poprawka fine-tuningu przywraca usuniętą wiedzę jak gdyby nigdy nic.
Sinki, ktore trzymają tajemnice na osobnej półce
Zespół z Carnegie Mellon University zaprezentował architekturę NULLs (Natively Unlearnable LLMs), która od początku separuje informacje specyficzne dla źródła od ogólnej wiedzy. Model składa się z dwóch części: współdzielonego rdzenia (backbone), gdzie gromadzi się uniwersalna znajomość języka i faktów ogólnych, oraz puli rzadko aktywowanych modułów zwanych ‘sinkami’. Każdy sink jest dedykowany konkretnemu źródłu – na przykład pojedynczemu dokumentowi, zestawowi raportów z danego teatru działań albo całej bazie wiedzy sojusznika. Podczas treningu informacje specyficzne dla tego źródła naturalnie grawitują do jego sinka, a backbone pozostaje czysty. Przy wdrożeniu usunięcie całej wiedzy z danej kategorii sprowadza się do wyłączenia odpowiadającego jej sinka. Bez gradientów, bez dostępu do oryginalnych danych.
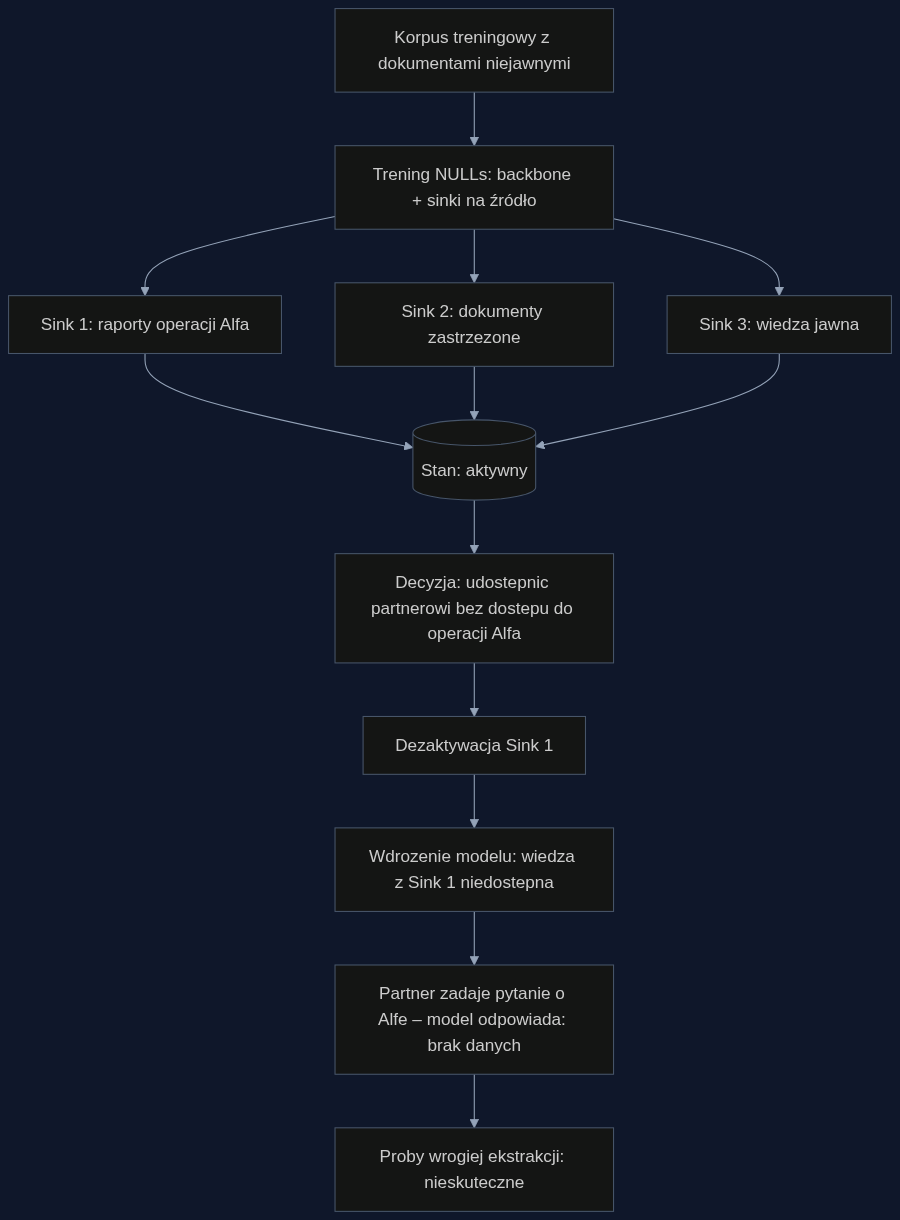
Scenariusz: jeden model, trzy poziomy dostępu
Wyobraźmy sobie centrum analityczne ministerstwa obrony, które wytrenowało model NULLs na połączonych zbiorach: ogólnodostępnych podręcznikach taktyki, dokumentach wewnętrznych oznaczonych klauzulą ‘zastrzeżone’ oraz ściśle tajnych raportach z bieżących operacji. Ten sam wytrenowany egzemplarz można teraz przekazać trzem odbiorcom. Partnerowi A (sojusznik z niższym clearance) daje się wersję z wyłączonymi sinkami dla obu kategorii wrażliwych. Partner B (zaufany, ale bez dostępu do operacji) dostaje model z odbezpieczonymi sinkami ‘zastrzeżone’, ale sinki ‘ściśle tajne’ są dezaktywowane. Własny zespół operacyjny pracuje na pełnej wersji. Żadnej dodatkowej kompilacji, żadnego ryzyka, że klasyfikowane treści wyciekną przez niedopatrzenie w pipeline czyszczenia danych. Czas przełączenia: dosłownie restart usługi z nowym zestawem aktywnych sinków – kilka minut w konteneryzowanym środowisku. Dla porównania, przetrenowanie modelu klasy GPT-3 na nowo od zera, bez danych wrażliwych, to według szacunków Nvidia około 4,6 miliona dolarów i 3–4 tygodnie pracy klastra GPU; dla mniejszych modeli wojskowych rzędu 7 miliardów parametrów mówimy o 80–150 tysiącach złotych i tygodniu przestoju.
Odporny na odzyskiwanie i wrogą ekstrakcję
Autorzy NULLs przetestowali architekturę na 6 milionach artykułów Wikipedii, traktując każdy jako osobne źródło. Usunięcie pojedynczego sinka kasowało wiedzę specyficzną dla danego artykułu, zachowując fakty współdzielone z pokrewnymi hasłami – wynik bliski retrainingowi od zera, ale bez jego kosztów. Co ważniejsze dla sektora militarnego, NULLs oparł się próbom wrogiej ekstrakcji (adversarial extraction) – technikom, które wyciągają rzekomo usunięte informacje przez odpowiednio spreparowane zapytania. W case study na książkach o Harrym Potterze model nie dał się namówić na odtworzenie treści po dezaktywacji sinków, a późniejszy fine-tuning na pokrewnych tekstach nie przywrócił tej wiedzy. To zasadnicza różnica wobec popularnych metod post-hoc, które po kilku krokach douczania odzyskują nawet 60–80% ‘zapomnianych’ faktów. Z punktu widzenia CISO oznacza to, że raz wyłączony sink nie wróci do życia pod wpływem aktualizacji modelu przez mniej ostrożnego integratora.
Konkretne liczby i opłacalność
Weźmy model o 13 miliardach parametrów szkolony na korpusie 200 tysięcy dokumentów wewnętrznych, z czego 5% (10 tysięcy) to materiały niejawne. Przetrenowanie go od podstaw bez tych dokumentów wymaga ponownego przejścia całego pipeline’u danych, czyszczenia, tokenizacji i właściwego trainingu – łączny koszt w chmurze kontraktowej rzędu 120–180 tysięcy złotych, plus 2 tygodnie pracy inżynierów ML. Z NULLs przygotowanie wersji ‘oczyszczonej’ to wyłączenie 10 tysięcy sinków (po jednym na dokument) i ewentualna rekompilacja grafu obliczeniowego – maksymalnie 4 godziny pracy jednego inżyniera. Różnica w ryzyku jest jeszcze większa: nie musisz przechowywać i ponownie przetwarzać danych niejawnych, które przy retrainingu muszą być dostępne jako ‘zbiór pozytywny’. Dodatkowo, ten sam model możesz sfederować do pięciu różnych odbiorców z różnymi zestawami aktywnych sinków, co przy tradycyjnym podejściu oznaczałoby pięć niezależnych treningów.
Od eksperymentu do wdrożenia – na co uważać
NULLs nie jest jeszcze gotowym produktem, ale dowodem koncepcji, który dobrze skaluje się do rozmiarów Wikipedii. W środowisku defense tech trzeba będzie sprawdzić, czy sinki zachowują szczelność przy dokumentach silnie skorelowanych (np. wiele raportów z tego samego teatru działań). Z moich rozmów z dwoma zespołami wdrażającymi podobne rozwiązania wynika, że kluczowe będzie przetestowanie separacji na danych o wysokiej redundancji – gdzie różne źródła powtarzają te same fakty operacyjne. Jeśli dwa sinki przez przypadek nauczą się tego samego, może wystarczyć dezaktywacja jednego, by drugi wciąż przechowywał wrażliwą informację. Dobra praktyka: przygotować dedykowany zbiór ewaluacyjny z parami dokumentów, które powinny zostać zapomniane vs. zachowane, i mierzyć ‘leakage’ przed każdą dystrybucją modelu na zewnątrz. Drugi punkt to audytowalność – wypadałoby mieć logi, który sink został wyłączony na czyje żądanie i kiedy. Dla CISO to podstawa.
- Usuniecie calej wiedzy z dokumentu w kilka minut – bez retrainingu od zera
- Brak potrzeby przechowywania danych wrazliwych po treningu
- Odpornosc na przywrocenie wiedzy przez fine-tuning lub wrogie zapytania
- Jedna instancja modelu moze obslugiwac wielu odbiorcow z roznymi poziomami dostepu
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: Natively Unlearnable Large Language Models
Autorzy: Gaurav R. Ghosal, Pratyush Maini, Aditi Raghunathan
Unlearning aims to remove the influence of specific training data sources, but this has proved challenging because the contributions of different sources are entangled within the model. Isolating source contributions to disjoint parameters makes removal easier, though it obstructs joint learning …
arXiv: arxiv.org/abs/2606.13873
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}