
Wyobraź sobie, że uczysz się nowego języka. Nagle okazuje się, że musisz zapomnieć jednego piosenkarza, którego teksty przypadkiem zapamiętałeś. Bez wykopywania całych działów gramatyki, tylko tego jednego rozdziału. Zespół z Carnegie Mellon University pokazał właśnie architekturę modeli, która robi dokładnie to, oddziela specyficzną wiedzę od wspólnego fundamentu, żeby móc ją natychmiast wyłączyć. Bez nocnych przeliczeń i dostępu do starych danych.
Problem z wielkimi modelami: zapominanie boli
Wielkie modele językowe połykają internet, zapamiętują fragmenty książek, kodów, zagadki z forum. Potem, gdy trzeba usunąć coś na żądanie autora lub regulatora, jedyną znaną ścieżką jest przetrenowanie wszystkiego od nowa. To kosztuje miliony i zajmuje tygodnie. Metody ‘po szkodzie’, które próbują wymazać dane z gotowego modelu, często zawodzą. Hakerzy potrafią wydobyć skasowane informacje sprytnymi pytaniami, a drobne douczenie przywraca modelowi pamięć.
Post-hoc unlearning, bo o nim mowa, działa trochę jak zamazywanie markerem w zeszycie. Pod światło widać, co było napisane. I wystarczy odrobina płynu do zmazywania (w przypadku modeli to nowe dane), żeby ślad wrócił. Dlatego badacze szukają rozwiązań wbudowanych od początku w architekturę.
Szuflady na wiedzę: szkielet i zatyczki
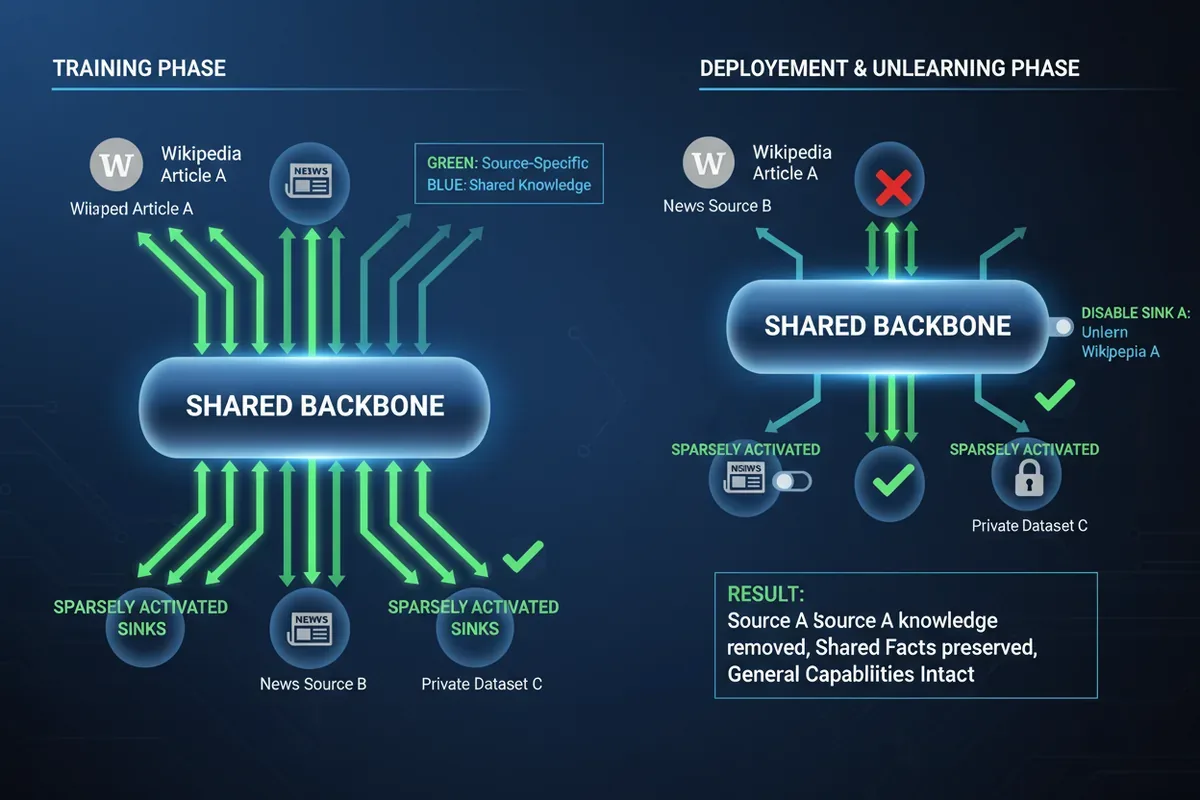
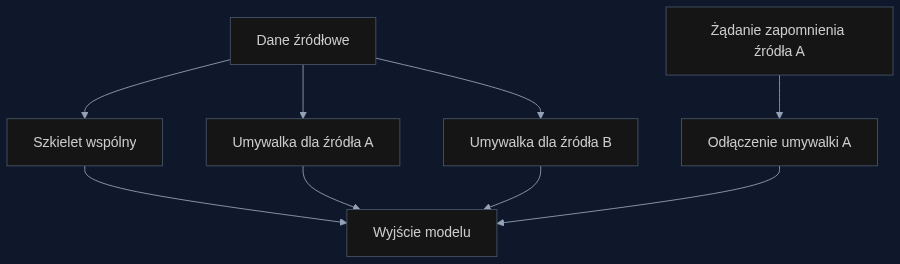
Koncept nazywa się NULLs (Natively Unlearnable LLMs). Sercem pomysłu jest rozdzielenie sieci neuronowej na dwie części: wspólny szkielet (backbone) i zestaw specjalistycznych ‘umywalek’ (sinks). Każda umywalka odpowiada konkretnemu źródłu danych, na przykład pojedynczemu artykułowi z Wikipedii. W trakcie uczenia informacje typowe dla danego tekstu naturalnie gromadzą się w odpowiadającej mu umywalce, natomiast wiedza ogólna, powtarzająca się w wielu źródłach, trafia do szkieletu.
W efekcie model działa jak stół z szufladami. Gdy trzeba zapomnieć o jednym artykule, po prostu zamykamy tę jedną szufladę. Nie tykamy przy tym reszty mebla, ani żadnej innej szuflady. Nie ma żadnych dodatkowych obliczeń gradientowych, nie trzeba sięgać do archiwalnych danych. Odłączenie umywalki jest natychmiastowe.
Usunięcie jednego artykułu wymazuje wiedzę dla niego specyficzną, a jednocześnie zachowuje fakty wspólne z artykułami o bliskiej tematyce, osiągając wynik zbliżony do przetrenowania modelu od zera.
Gaurav R. Ghosal i zespół
NULLs paper
6 milionów artykułów bez pomyłki
Takie podejście brzmi dobrze, dopóki nie zapytamy o skalę. Autorzy przetestowali je na całej angielskiej Wikipedii, gdzie każdy z 6 milionów artykułów traktowali jako osobną jednostkę do nauczenia i do zapomnienia. Wynik: usunięcie wiedzy o jednym artykule nie naruszało faktów wspólnych, nawet tych bardzo bliskich tematycznie. Na przykład, gdy wyłączano informacje o konkretnym gatunku rośliny, model wciąż doskonale orientował się w botanice ogólnej.
Co więcej, jakość odpowiedzi po takim zabiegu była niemal identyczna z modelem wytrenowanym od zera na danych pozbawionych tego artykułu. To trochę tak, jakby z biblioteki wyjąć jedną książkę, a czytelnik dalej znał całą dziedzinę, bo czytał inne, podobne. Różnica jest tylko taka, że tutaj nie trzeba przebudowywać całej biblioteki.
Harry Potter i próby wyciągnięcia sekretów
Oddzielny test dotyczył książek o Harrym Potterze: danych chronionych prawem autorskim, które często przewijają się w treningu dużych modeli. Autorzy sprawdzili, czy uparty użytkownik, zasypujący model podchwytliwymi pytaniami, zdoła wyciągnąć szczegóły fabuły z zamkniętej umywalki. Wynik: nie zdołał. Równie ważne było, że model nie odzyskiwał unlearned informacji po dodatkowym douczeniu na podobnych tekstach. Standardowe metody post-hoc zwykle w tym miejscu tracą skuteczność, bo ‘odświeżają’ skasowane ścieżki. NULLs był na to odporny.
Nie zgubiliśmy przy okazji zdrowego rozsądku
Zawsze istnieje ryzyko, że architektoniczne sztuczki osłabią ogólną inteligencję modelu. NULLs został jednak sprawdzony na standardowych testach językowych, takich jak rozumienie tekstu czy generowanie logicznych odpowiedzi. Jego wyniki nie różniły się od zwykłego transformera o tej samej wielkości. Można więc wbudować mechanizm zapominania bez strat dla jakości konwersacji i analizy.
Dla praktyka oznacza to jedno: da się zbudować model, który od startu jest gotowy na żądania usunięcia danych, bez rezygnowania z możliwości wielkich modeli językowych. Koniec z wyborem między zgodnością z prawem a użytecznością.
- Architektura NULLs dzieli model na wspólny szkielet i odłączalne umywalki odpowiadające poszczególnym źródłom danych.
- Zapominanie nie wymaga gradientów ani dostępu do danych treningowych, wystarczy zamknąć odpowiednią umywalkę.
- Przetestowano na 6 milionach artykułów Wikipedii, z zachowaniem ogólnej wiedzy i jakości modelu porównywalnej do treningu od podstaw.
- W studium przypadku powieści o Harrym Potterze model oparł się wydobyciu skasowanych informacji i nie odzyskał ich po dodatkowym douczeniu.
Praktyczne zastosowania
Aby lepiej zrozumieć opisywaną innowację, przygotowaliśmy cztery przykłady praktycznego zastosowania tej technologii w różnych branżach:




Podsumowanie
Mechanizm native unlearningu otwiera furtkę w sektorach, gdzie przechowywanie danych jest ściśle regulowane. Szpitale mogłyby trenować modele na dokumentacji medycznej z gwarancją, że na żądanie pacjenta konkretna historia choroby zostanie całkowicie i trwale usunięta bez utraty ogólnej wiedzy diagnostycznej. Kancelarie prawne zyskałyby narzędzie do analizy umów, które ignoruje fragmenty objęte klauzulą poufności po zakończeniu sprawy. Także serwisy informacyjne czy wydawnictwa mogłyby szybko wycofywać treści wycofane na mocy wyroków sądowych, nie przebudowując całego systemu rekomendacji.
Metryka artykułu źródłowego
Tytuł oryginalny: Natively Unlearnable Large Language Models
Autorzy: Gaurav R. Ghosal, Pratyush Maini, Aditi Raghunathan
Data publikacji: 15 czerwca 2026
arXiv: arxiv.org/abs/2606.13873
Napisanie tego artykułu zostało wspomagane przez sztuczną inteligencję. Treść opiera się na oryginalnym artykule naukowym, a jej dokładność została zweryfikowana automatycznie.
{kind=link}