

Szpitale wdrażające AI do diagnostyki stają przed problemem: co zrobić, gdy pacjent cofnie zgodę na wykorzystanie swojej dokumentacji? Tradycyjne modele trzeba by przetrenować od nowa, co jest kosztowne i powolne. Nowa architektura NULLs rozwiązuje to przez izolację danych każdego pacjenta w osobnym module, który można wyłączyć jednym kliknięciem.
Problem, który narasta z każdym wdrożeniem AI
RODO daje pacjentom prawo do bycia zapomnianym. W praktyce szpitalnej oznacza to, że jeśli pacjent wycofa zgodę na przetwarzanie danych medycznych, wszystkie systemy muszą te dane usunąć. Tyle że modele AI nie przechowują danych w bazie – one się na nich uczą. Żeby usunąć wpływ jednego pacjenta, trzeba by przetrenować cały model na nowym zbiorze, z pominięciem jego dokumentacji. Dla systemu trenowanego na 500 tysiącach kart pacjentów to kilka tygodni pracy klastrów GPU i rachunek rzędu 40-80 tysięcy złotych. W tym czasie model jest offline albo działa na starej wersji, co podnosi ryzyko błędów diagnostycznych. Komisje bioetyczne i inspektorzy ochrony danych zaczynają pytać: czy naprawdę nie ma szybszego sposobu?
Jak NULLs izoluje wiedzę pacjenta od wiedzy ogólnej
Architektura NULLs (Natively Unlearnable LLMs) dzieli model na dwie części: wspólny szkielet neuronowy i zestaw aktywowanych wybiórczo modułów, tak zwanych sinków. Podczas treningu informacje charakterystyczne dla konkretnego źródła – na przykład pojedynczej karty pacjenta – naturalnie gromadzą się w przypisanym do niego sinku. Wiedza współdzielona, taka jak zależności między objawami a chorobami czy standardy leczenia, pozostaje w szkielecie. Dzięki temu, gdy trzeba usunąć dane pacjenta, wystarczy dezaktywować odpowiadający mu sink. Nie wykonuje się żadnych aktualizacji gradientowych, nie potrzebuje się dostępu do pozostałych danych treningowych. W eksperymencie na 6 milionach artykułów Wikipedii usunięcie jednego źródła zachowywało fakty wspólne z artykułami pokrewnymi, a jednocześnie skutecznie wymazywało wiedzę specyficzną – wyniki były porównywalne z pełnym przetrenowaniem od zera.
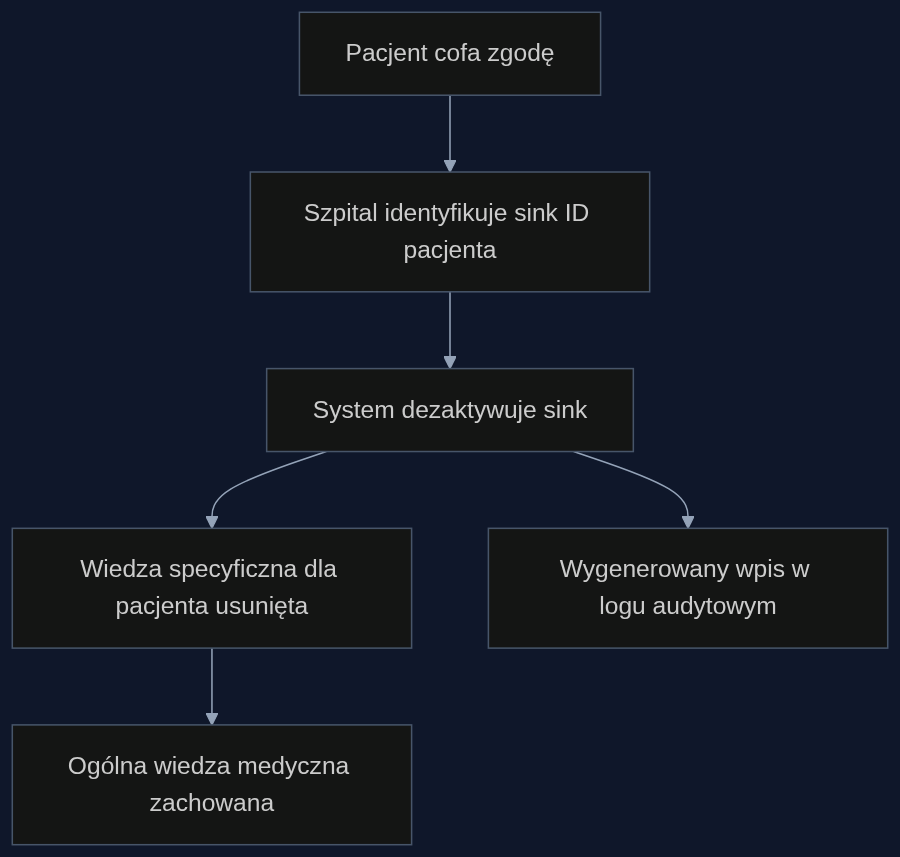
Scenariusz: wykrywanie sepsy a wycofanie zgody
Wyobraźmy sobie sieć szpitali, która używa modelu AI do wczesnego ostrzegania przed sepsą. Model wytrenowano na 500 tysiącach elektronicznych kart pacjentów, gdzie każda karta to osobny sink. Pewien pacjent z rzadkim markerem genetycznym i nietypową reakcją na antybiotyki składa wniosek o usunięcie danych. Dział IT identyfikuje jego sink – na przykład numer 47291 – i dezaktywuje go w panelu administracyjnym. Model od tego momentu nie zawiera już żadnych informacji pochodzących od tego pacjenta. Testy ekstrakcji przeciwnej (adversarial extraction) pokazują, że nie da się z niego wydobyć szczegółów tej konkretnej historii choroby. Jednocześnie ogólna zdolność wykrywania sepsy nie spada: szkielet modelu nadal rozpoznaje wzorce wyuczone z pozostałych 499 999 kart. Cała operacja trwa kilka minut i zostawia wpis w logu audytowym z datą, identyfikatorem sinka oraz podpisem administratora.
Korzyści i zwrot z inwestycji
Dla szpitala przetwarzającego rocznie 200 tysięcy dokumentacji, ręczne usuwanie danych z tradycyjnego modelu AI kosztowałoby około 50 tysięcy złotych i zajęłoby 3-4 tygodnie. NULLs skraca ten czas do kliku minut i eliminuje koszty przetrenowania. Jeszcze ważniejszy jest wymiar prawny: kara za naruszenie RODO może sięgnąć 4% globalnego obrotu, a brak skutecznego mechanizmu usuwania danych w systemach AI to poważny punkt sporny podczas kontroli. Architektura odporna na ponowne uczenie (relearning) zapobiega też sytuacjom, w których model przypadkowo odzyskuje usuniętą wiedzę po późniejszym dostrojeniu na podobnych danych. Dla dostawców systemów AI dla szpitali NULLs staje się argumentem przetargowym: możliwość natychmiastowego i audytowalnego usunięcia danych pacjenta to funkcja, którą komisje bioetyczne wpisują w wymagania już dziś.
Od czego zacząć
Jeśli planujesz wdrożenie AI diagnostycznego w swojej placówce, zapytaj dostawcę, jak realizuje prawo do bycia zapomnianym. Jeśli odpowiedź brzmi ‘przetrenujemy model’, masz sygnał, że architektura nie jest przygotowana na skalę. Warto rozważyć pilotaż z NULLs na ograniczonym zbiorze – na przykład oddziale kardiologii z 10 tysiącami historycznych kart. Dwa tygodnie testów z symulowanymi żądaniami usunięcia danych pokażą, czy model zachowuje skuteczność diagnostyczną i czy audytorzy są zadowoleni ze ścieżki audytu. To nie jest futurystyka – to konkretna decyzja architektoniczna, która oddziela systemy gotowe na RODO od tych, które będą generować ryzyko prawne przez lata.
- Usunięcie danych pacjenta w kilka minut zamiast tygodni przetrenowania
- Zachowanie ogólnej trafności diagnostycznej po dezaktywacji sinka
- Pełna ścieżka audytu zgodna z wymogami RODO i standardami badań klinicznych
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: Natively Unlearnable Large Language Models
Autorzy: Gaurav R. Ghosal, Pratyush Maini, Aditi Raghunathan
Unlearning aims to remove the influence of specific training data sources, but this has proved challenging because the contributions of different sources are entangled within the model. Isolating source contributions to disjoint parameters makes removal easier, though it obstructs joint learning …
arXiv: arxiv.org/abs/2606.13873
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}