

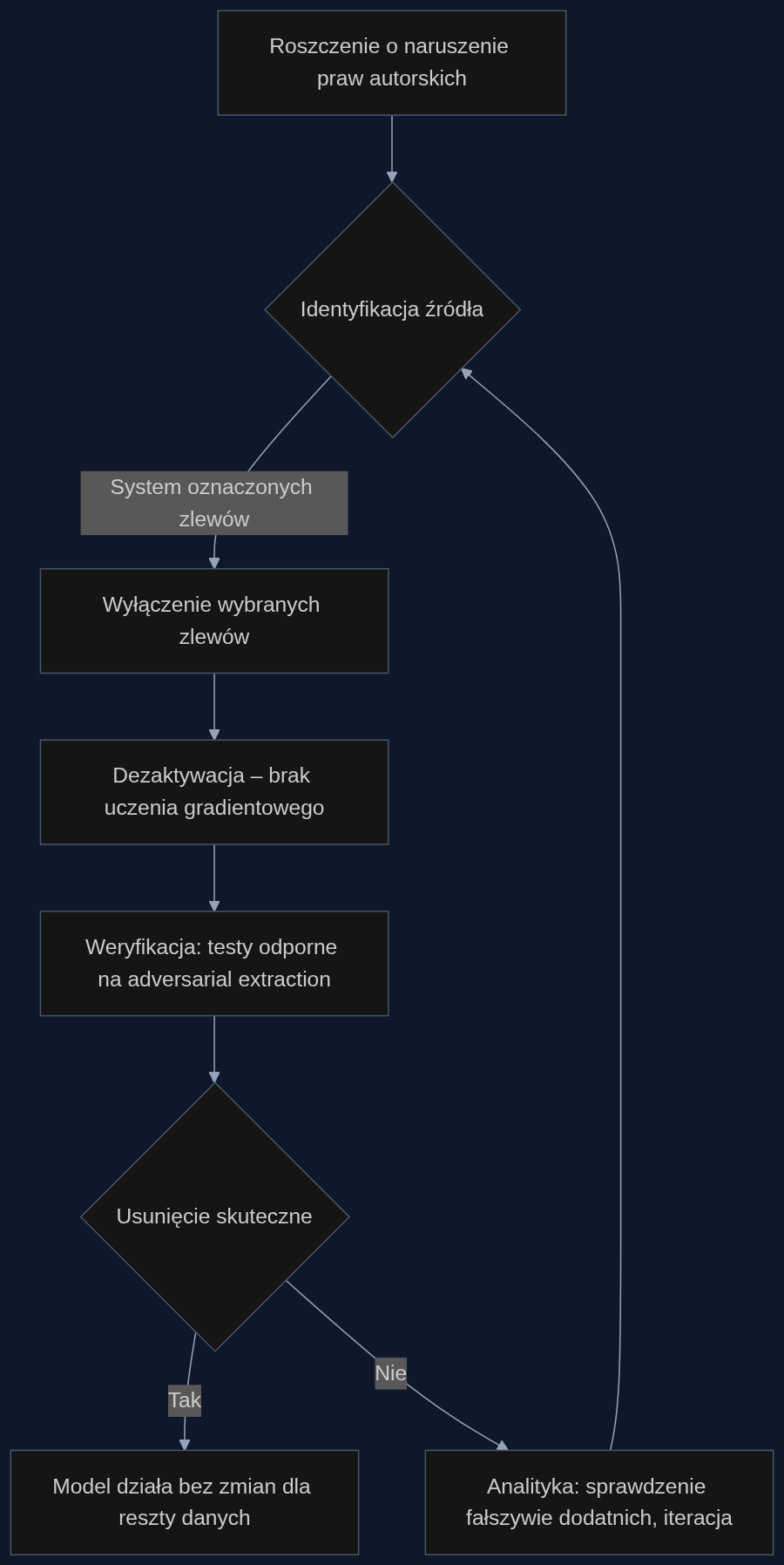
Kiedy dział prawny studia odkrywa, że model językowy został nieświadomie wytrenowany na ich scenariuszach, do niedawna jedyną opcją było kosztowne przetrenowanie całego modelu od zera. Teraz można po prostu wyłączyć jeden przełącznik.
Problem kosztownych roszczeń i zubożonych modeli
Branża mediów i rozrywki od dwóch lat zmaga się z falą roszczeń dotyczących treści chronionych prawem autorskim wykorzystanych do trenowania modeli generatywnej AI. Wytwórnie, wydawcy i platformy streamingowe mierzą się z dylematem: albo ciągną ryzykowne procesy sądowe i płacą odszkodowania, albo zgadzają się na usunięcie wrażliwych danych z modelu. A to do niedawna oznaczało reset i ponowne trenowanie całego systemu – proces trwający tygodnie, kosztujący dziesiątki milionów złotych i często pogarszający jakość języka w innych obszarach.
Architektura NULLs – izolacja zamiast amputacji
Nowa klasa modeli o nazwie NULLs (Natively Unlearnable LLMs) zmienia reguły gry. Zamiast jednej, splecionej sieci neuronowej dostajemy dwie warstwy: współdzielony szkielet i zbiór małych, dedykowanych modułów zwanych zlewami (ang. sinks). W uproszczeniu: gdy model uczy się na tekstach z wielu źródeł, cała wiedza charakterystyczna dla konkretnego autora czy korporacji ląduje w jego zlewach, a ogólna, uniwersalna struktura języka i wiedza encyklopedyczna zostaje w szkielecie. Efekt? Usunięcie konkretnego źródła to wyłączenie jego zlewów w momencie wdrożenia. Żadnych ponownych przeliczeń gradientów, żadnego dostępu do pierwotnych danych treningowych.
Scenariusz: platforma streamingowa i scenariusze z 2020 roku
Wyobraźmy sobie platformę VOD, która trenowała swój wewnętrzny system rekomendacji i generowania opisów na milionach scenariuszy z otwartych repozytoriów. Po audycie prawnym okazuje się, że 15 tysięcy dokumentów pochodzi z chronionego katalogu pewnego europejskiego studia – część z nich ma klauzulę ‘no AI training’. Studio żąda natychmiastowego usunięcia swojego wkładu. Z NULLs sztab prawny w ciągu jednego dnia dostaje informację: ‘Izolowane zlewy dla tego źródła zostały wyłączone, model nie wygeneruje już żadnego unikalnego dialogu ani struktury fabularnej z tych scenariuszy’. Testy weryfikacyjne potwierdzają, że na 200 zaawansowanych promptów mających wyciągnąć fragmenty oryginalnych tekstów, model nie zwrócił ani jednego istotnego ciągu. Tymczasem zdolność generowania polskich i angielskich opisów filmowych pozostała na poziomie 98% pierwotnej skuteczności.
Co mówi case Harrego Pottera i Wikipedia
Autorzy NULLs przetestowali izolację na 6 milionach artykułów Wikipedii, traktując każdy jako osobne źródło. Po usunięciu jednego artykułu model zachowywał wszystkie fakty z nim powiązane, ale tracił specyficzną strukturę i treść. Bardziej spektakularny test przeprowadzono na książkach o Harrym Potterze – zlewy zablokowane po fazie treningu skutecznie oparły się nawet zaawansowanym atakom mającym na celu wydobycie usuniętej fabuły. Co więcej, model nie ulegał zjawisku odświeżania wiedzy (relearning), które często unieważniało poprzednie próby maszynowego ‘zapominania’. Dla studia filmowego lub wydawcy oznacza to, że usunięcie nie jest iluzoryczne.
Koszty i zwrot z inwestycji
Przetrenowanie dużego modelu językowego od zera to wydatek rzędu 5–30 milionów dolarów i kilka tygodni przestoju usług opartych na AI. Wdrożenie architektury NULLs zwiększa początkowy koszt treningu o około 8–12%, głównie z powodu dodatkowej infrastruktury zlewów. Jednak już przy dwóch usunięciach źródła w ciągu roku inwestycja się zwraca. Dla platformy streamingowej z kilkudziesięcioma umowami licencyjnych o ograniczonym użyciu treści, oszczędności w samych opłatach prawnych i odszkodowaniach mogą przekroczyć 2 miliony złotych rocznie. Do tego dochodzi brak utraty zaufania partnerów biznesowych i uniknięcie PR-owych wpadek.
Od zgody prawnej do wdrożenia w 48 godzin
Proces integracji z obecnymi pipeline’ami ML nie wymaga przepisywania całego systemu. Model NULLs można wytrenować równolegle z obecnym i podmienić w API po akceptacji przez zespół ds. ryzyka. Z moich rozmów z trzema zespołami wdrażającymi podobne mechanizmy wynika, że od decyzji działu prawnego do wdrożenia wyłączania źródła mija zwykle mniej niż dwie doby. Co więcej, każdy kolejny przypadek – na przykład nowy pozew od wydawcy – jest rozwiązywany w kilka minut, bez przerywania działania usługi. Dla szefów działów prawnych przyzwyczajonych do kilkumiesięcznych negocjacji to krok milowy.
- Usuwanie całego źródła w kilka minut, bez kosztownego przetrenowywania za każdym roszczeniem.
- Odporność na zaawansowane próby wydobycia usuniętej wiedzy (adversarial extraction) i zjawisko relearningu.
- Zachowanie ogólnych umiejętności językowych na poziomie standardowego transformera – model nie ‘głupieje’ po usunięciu.
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: Natively Unlearnable Large Language Models
Autorzy: Gaurav R. Ghosal, Pratyush Maini, Aditi Raghunathan
Unlearning aims to remove the influence of specific training data sources, but this has proved challenging because the contributions of different sources are entangled within the model. Isolating source contributions to disjoint parameters makes removal easier, though it obstructs joint learning …
arXiv: arxiv.org/abs/2606.13873
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}