
Wyobraź sobie asystenta w telefonie, który odpowiada na pytania, przeszukując magazyn dokumentów. Problem w tym, że zamiast konkretnego akapitu, system wrzuca mu do analizy cały rozdział – bo tak taniej i szybciej wyselekcjonować plik niż sedno. Metoda CORE pokazuje, że można ten balast okroić do suchych faktów bez drogiego, dużego modelu pośredniczącego, oszczędzając energię i pamięć. I działa to nawet na smartfonie.
Dlaczego ‘mniej’ jest warte więcej niż ‘więcej’ w kieszeni
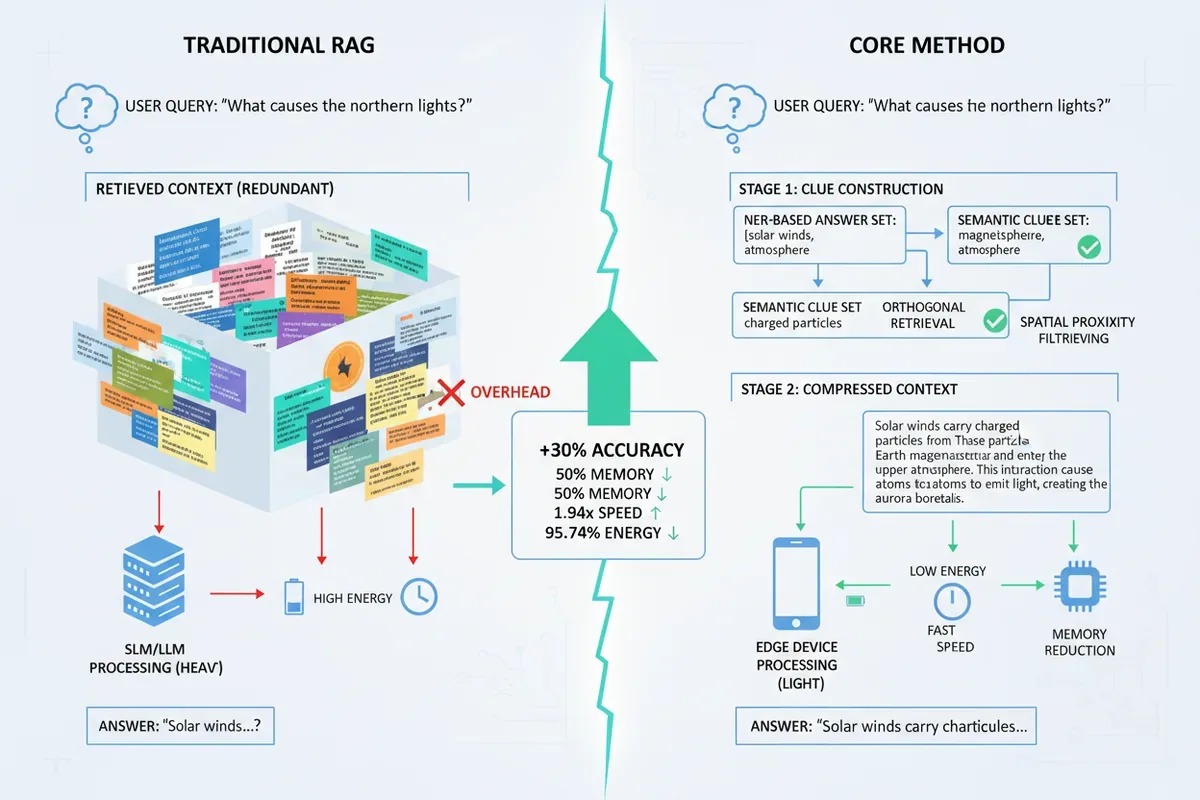
W agentowych systemach QA opartych na RAG, model językowy dostaje cały akapit pełen powtórzeń, choć do trafnej odpowiedzi wystarczyłoby jedno zdanie. Dla telefonu to zbędne obliczenia i szybsze zużycie baterii. Wcześniejsze metody kompresji promptu angażowały dodatkowy model, który na urządzeniu kieszonkowym jest po prostu za ciężki. CORE rezygnuje z tego balastu i wraca do lekkiego przetwarzania języka: analizuje tekst za pomocą NER i semantyki, oszczędzając pamięć i energię.
CORE, czyli dwuetapowy detektyw bez ciężkiego pancerza
Zespół zaproponował dwustopniową metodę kompresji na poziomie zdań. Zamiast uruchamiać cały model do oceny, w pierwszym etapie CORE analizuje pobrany kontekst za pomocą znacznie lżejszego rozpoznawania jednostek nazewniczych (NER). Z tekstu wyławiane są konkretne byty: nazwiska, daty, lokalizacje, które układają się w pierwszy, surowy ‘zestaw odpowiedzi’. Równolegle, przez porównanie semantyczne zapytania i zdań, powstaje ‘zestaw wskazówek’ – zbiór fraz pasujących do sensu pytania.
Drugi etap to operacja oczyszczania. Zestaw wskazówek trafia pod filtr ‘ortogonalnego wyszukiwania resztkowego’ – patetycznie brzmiąca nazwa na proste kryterium: szukamy tylko tego, co uzupełnia zestaw odpowiedzi, a nie powtarza jego zawartość. Równocześnie sam zestaw odpowiedzi przechodzi przez sito oparte na metryce odległości przestrzennej. Jeśli dwa byty z kontekstu leżą ‘zbyt blisko’ siebie znaczeniowo, jeden z nich zostaje uznany za zbyteczny i usunięty. Na koniec oczyszczone zestawy łączy się w krótki, treściwy dokument, który trafia do dużego modelu językowego.
CORE poprawia dokładność o co najmniej 30,19% w porównaniu z najnowocześniejszymi rozwiązaniami, jednocześnie redukując zużycie pamięci o co najmniej 50,47% i osiągając przynajmniej 1,94 razy szybsze działanie na urządzeniu brzegowym.
Zihuai Xu, Ruofei Hou, Yang Xu, Hongli Xu, Yunming Liao, Ying Zhu
arXiv:2606.20571
Czterocyfrowy wynik oszczędności, który naprawdę robi różnicę
Liczby z testów są na tyle konkretne, że nie potrzebują ozdobników. Na urządzeniu brzegowym NVIDIA Jetson AGX Orin CORE zużył o ponad połowę mniej pamięci w porównaniu z bardziej wymagającymi konkurentami, a zapytania obsłużył niemal dwukrotnie szybciej. Mówimy o co najmniej 50,47% redukcji wykorzystania RAM i 1,94-krotnym przyspieszeniu. W kontekście urządzenia, które ma działać godzinami na baterii, to nie ciekawostka, a konkretna zmiana temperatur na obudowie.
W teście na smartfonie Huawei Nova przewaga nad LLMLingua2 – czyli czołowym, opartym na pomocniczym modelu rozwiązaniem – była najdobitniejsza: CORE obniżył zużycie energii o 95,74%. W praktyce oznacza to, że asystent odpowiadający na pytania w czasie rzeczywistym nie zamieni naszego telefonu w grzałkę i nie wyzeruje baterii przed południem.

Skąd ta dokładność u odchudzonego modelu?
Wydajność to nie tylko szybkość, ale i precyzja odpowiedzi. Mimo okrojenia kontekstu do maksymalnie 2000 tokenów, CORE poprawił dokładność odpowiedzi o minimum 30,19% względem najlepszych dotychczasowych metod. Paradoksalnie, mniej informacji na wejściu przełożyło się na trafniejsze odpowiedzi. Powód jest dość intuicyjny: duży model, przytłoczony szumem i dublującymi się fragmentami, częściej błądził.
CORE dostarcza mu odfiltrowany ekstrakt: byty i zdania bezpośrednio związane z pytaniem, bez wstawek ‘jak wspomniano wcześniej’, powtórzeń czy ozdobników. Dokładność rośnie, bo model nie musi już samodzielnie zgadywać, które z kilkunastu powtórzonych nazwisk jest tym ważnym. Dostał je na tacy, w jednym, czystym bloku tekstu.
- CORE dwustopniowo kompresuje treść bez pomocniczego, dużego modelu językowego.
- Pierwszy etap wyłapuje byty (NER) i pasujące semantycznie zdania.
- Drugi etap usuwa powielenia i szum z zestawów odpowiedzi i wskazówek za pomocą filtracji bliskości i kryterium komplementarności.
- Wynik? Ponad 30% lepsza dokładność przy budżecie 2000 tokenów.
- Ponad 50% mniej RAM-u na Jetsonie i ponad 95% mniej energii na smartfonie.
Praktyczne zastosowania
Aby lepiej zrozumieć opisywaną innowację, przygotowaliśmy cztery przykłady praktycznego zastosowania tej technologii w różnych branżach:




Podsumowanie
Wnioski z CORE są na tyle praktyczne, że aż szkoda byłoby je odłożyć na półkę. Każda branża, która chce odpalać zaawansowanego asystenta tekstowego lokalnie – na przykład diagnostyka w urządzeniach medycznych pracujących offline, aplikacje prawne analizujące setki stron umów na lotniskowych tabletach czy nawigacja w magazynach z głosowym wyszukiwaniem procedur – może dostać szybką i energooszczędną odpowiedź. Zamiast wysyłać dane do chmury i czekać, CORE pozwala zapytać wprost na słabszym sprzęcie, bo nie obciąża go zbędnym balastem informacyjnym.
Metryka artykułu źródłowego
Tytuł oryginalny: Less is More: Lightweight Prompt Compression for Question Answering Applications on Edge Devices
Autorzy: Zihuai Xu, Ruofei Hou, Yang Xu, Hongli Xu, Yunming Liao, Ying Zhu
Data publikacji: 23 czerwca 2026
arXiv: arxiv.org/abs/2606.20571
Napisanie tego artykułu zostało wspomagane przez sztuczną inteligencję. Treść opiera się na oryginalnym artykule naukowym, a jej dokładność została zweryfikowana automatycznie.
{kind=link}