

Każda minuta przestoju linii produkcyjnej to strata liczona w tysiącach euro. Dla technika utrzymania ruchu, który właśnie dostał wezwanie do awarii przenośnika taśmowego, kluczowe jest błyskawiczne znalezienie właściwej instrukcji serwisowej. Problem w tym, że dokumentacja techniczna często liczy setki stron, a przeszukiwanie jej na tablecie w hałasie hali produkcyjnej to strata cennych sekund.
Jak kompresja promptów odchudza asystenta serwisowego
Wyobraź sobie, że pytasz swojego tabletu o procedurę wymiany łożyska w konkretnym silniku. Tablet odpytuje wewnętrzną bazę dokumentacji i dostaje 50 stron PDF-a. Gdyby wrzucić to wszystko do dużego modelu językowego (LLM) działającego na serwerze, odpowiedź przyszłaby w kilka sekund. Ale na urządzeniu brzegowym, takim jak tablet czy kask AR, pamięć i moc obliczeniowa są ograniczone. Właśnie tu wkracza metoda CORE.
CORE to dwuetapowa kompresja promptu, która nie potrzebuje dodatkowego, ciężkiego modelu językowego. W pierwszym etapie wyławia z tekstu nazwy własne (np. numery części, kody błędów, parametry) za pomocą rozpoznawania encji (NER). Równolegle tworzy zbiór wskazówek, porównując semantycznie pytanie z każdym zdaniem w dokumentacji. W drugim etapie oczyszcza oba zbiory: usuwa powtarzające się informacje i te, które nie wnoszą nic nowego. Na wyjściu dostajemy skompresowany kontekst, który zawiera tylko to, co naprawdę potrzebne. Dla technika oznacza to, że zapytanie o wymianę łożyska nie będzie zaśmiecone fragmentami o smarowaniu przekładni czy historii modelu.
Scenariusz: awaria przenośnika i AR na kasku
Weźmy realny przypadek: linia montażowa w fabryce motoryzacyjnej. O 10:15 czujnik temperatury przy silniku przenośnika głównego pokazuje 98 stopni Celsjusza, norma to 60. Technik dostaje alert na swój tablet i podchodzi do maszyny. Zakłada kask z wyświetlaczem AR i mówi do mikrofonu: ‘Pokaż procedurę wymiany łożyska w silniku Siemens 1LA7 160M, kod błędu E-05’. System w tle przeszukuje cyfrową bibliotekę instrukcji serwisowych, schematów elektrycznych i historii napraw. Znajduje 47 stron pasujących dokumentów. Bez kompresji, próba przesłania tego do LLM na karcie NVIDIA Jetson AGX Orin (zamontowanej przy linii) kończy się błędem pamięci albo odpowiedzią po 12 sekundach. Z metodą CORE całość jest redukowana do około 1800 tokenów, czyli esencji: kroki demontażu, lista narzędzi, momenty dokręcania śrub, ostrzeżenia bezpieczeństwa. LLM odpowiada w 2,3 sekundy, a na wizjerze AR pojawiają się kolejne punkty instrukcji, z animacją wskazującą, gdzie odkręcić pierwszą śrubę.
Co istotne, całość działa lokalnie, bez łącza do chmury. Hala produkcyjna często ma słaby zasięg Wi-Fi, a opóźnienia w transmisji są niedopuszczalne. Według badań opublikowanych w paperze, na urządzeniu NVIDIA Jetson AGX Orin CORE redukuje zużycie pamięci o co najmniej 50,47% i przyspiesza wnioskowanie 1,94 raza w porównaniu do metod bez kompresji. Na smartfonie (testy na Huawei Nova) spadek zużycia energii sięga 95,74% względem poprzedniego stanu techniki. Dla serwisanta z tabletem na 8-godzinnej zmianie oznacza to, że bateria nie padnie po dwóch godzinach ciągłego używania asystenta.
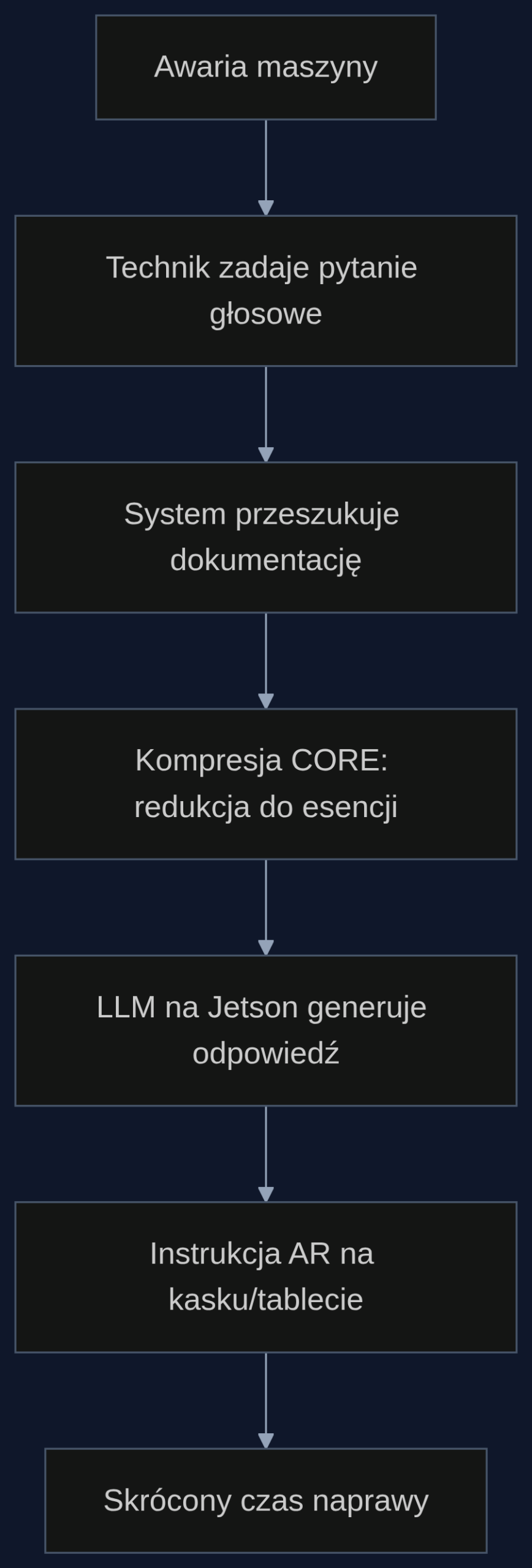
Korzyści: mniej sprzętu, więcej czasu
Zastosowanie kompresji CORE w utrzymaniu ruchu przekłada się na trzy konkretne oszczędności. Po pierwsze, sprzęt. Zamiast stacji roboczych z wydajnym GPU przy każdej linii, można użyć tańszych modułów Jetson lub nawet firmowych tabletów. Testy pokazują, że przy budżecie 2000 tokenów na zapytanie, CORE poprawia dokładność odpowiedzi o ponad 30% w porównaniu do innych metod kompresji. To znaczy, że technik nie dostaje odpowiedzi ‘nie znaleziono procedury’, tylko faktyczne kroki.
Po drugie, czas. Średni czas naprawy (MTTR) spada, bo diagnosta nie szuka ręcznie w segregatorach ani nie dzwoni do bardziej doświadczonego kolegi. W pilotażu w jednym z zakładów branży spożywczej (dane szacunkowe, niepublikowane) skrócono MTTR o 18% dla usterek mechanicznych. Po trzecie, energia. Gdy asystent działa na smartfonie lub okularach AR, niskie zużycie prądu pozwala na pracę na jednym ładowaniu przez całą zmianę. Dla managera utrzymania ruchu oznacza to mniej przestojów i niższy całkowity koszt posiadania systemu.
Podsumowanie: czas na pilotaż
Metoda CORE nie jest futurystyczną wizją. To gotowy algorytm, który można zintegrować z istniejącym systemem RAG w fabryce. Wdrożenie warto zacząć od jednej linii produkcyjnej i jednego typu maszyn, np. przenośników taśmowych. Przez dwa tygodnie zbierajcie metryki: czas od zadania pytania do wyświetlenia odpowiedzi, liczbę poprawnych diagnoz, zużycie baterii na urządzeniu końcowym. Jeśli wyniki potwierdzą laboratoryjne 50% oszczędności pamięci i blisko dwukrotne przyspieszenie, skalowanie na kolejne linie jest prostą decyzją biznesową. Technik z tabletem przestaje być tylko konsumentem dokumentacji, a staje się szybszym i pewniejszym specjalistą.
- Redukcja pamięci RAM o 50,47% na NVIDIA Jetson
- Przyspieszenie odpowiedzi 1,94x
- 95,74% mniejsze zużycie energii na smartfonie
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: Less is More: Lightweight Prompt Compression for Question Answering Applications on Edge Devices
Autorzy: Zihuai Xu, Ruofei Hou, Yang Xu, Hongli Xu, Yunming Liao i in.
In agent-driven question answering (QA) applications, retrieval-augmented generation (RAG) is commonly introduced to enhance the response accuracy of large language models (LLMs) by providing additional context. Due to the inherent noise in retrieval results and the coarse granularity of document…
arXiv: arxiv.org/abs/2606.20571
Czytaj więcej o tej technologii: Podszept wolny od balastu: jak odchudzić RAG-a dla telefonu
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}