

Adwokat na sali sądowej musi błyskawicznie znaleźć precedens lub interpretację przepisu. Tradycyjne systemy AI wspomagające odpowiedź, tzw. RAG, grzęzną pod ciężarem dokumentów – na smartfonie uruchomienie ich jest powolne i szybko wyczerpuje baterię. Nowa metoda CORE, opracowana przez badaczy, pozwala zmieścić to, co kluczowe, w limicie tokenów, przyspieszając odpowiedzi na urządzeniach brzegowych nawet 1,94 raza i oszczędzając 95,74% energii w porównaniu z poprzednią generacją kompresorów.
Ciężar kontekstu w kieszeni
Kiedy prawnik mobilny uruchamia aplikację do wyszukiwania odpowiedzi na pytanie o najnowszą linię orzeczniczą, system RAG najpierw pobiera kilkadziesiąt stron tekstu – ustawy, komentarze, wyroki. Całość musi zmieścić się w tzw. oknie kontekstowym modelu językowego. Dla urządzenia brzegowego, takiego jak smartfon, nawet 2000 tokenów to spory kęs. Bez kompresji kontekstu większość dokumentów jest odrzucana, a wraz z nimi cenne szczegóły. CORE rozwiązuje ten problem bez użycia dodatkowego, ciężkiego modelu pomocniczego, co odróżnia go od wcześniejszych metod, jak LLMLingua2.
Dwustopniowa kompresja bez dodatkowego modelu
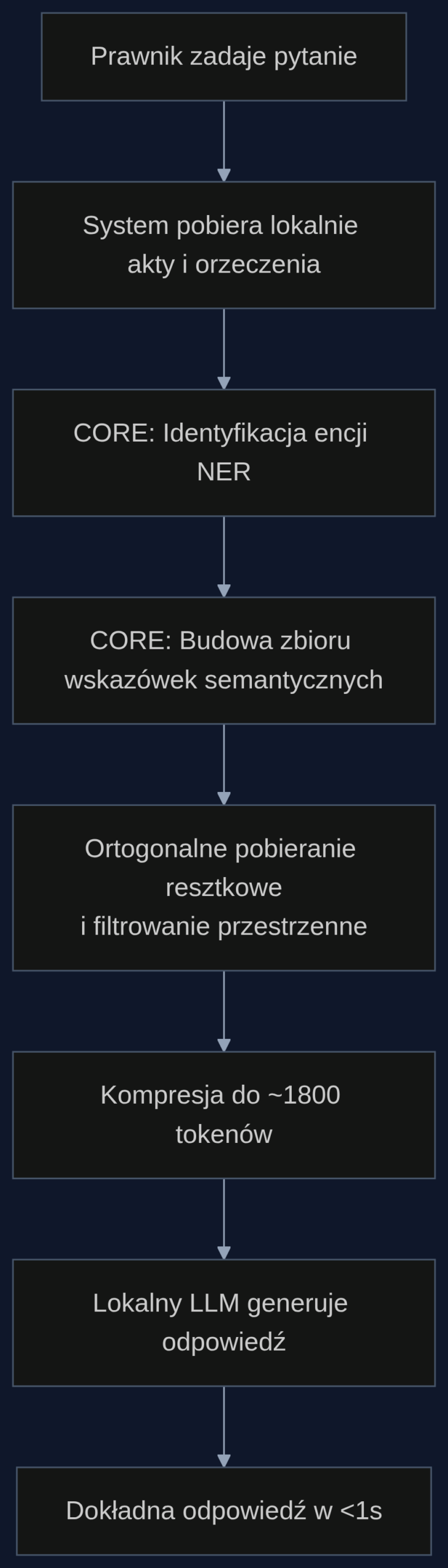
Metoda CORE działa dwuetapowo, korzystając wyłącznie z lekkich technik przetwarzania języka. W pierwszym etapie z pobranych dokumentów wyciąga encje nazwane (NER) – na przykład numery artykułów kodeksu, nazwy stron, sygnatury akt – tworząc zbiór odpowiedzi. Równolegle, przez semantyczne dopasowanie zapytania do zdań, buduje zbiór wskazówek. W drugim etapie oba zbiory są oczyszczane: wskazówki wzbogaca się o informacje nieobecne jeszcze w zbiorze odpowiedzi (tzw. ortogonalne pobieranie resztkowe), a odpowiedzi filtruje się według odległości przestrzennej, by usunąć powtarzające się lub nieistotne encje. Tak odchudzony kontekst trafia do lokalnego modelu LLM. Na smartfonie Huawei Nova CORE zużywa aż o 95,74% mniej energii niż LLMLingua2 w tym samym zadaniu.
Scenariusz z sali sądowej
Wyobraźmy sobie rozprawę z zakresu prawa zamówień publicznych. Pełnomocnik zamawiającego słyszy argument przeciwnika oparty na niedawnym wyroku Krajowej Izby Odwoławczej. Otwiera na służbowym telefonie aplikację, dyktuje pytanie: ‘Czy w przetargu poniżej progów unijnych wykonawca może uzupełnić dokumenty potwierdzające spełnianie warunków udziału po terminie składania ofert, jeśli oferta była najkorzystniejsza?’. Lokalnie zapisane bazy orzeczeń i komentarzy zwracają 47 stron tekstu. CORE w mniej niż pół sekundy identyfikuje kluczowe encje (sygn. akt KIO 1234/24, art. 26 ust. 3 Pzp), wybiera zdania semantycznie bliskie pytaniu i odrzuca pozostałe. Skompresowany kontekst (około 1800 tokenów) jest podawany modelowi. Odpowiedź – osadzona w konkretnych przepisach i linii orzeczniczej – pojawia się w ciągu sekundy, bez przerywania rozprawy i bez obaw o prywatność danych przesyłanych do chmury.
Korzyści i zwrot z inwestycji
W testach na urządzeniu brzegowym NVIDIA Jetson AGX Orin CORE poprawił dokładność odpowiedzi o co najmniej 30,19% w limicie 2000 tokenów, przy jednoczesnym obniżeniu zużycia pamięci o połowę i przyspieszeniu wnioskowania 1,94 raza. Dla kancelarii oznacza to mniej niepoprawnych odpowiedzi, które mogłyby narazić klienta na koszty. Oszczędność czasu jest równie wymowna: przy pięciu zapytaniach dziennie, gdzie każde trwało dotąd dwie minuty (wyszukiwanie ręczne + generowanie przez wolniejszy system), przejście na CORE skraca ten czas do 20 sekund na zapytanie. Daje to 50 zaoszczędzonych minut tygodniowo na prawnika. Przy przeciętnej stawce 250 zł za godzinę, roczna oszczędność w 10-osobowym zespole sięga blisko 100 tysięcy złotych. Co więcej, praca w trybie offline eliminuje ryzyko wycieku wrażliwych informacji przez sieć.
Pierwsze kroki do wdrożenia
Metoda CORE jest udostępniona jako otwarty kod, co pozwala zintegrować ją z istniejącymi aplikacjami do analizy prawnej. Sugerowany pilot: wybrać jedną dziedzinę (np. prawo pracy) i zestaw 200 pytań testowych z odpowiedziami zweryfikowanymi przez seniorów. Porównać dokładność i opóźnienie zwykłego RAG-a z wersją używającą CORE na przeciętnym smartfonie służbowym. Jeśli wyniki potwierdzą 30-procentową poprawę dokładności i dwukrotne przyspieszenie, można rozszerzać zakres bazy wiedzy. Kluczowe jest lokalne przechowywanie skompresowanego indeksu dokumentów – prawnicy nie muszą polegać na stabilnym łączu podczas wyjazdowych rozpraw.
- Dokładność odpowiedzi wyższa o co najmniej 30,19% przy limicie 2000 tokenów w porównaniu do wcześniejszych kompresorów
- Redukcja zużycia energii o 95,74% na smartfonie w porównaniu z LLMLingua2
- Przyspieszenie wnioskowania 1,94x i obniżenie zużycia pamięci o ponad 50% na urządzeniu brzegowym
- Pełna prywatność – przetwarzanie w trybie offline, bez przesyłania treści spraw do chmury
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: Less is More: Lightweight Prompt Compression for Question Answering Applications on Edge Devices
Autorzy: Zihuai Xu, Ruofei Hou, Yang Xu, Hongli Xu, Yunming Liao i in.
In agent-driven question answering (QA) applications, retrieval-augmented generation (RAG) is commonly introduced to enhance the response accuracy of large language models (LLMs) by providing additional context. Due to the inherent noise in retrieval results and the coarse granularity of document…
arXiv: arxiv.org/abs/2606.20571
Czytaj więcej o tej technologii: Podszept wolny od balastu: jak odchudzić RAG-a dla telefonu
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}