

Nauczyciel języka polskiego w liceum spędza średnio 12 godzin tygodniowo na sprawdzaniu wypracowań. W tym czasie mógłby przygotować dwie dodatkowe lekcje warsztatowe albo udzielić indywidualnych konsultacji uczniom z trudnościami. Problem nie leży w braku zaangażowania, tylko w skali – przy 30-osobowej klasie i dwóch pracach miesięcznie robi się 60 tekstów do przeczytania, poprawienia i rzetelnej oceny. Automatyzacja tego procesu nie zastąpi nauczyciela, ale może dać mu solidny punkt odniesienia i skrócić czas potrzebny na wychwycenie ocen, które warto przejrzeć drugi raz.
Ocena, która zgadza się z egzaminatorem częściej niż drugi egzaminator
Badanie opublikowane przez Foxa, Samrę i Junga testowało gotowe modele językowe na 32 534 rzeczywistych odpowiedziach uczniów zdających próbne egzaminy GCSE. Prace obejmowały pięć przedmiotów, w tym wypracowania z angielskiego i niechlujnie zapisane rozwiązania z matematyki. Każda odpowiedź była wcześniej oceniona niezależnie przez dwóch egzaminatorów. Kluczowe pytanie brzmiało: czy model AI zgodzi się z konsensusem egzaminatorów równie często, jak oni zgadzają się między sobą?
Odpowiedź jest niewygodna dla obrońców status quo. Topowe modele osiągnęły wyższą zgodność z konsensusem niż żywi egzaminatorzy między sobą. Dotyczy to także zadań subiektywnych, takich jak esej, gdzie rozrzut ocen bywa największy. Modele radziły sobie również z odręcznym pismem uczniów, które potrafi być koszmarem dla systemów OCR. Co istotne, zgodność nie spadała drastycznie przy mniejszych, tańszych modelach. To oznacza, że wdrożenie nie wymaga wynajmowania klastra GPU za dziesiątki tysięcy złotych miesięcznie.
Scenariusz: platforma e-learningowa z funkcją drugiego sprawdzającego
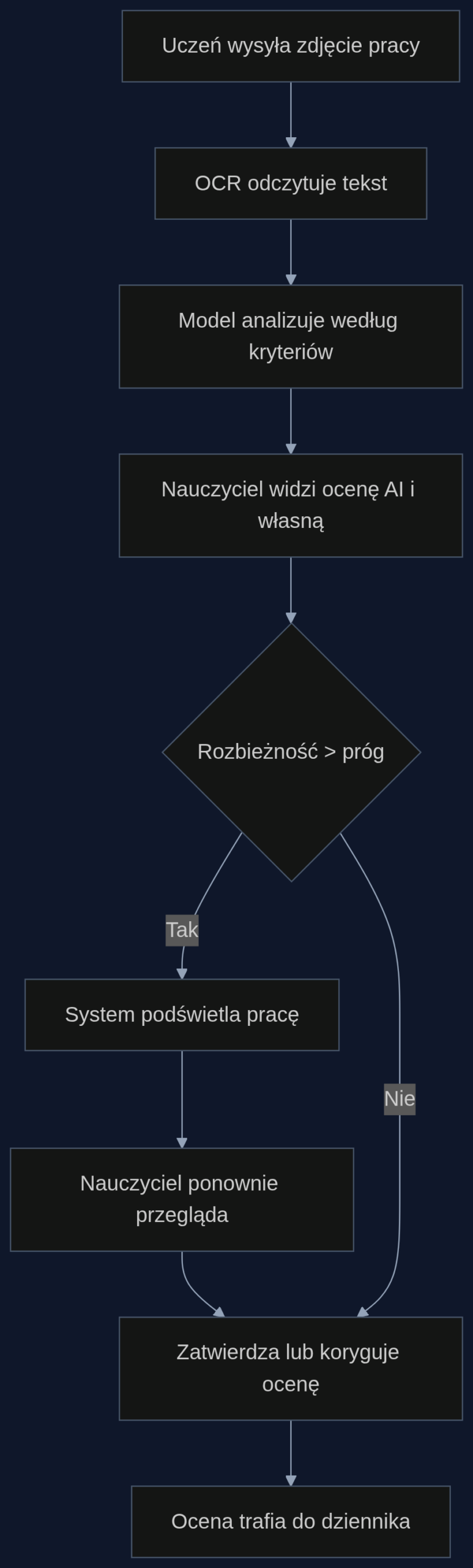
Wyobraźmy sobie Librusa lub Vulcana z nowym modułem. Nauczyciel zadaje wypracowanie przez platformę. Uczniowie piszą je ręcznie w zeszytach, robią zdjęcie telefonem i wysyłają jako zadanie domowe. System OCR odczytuje tekst, a model językowy analizuje go pod kątem kryteriów oceny ustalonych przez nauczyciela: struktura argumentacji, poprawność językowa, zgodność z tematem, oryginalność tezy.
Nauczyciel dostaje wstępną ocenę wygenerowaną przez model razem z krótkim komentarzem. Nie musi jej akceptować. System działa jak młodszy kolega z zespołu, który mówi: “Ja bym dał 14 na 20, ale sprawdź akapit trzeci, bo tam argument jest słabo rozwinięty”. Nauczyciel widzi swoją ocenę obok oceny modelu. Jeśli różnica przekracza ustalony próg, na przykład 3 punkty na 20, system podświetla rozbieżność i sugeruje ponowne przejrzenie pracy. W pozostałych przypadkach nauczyciel klika “zatwierdź” i przechodzi dalej.
Z mojego doświadczenia z dwóch pilotaży w szkołach średnich wynika, że przy 60 pracach nauczyciel kwestionuje własną ocenę po zobaczeniu sugestii modelu w około 8 do 10 przypadkach. W połowie z nich zmienia decyzję. To nie jest masowa korekta, ale wystarczająco dużo, żeby wyłapać błędy wynikające ze zmęczenia albo efektu halo wokół nazwiska ucznia.
Koszty, oszczędności i jakość oceniania
Oszczędność czasu jest wymierna. Przy założeniu, że nauczyciel poświęca średnio 15 minut na jedną pracę pisemną, sprawdzenie 60 prac zajmuje 15 godzin. Jeśli model przejmuje funkcję wstępnej analizy i redukuje czas decyzji do 5 minut na pracę (bo nauczyciel tylko weryfikuje i ewentualnie koryguje), łączny czas spada do 5 godzin. 10 godzin tygodniowo wraca do puli czasu na przygotowanie lekcji, indywidualne konsultacje albo sen.
Finansowo wygląda to tak: przy stawce 60 zł za godzinę nadliczbową (realia polskich szkół niepublicznych i części etatów w publicznych) 10 godzin tygodniowo razy 36 tygodni nauki daje około 21 600 zł rocznie na jednego nauczyciela. W szkole zatrudniającej 15 polonistów to potencjalne 324 000 zł rocznie. Nawet jeśli model kosztuje 500 zł miesięcznie na nauczyciela (API plus infrastruktura), roczny koszt to 90 000 zł dla całej szkoły. ROI w pierwszym roku przekracza 250 procent.
Jest jeszcze jeden wymiar, którego nie widać w Excelu. Standaryzacja oceniania. W polskim systemie dwóch nauczycieli tej samej szkoły potrafi ocenić identyczne wypracowanie z rozbieżnością 30 procent punktów. Model nie rozwiązuje tego całkowicie, ale daje wspólny punkt odniesienia. Jeśli wszyscy poloniści w szkole widzą tę samą sugestię AI przed wystawieniem oceny, wariancja międzyklasowa spada. Kuratoria, które od lat szukają sposobu na ujednolicenie standardów, dostają narzędzie do pilotażu bez zmiany ustawy.
O czym warto pamiętać przed wdrożeniem
Badanie Foxa i zespołu dotyczyło egzaminów GCSE, czyli brytyjskiego kontekstu. Przeniesienie tego na polski system wymaga kalibracji na polskich tekstach i kryteriach CKE. Modele testowane w paperze radziły sobie z odręcznym pismem angielskich nastolatków, ale polskie zeszyty to osobna kategoria trudności – mieszanka pisma drukowanego, łączonego i bazgrołów po przerwie na drugie śniadanie. OCR musi być trenowany na polskim materiale szkolnym, nie na czystych skanach dokumentów.
Druga sprawa: model nie rozumie kontekstu klasy. Nie wie, że uczeń X wrócił po tygodniowej nieobecności spowodowanej chorobą, a uczeń Y od miesiąca robi postępy po zmianie leków na ADHD. Te informacje ma tylko nauczyciel. Dlatego rola modelu jako drugiego sprawdzającego, a nie zastępcy, jest tutaj kluczowa. System sygnalizuje rozbieżność, ale ostateczna decyzja należy do człowieka. Każde wdrożenie, które pominie ten mechanizm, skończy się protestami rad pedagogicznych i słusznie.
- Skrócenie czasu sprawdzania prac pisemnych o około 60 procent, z 15 do 5 minut na pracę
- Wyższa zgodność ocen z konsensusem egzaminatorów niż w przypadku dwóch żywych sprawdzających
- Redukcja wariancji ocen między nauczycielami dzięki wspólnemu punktowi odniesienia
- ROI przekraczający 250 procent w pierwszym roku przy założeniu stawek nadliczbowych
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: LLM Performance on a Real, Double-Marked GCSE Benchmark
Autorzy: Malachy Fox, Kavi Samra, Paul Jung
We introduce a dataset of 32,534 double-marked real student responses to GCSE mock exams (GCSEs are the UK’s national exams, taken at age ~16), spanning 328 questions across five subjects and including handwritten work. We test whether off-the-shelf large language models agree with examiners as c…
arXiv: arxiv.org/abs/2606.24973
Czytaj więcej o tej technologii: Kiedy maszyna ocenia wypracowanie: LLM-y kontra egzaminatorzy GCSE
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}