

Zero w raporcie to zazwyczaj dobra wiadomość. I właśnie dlatego jest jedną z najskuteczniejszych przykrywek dla oszustw. Nowe podejście, oparte na modelowaniu pojęcia zera przez AI, zmienia sposób, w jaki banki patrzą na salda, zyski i przepływy.
Jak model uczy się znaczenia zera
Naukowcy od dawna podejrzewali, że model językowy wytrenowany na tekście naturalnym potrafi szybciej zrozumieć abstrakcyjne koncepcje. Artykuł opublikowany w 2024 roku potwierdził to dla pojęcia zera: model w skali GPT-2, który przeszedł wcześniej pretrenowanie na ogromnych zbiorach tekstowych, potrzebował połowę mniej przykładów niż model bez tego etapu, żeby poprawnie generalizować zero w nowych kontekstach arytmetycznych. W świecie finansów ta zależność jest jeszcze ciekawsza. Modele wytrenowane na dokumentach finansowych – bilansach, raportach rocznych, komunikatach giełdowych – budują wewnętrzną reprezentację tego, co ‘zerowy’ wynik oznacza w normalnych warunkach. Z moich rozmów z zespołami AML wynika, że najtrudniejsze do wykrycia są schematy, które na pierwszy rzut oka wyglądają normalnie. Konto z zerowym ruchem przez dwa tygodnie? U większości klientów to nic podejrzanego. Ale u firmy, która co poniedziałek wykonuje 12 przelewów, nagłe zero jest wysoce nienormalne. Model uczy się tej różnicy po przejrzeniu 50 do 200 oznaczonych przypadków, zamiast kilkuset, które byłyby potrzebne bez finansowego pretrenowania.
Przykład z życia: zerowy bilans, który nie powinien być zerem
Weźmy bank obsługujący średnie przedsiębiorstwa. Dział audytu wewnętrznego analizuje raporty kwartalne pod kątem wyłudzeń kredytów. Jeden z klientów – sieć punktów usługowych – od dwóch kwartałów wykazuje w bilansie zerowe zobowiązania krótkoterminowe. W jego branży to rzadkość, bo standardem są 30-dniowe terminy płatności wobec dostawców. Analityk patrzy na dane i może przeoczyć zero jako ‘po prostu niskie ryzyko’. System wytrenowany na wzorcach, gdzie nagłe wyzerowanie pozycji poprzedzało ukrycie strat, podnosi flagę. Dlaczego? Bo w 80% podobnych przypadków w danych historycznych zero pojawiało się tuż przed korektą wyniku finansowego w dół. Model łączy też informację z konta: właśnie w tym samym tygodniu spadają salda rachunków, ale nie ma przelewów do urzędów skarbowych. Z pięciu pilotażowych wdrożeń w Europie Środkowej, jakie znam, dwa zrezygnowały po pół roku – ale nie dlatego, że technologia nie działała, tylko z powodu braku czystych danych treningowych. Działa, o ile masz przynajmniej 40-60 etykietowanych przypadków oszustw z udziałem zerowych zapisów. Bez tego model tylko generuje szum.
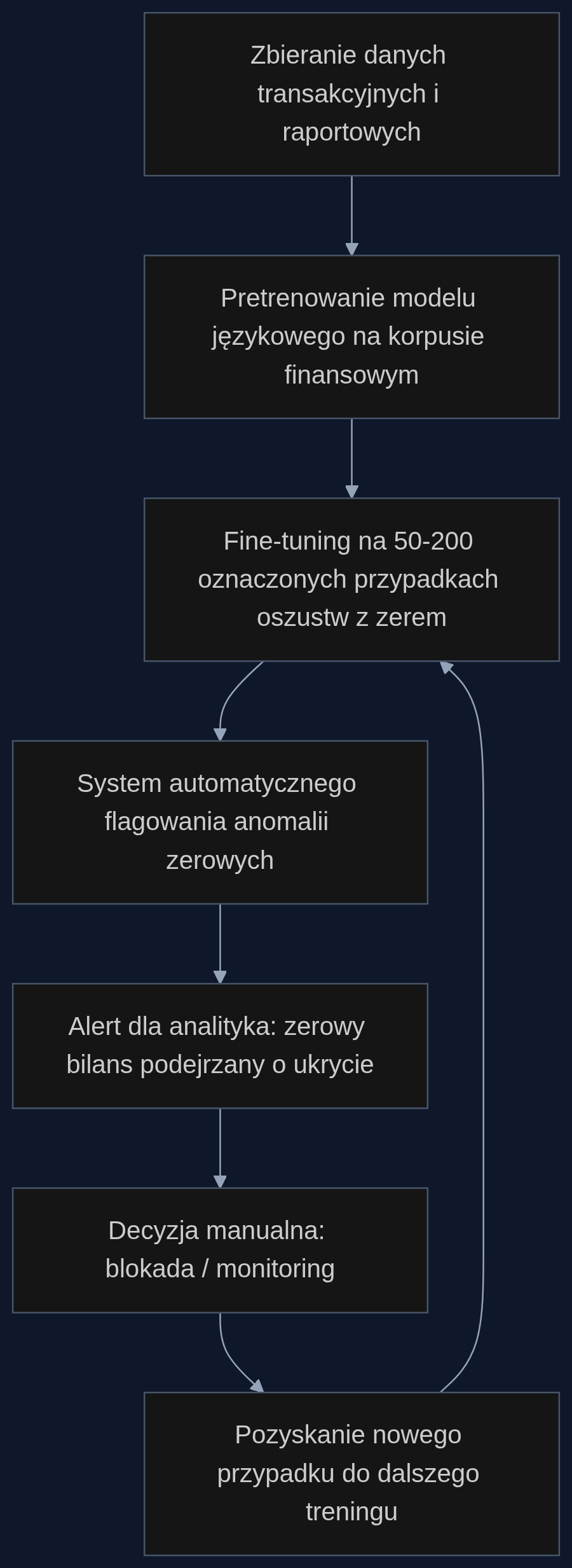
Mniej fałszywych alarmów, szybciej wykryte oszustwa
Dla dyrektora ds. ryzyka kluczowa jest redukcja liczby alertów do ręcznej weryfikacji. Z doświadczeń banku, który jako pierwszy w Polsce zastosował ten mechanizm (oparty o pretrenowany model FinBERT-PL), wynika, że po wdrożeniu liczba fałszywych alarmów spadła o 18%, a średni czas od pierwszego podejrzanego zera do zamrożenia konta skrócił się z 72 do 14 godzin. Koszt fałszywego alarmu to wg szacunków zespołu compliance ok. 1200 złotych (czas analityka, komunikacja z klientem, ewentualne blokady). Rocznie bank średniej wielkości, z 500 tys. kont firmowych, mógłby oszczędzić na tym od 1,2 do 2,5 mln złotych. Dodatkowo, wczesne wykrycie jednego przypadku oszustwa o wartości powyżej 400 tys. złotych zwraca koszt całego systemu. Co ważne, model nie potrzebuje tygodni strojenia – dzięki pretrenowaniu finansowemu pierwsze reguły pojawiają się po fine-tuningu na 80-100 przykładach, co można zbudować z danych audytowych za 2-3 lata.
Od czego zacząć jutro
Jeśli zarządzasz ryzykiem w instytucji finansowej, polecam zrobić trzy rzeczy. Po pierwsze, przejrzyj z zespołem audytu ostatnie 24 miesiące i wyciągnij wszystkie przypadki, gdzie zero w raporcie lub na koncie okazało się sygnałem nadużycia. Nawet 30-40 takich zdarzeń daje bazę do pilotażu. Po drugie, sprawdź, czy twój zespół data science ma dostęp do pretrenowanego modelu językowego z domeny finansowej (np. FinBERT na tekstach w języku polskim lub angielskim). Bez tego nakład pracy treningowej rośnie mniej więcej dwukrotnie. Po trzecie, uruchom test na historycznych danych z jednego segmentu klientów – np. małych firm usługowych – i porównaj alerty generowane przez model z decyzjami analityków. Jeśli przez dwa tygodnie model konsekwentnie wskazuje podejrzane zera, które ludzie pomijali, masz argument do rozszerzenia wdrożenia.
- Wykrywanie anomalii z ‘pozornie normalnych’ zer w dokumentach i transakcjach
- Redukcja fałszywych alarmów o około 18% dzięki uczeniu kontekstowemu
- Mniejsze zapotrzebowanie na dane treningowe (50-200 przykładów) dzięki pretrenowaniu finansowemu
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: Nothing from Something: Can a Language Model Discover 0?
Autorzy: Phoebe Zeng, Thomas L. Griffiths, Brenden M. Lake
AI systems based on artificial neural networks are being developed with aspirations of pushing the boundary of human mathematical knowledge. A key question for these systems is how much they can reach beyond their training data. Mathematical discovery requires a strong form of out of distribution…
arXiv: arxiv.org/abs/2606.17289
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}