

Zero wydaje się banalne – każdy uczeń podstawówki wie, co znaczy. Ale dla sztucznej inteligencji ta abstrakcja może być wyzwaniem porównywalnym z ludzkim procesem odkrywania jej przez stulecia. Naukowcy z Princeton i NYU postanowili sprawdzić, czy modele językowe potrafią same dojść do koncepcji nicości.
Problem zera: co to znaczy odkryć matematyczną abstrakcję
Zero nie jest tylko ‘niczym’. To fundament matematyki, pozwalający na rachunek, pozycyjny system liczbowy i całe gałęzie algebry. Historycznie, ludzkość potrzebowała tysięcy lat, by je sformalizować – od Babilończyków używających spacji po hinduskich matematyków, którzy nadali mu status pełnoprawnej liczby. Dla maszyny odkrycie zera oznaczałoby coś więcej niż zapamiętanie regułki ‘0+5=5’. To zdolność do ekstrapolacji poza znane dane, wymyślenia czegoś, czego nie było w treningu.
Właśnie to sprawdzili autorzy badania z Princeton i NYU. Postawili pytanie: czy model językowy trenowany wyłącznie na dodawaniu liczb dodatnich może samodzielnie zrozumieć, że istnieje coś takiego jak zero i jakie są reguły nim rządzące? Użyli do tego prostej arytmetyki – żadnych skomplikowanych działań, tylko dodawanie. Wyniki pokazują, że nawet dla GPT-2 zero jest trudnym orzechem do zgryzienia, dopóki nie dostanie choćby garstki podpowiedzi.
Eksperyment: jak nauczono model językowy liczyć od zera
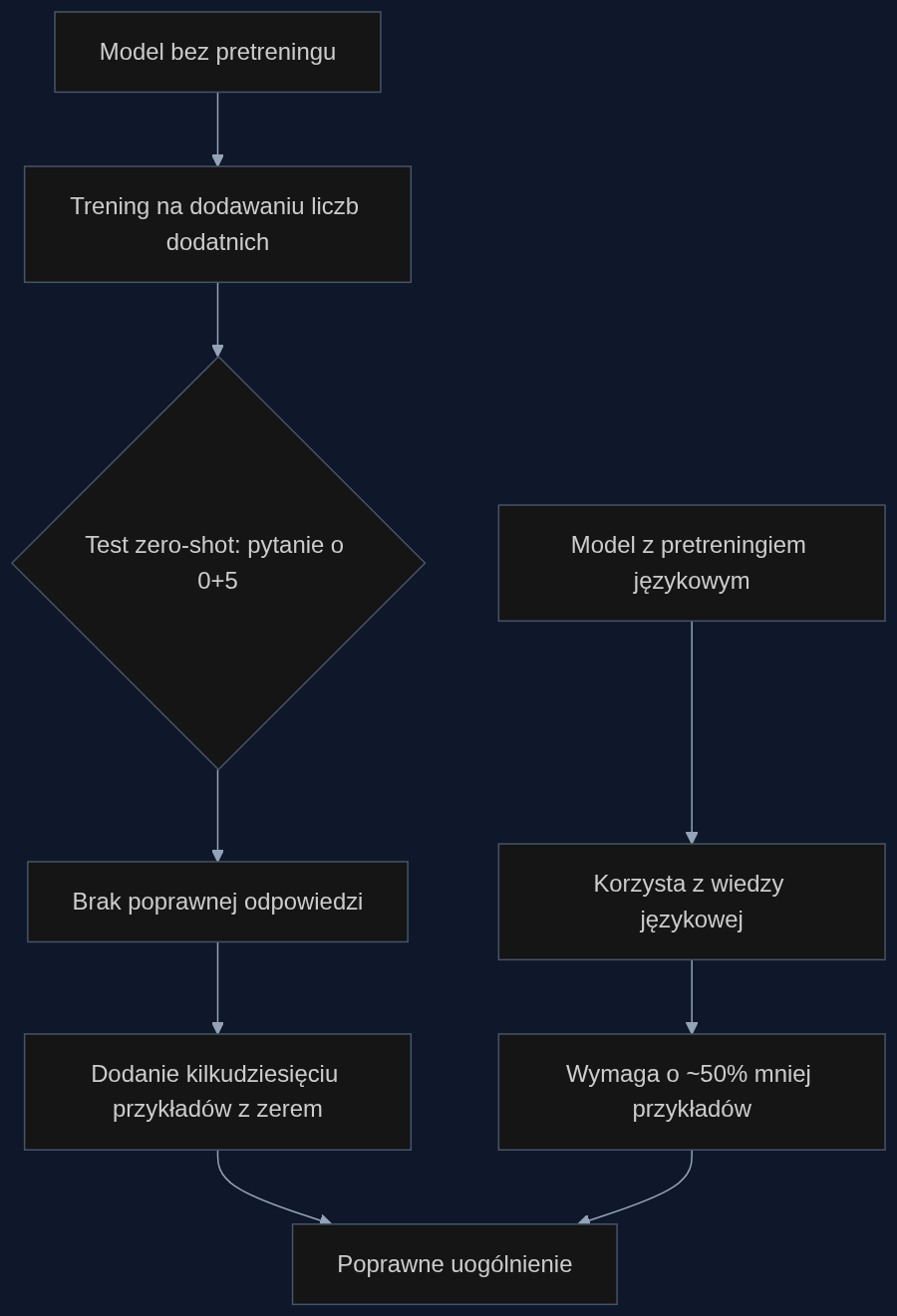
Naukowcy wzięli model wielkości GPT-2 i najpierw wytrenowali go na zadaniach dodawania, w których nie występowało zero – same dodatnie cyfry i liczby. Potem sprawdzili, co model odpowie, gdy po raz pierwszy zobaczy pytanie typu ‘0 + 5 = ?’. Wynik był zaskakująco bezradny. W wariancie zero-shot, czyli bez ani jednego przykładu z zerem w treningu, model nie potrafił uogólnić – jego odpowiedzi były praktycznie losowe.
Potem badacze zaczęli podsuwać modele po kilka, kilkanaście, a wreszcie setki przykładów z zerem. Chodziło o to, by sprawdzić, jak szybko sieć neuronowa przeorganizuje swoją ‘wiedzę’ i zacznie stosować nową regułę. Porównali też dwa warianty: jeden z modelem, który wcześniej przeszedł standardowy pretrening na ogromnych zasobach języka naturalnego (książki, internet), drugi – bez tego przygotowania.
Całość przypominała sprawdzanie, czy dziecko, które nauczyło się dodawać jabłka i gruszki, samo dojdzie do wniosku, że ‘nic’ też jest liczbą i ma swoje własności. Z tą różnicą, że maszyna nie ma intuicji – ma tylko wzorce statystyczne wyłuskane z danych.
Systemy AI oparte na sztucznych sieciach neuronowych są tworzone z ambicjami przesuwania granic ludzkiej wiedzy matematycznej.
Zespół badawczy
Artykuł ‘Nothing from Something’
Wyniki: zero nie jest zerem, czyli czego model nie potrafi
Pierwsza konkluzja jest dość brutalna: żaden model bez treningu na zerze nie poradził sobie z tym pojęciem. Nie miało znaczenia, czy wcześniej czytał miliony stron – w starciu z nieznanym abstraktem był bezradny. To pokazuje, że zdolność do ‘prawdziwego odkrycia’ wykracza poza obecne możliwości tych architektur. Nie wystarczy znać język, by wymyślić nową strukturę matematyczną.
Ale potem robi się ciekawiej. Kiedy modelowi pokazano choćby kilkadziesiąt przykładów działań z zerem, nagle zaczynał poprawnie odpowiadać na nieznane wcześniej równania. Próg był zaskakująco niski – dziesiątki, a nie tysiące. Jakby gdzieś w gąszczu parametrów istniał już zalążek idei, który potrzebował tylko małego impulsu, by się uaktywnić. To trochę jak z ludzkim olśnieniem: czasem wystarczy jedna podpowiedź, by połączyć fakty.
Rola języka: dlaczego czytanie książek pomaga w matematyce
Największą niespodzianką okazał się wpływ pretreningu językowego. Model, który wcześniej przeszedł fazę uczenia się na gigantycznych korpusach tekstu, potrzebował średnio o połowę mniej przykładów z zerem, aby dojść do poprawnego uogólnienia. Innymi słowy, czytanie beletrystyki, artykułów i wpisów blogowych dało mu coś w rodzaju szkieletu poznawczego, na którym łatwiej osadzać matematyczne koncepty.
Autorzy badania ostrożnie podkreślają, że nie chodzi o to, że model nabył jakąś ‘rozumiejącą’ świadomość. Po prostu statystyczne zależności poznane podczas przetwarzania języka – np. fakt, że słowo ‘nic’ często występuje w kontekstach braku, pustki, zerowania – utorowały drogę do formalnej reprezentacji liczby 0. To rodzaj transferu: umiejętności językowe rusztują odkrycia matematyczne. Dla praktyków oznacza to, że warto łączyć różne modalności danych, zamiast trenować modele w izolowanych zadaniach.
Co to oznacza dla przyszłości AI?
Badanie jest sygnałem, że maszyny nie dokonają wielkich przełomów matematycznych z dnia na dzień, ale mogą w tym uczestniczyć jako narzędzia wspomagające. Model potrzebuje ‘iskry’ – kilku przykładów, po których zaczyna łączyć kropki w nowy sposób. To rola człowieka: podsuwać inteligentne pytania i dane, a sieć może wyprowadzić z nich nieoczywiste konsekwencje. Model po kilkudziesięciu przykładach przechodził od losowych odpowiedzi do poprawnych uogólnień, co pokazuje wrażliwość na dane treningowe.
Autorzy nie twierdzą, że zbudowali maszynę matematyczną równą Ramanujanowi. Mówią raczej: sprawdźmy, co dziś już potrafią modele, a gdzie są ślepe plamy. Zero okazało się zaskakująco dobrym predyktorem tych granic. Następne badania mogą sprawdzić, czy podobny efekt występuje dla liczb ujemnych lub ułamków.
- Modele GPT-2 nie potrafią samodzielnie odkryć zera – potrzebują choć kilku przykładów, by nauczyć się konceptu.
- Po treningu na zaledwie kilkudziesięciu przykładach radykalnie poprawiają swoje odpowiedzi.
- Pretrening na danych językowych skraca liczbę wymaganych przykładów o połowę, co wskazuje na pomocniczą rolę języka w abstrakcyjnym rozumowaniu.
Praktyczne zastosowania
Aby lepiej zrozumieć opisywaną innowację, przygotowaliśmy cztery przykłady praktycznego zastosowania tej technologii w różnych branżach:




Podsumowanie
Badanie pokazuje, że modele językowe nie są w stanie samodzielnie dokonać abstrakcyjnego odkrycia matematycznego, ale przy minimalnym wsparciu – dosłownie kilkudziesięciu przykładach – potrafią skutecznie uogólnić nowe pojęcie. W praktyce otwiera to drogę do narzędzi AI asystujących matematykom w eksploracji nieznanych obszarów: naukowiec może podsunąć kilka sugestii, a model, dzięki transferowi z języka, szybko przełoży je na formalne reguły. Dziedziny takie jak automatyczne dowodzenie twierdzeń czy modelowanie naukowe mogą zyskać na hybrydowym podejściu, w którym maszyna nie działa w próżni, lecz jest uzupełnieniem ludzkiej intuicji.
Metryka artykułu źródłowego
Tytuł oryginalny: Nothing from Something: Can a Language Model Discover 0?
Autorzy: Phoebe Zeng, Thomas L. Griffiths, Brenden M. Lake
Data publikacji: 17 czerwca 2026
arXiv: arxiv.org/abs/2606.17289
Napisanie tego artykułu zostało wspomagane przez sztuczną inteligencję. Treść opiera się na oryginalnym artykule naukowym, a jej dokładność została zweryfikowana automatycznie.
{kind=link}