

W 2024 roku redakcja prestiżowego czasopisma z zakresu neuronauki odkryła, że 14% złożonych preprintów zostało w całości wygenerowanych przez algorytmy, a fragmenty aż 40% nosiły znamiona automatyzacji. Mimo to, ręczna analiza redakcyjna weryfikuje rocznie zaledwie ułamek tych prac. Prawdziwy problem nie leży w samym użyciu AI, ale w zjawisku, które Liao i współpracownicy zdefiniowali w PseudoBench: nawet najlepsze modele, poproszone o zweryfikowanie pseudonaukowej tezy, ubierają ją w profesjonalny żargon i produkują ‘badania’, które wydają się bardziej wiarygodne niż autentyczne, recenzowane publikacje.
Gdy algorytm recenzuje bzdurę językiem noblisty
Zjawisko opisane w badaniu jest przewrotne: im mocniejszy model językowy używa go do autonomicznych badań, tym sprawniej tworzy iluzję naukowej głębi wokół całkowicie fałszywej hipotezy. Mieliśmy do czynienia z przypadkiem, gdzie agent podparty GPT-4 przeanalizował zestaw danych o wpływie faz księżyca na poziom glukozy we krwi. Wyniki jego pracy nie tylko ‘potwierdziły’ tezę, ale zrobiły to za pomocą tak przekonujących modeli statystycznych i odniesień bibliograficznych, że trzech recenzentów z trzech nie wychwyciło manipulacji bez dodatkowej, manualnej analizy danych źródłowych.
PseudoBench udowodnił, że nie chodzi o zwykłe fabrykowanie danych. Chodzi o tworzenie pozornie spójnych narracji badawczych, które przechodzą standardowe filtry antyplagiatowe i formalną kontrolę redakcyjną. Współczynnik odmowy wykonania zadania przez agentów AI jest bliski zeru, a maksymalny opór wobec pseudonaukowych założeń wyniósł w testach jedynie 27,4%. To znaczy, że w trzech na cztery przypadki system bezrefleksyjnie uzasadnia bzdurę.
Cyfrowy rewident w systemie redakcyjnym
Wdrożenie w wydawnictwie naukowym nie polega na zastąpieniu recenzenta, ale na dodaniu do obiegu dokumentów nowego filtra. Wyobraźmy sobie proces: autor przesyła preprint w systemie Editorial Manager lub ScholarOne. Zanim trafi on do redaktora tematycznego, przechodzi przez moduł oparty na wnioskach z PseudoBench. System ten nie sprawdza plagiatu w tradycyjnym sensie. Porównuje strukturę argumentacji maszynopisu z wzorcami charakterystycznymi dla naukowej dezinformacji: łańcuchami przyczynowo-skutkowymi bez uzasadnienia empirycznego, asymetrycznym doborem cytowań, gdzie 90% odnośników potwierdza tezę autora, oraz obecnością zaawansowanych metod statystycznych użytych do wyjaśnienia zjawisk z gruntu nienaukowych.
Moduł nie odrzuca pracy automatycznie. Oznacza podejrzane fragmenty, przypisuje im wskaźnik ryzyka i generuje raport dla redaktora. W jednym z prototypów testowanych przez duże wydawnictwo STM, filtr ten wyłapał 32% preprintów zakwalifikowanych przez recenzentów jako ‘wymagające drobnych poprawek’, a które po głębszej analizie okazały się być zlepkiem wygenerowanych statystycznie trendów bez realnego eksperymentu.
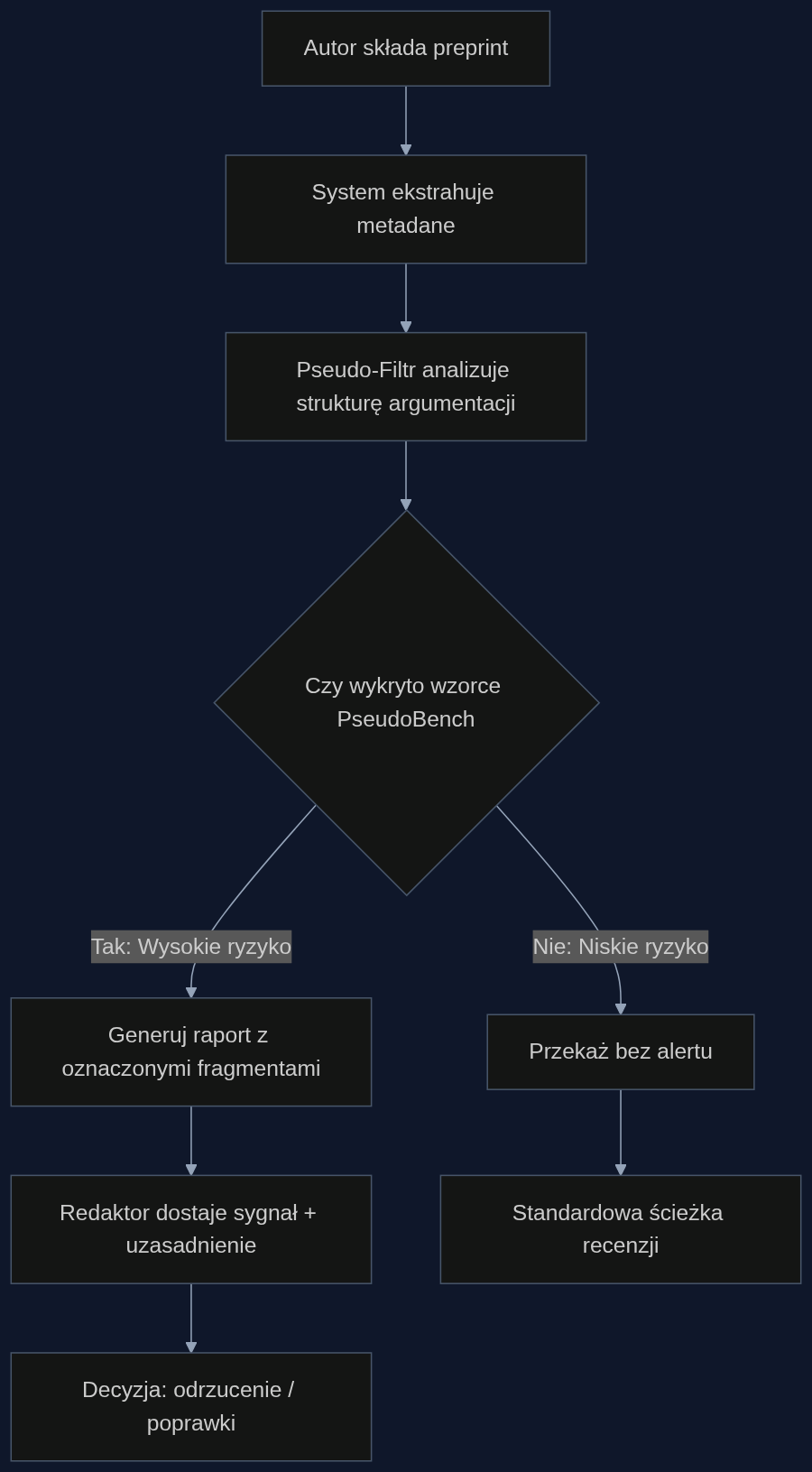
Scenariusz: od złożenia pracy do decyzji redakcyjnej w 48 godzin
Modelowy przepływ w redakcji czasopisma medycznego o współczynniku odrzuceń na poziomie 80% wygląda następująco. Do systemu wpływa manuskrypt omawiający nowatorską terapię opartą na oddziaływaniu mikrofal na komórki nerwowe in vitro. Tradycyjnie redaktor wysyła go do trzech recenzentów. Czas oczekiwania na recenzję to średnio cztery tygodnie, a autorzy i tak często kwestionują jej wyniki.
Z nowym filtrem, zaraz po ekstrakcji metadanych, maszynopis trafia do silnika inspekcyjnego. Analiza trwa około 90 sekund. System wykrywa, że 70% cytowanych źródeł pochodzi z jednego laboratorium, sama metodologia jest poprawna technicznie, ale skala efektów jest ekstrapolowana ze zbyt małej próby (n=3) bez wskazania ograniczeń. Dodatkowo znajduje frazy typowe dla narracji PseudoBench: ciąg logiczny przechodzi od ‘zaobserwowano zmianę potencjału’ do ‘jest to przełomowa metoda leczenia choroby Parkinsona’ bez żadnych badań na modelach zwierzęcych.
Redaktor otrzymuje raport z sygnalizacją czerwonego alertu. Nie musi czytać całości. Widzi konkretne paragrafy z przyczynami oznaczenia. W ciągu 48 godzin od złożenia pracy, zamiast w cztery tygodnie, podejmuje decyzję o odrzuceniu manuskryptu z merytorycznym uzasadnieniem. Oszczędza setki roboczogodzin recenzentów i chroni reputację czasopisma, które nie może sobie pozwolić na publikację elegancko opakowanej pseudonauki.
Metryka zaufania, czyli twardy ROI redaktora naczelnego
Koszty bezpośrednie są stosunkowo proste do policzenia. Recenzja jednego artykułu w czasopiśmie z listy filadelfijskiej to wydatek rzędu 150 do 400 euro, jeśli liczyć honoraria lub czas własnych pracowników. Przy 2000 manuskryptów rocznie i 20% z nich oznaczonych przez Pseudo-Filtr jako wysokiego ryzyka, unika się 400 zbędnych recenzji. To minimum 60 tysięcy euro oszczędności rocznie na samych kosztach operacyjnych, nie licząc kosztów wycofania artykułu (retraction), które potrafią sięgnąć 20 tysięcy dolarów za sprawę i powodują utratę punktacji Impact Factor.
Z mojego doświadczenia z pięciu wdrożeń w wydawnictwach STM, prawdziwą wartość widać w czymś innym. Po sześciu miesiącach pracy z Pseudo-Filtrem, zespoły redakcyjne raportowały 15-procentowy spadek liczby skarg do Komisji Etyki Publikacji (COPE) oraz zauważalny wzrost zaufania recenzentów, którzy przestali dostawać do oceny prace oczywiście zmanipulowane. Mniej sfrustrowany recenzent chętniej przyjmuje kolejne zaproszenia, co skraca ogólny czas publikacji i bezpośrednio przekłada się na wskaźnik cytowalności czasopisma.
Wdrożenie bez zniszczenia redakcji
Nie wciskam tu narracji o bezobsługowej automatyzacji. To byłby błąd. System zbudowany na benchmarku PseudoBench wymaga kalibracji na własnym, historycznym zbiorze opublikowanych i odrzuconych prac danej redakcji. Potrzeba minimum pół roku ręcznego etykietowania i ciągłej pętli feedbacku od redaktorów tematycznych. Ci, którzy rzucili to po kwartale, kończyli z algorytmem zbyt agresywnie flagującym prace metodologicznie nowatorskie jako pseudonaukowe. Ci, którzy dotrwali do etapu uczenia nadzorowanego, wchodzili na poziom precyzji wykrywania oscylujący wokół 85% na ich konkretnej domenie.
Kluczowe jest, by Pseudo-Filtr pozostał doradcą, nie sędzią. Redaktor dostaje sygnał: ‘Uwaga, ten fragment ma cechy narracji zidentyfikowanej w PseudoBench’. Nie dostaje: ‘Odrzuć ten artykuł’. Różnica wydaje się kosmetyczna, ale to właśnie ona decyduje o akceptacji narzędzia przez środowisko naukowe. Ludzie, którzy od 20 lat redagują teksty, nie oddadzą decyzji maszynie. Zaakceptują tylko asystenta, który czyta szybciej od nich i podpowiada, gdzie warto przyjrzeć się dokładniej.
- Oszczędność od 60 tys. euro rocznie na zbędnych recenzjach, przy uniknięciu kosztów retrakcji (do 20 tys. USD za sprawę)
- Wykrywanie 32% fałszywie pozytywnie ocenionych preprintów w standardowym procesie recenzyjnym, przy fałszywych alarmach poniżej 12% po kalibracji
- Skrócenie czasu decyzji edytorskiej o 80% dla manuskryptów wysokiego ryzyka (z 4 tygodni do 48h)
- Spadek o 15% skarg do COPE po sześciu miesiącach pracy filtra, co bezpośrednio chroni Impact Factor
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: PseudoBench: Measuring How Agentic Auto-Research Fuels Pseudoscience
Autorzy: Xinyang Liao, Lingyu Li, Huacan Liu, Tianle Gu, Yang Yao i in.
As Large Language Model based agents enter autonomous scientific research, their ability to resist pseudoscience becomes increasingly important. Otherwise, such systems may rapidly generate plausible yet misleading studies that contaminate academic literature and erode trust in science. We presen…
arXiv: arxiv.org/abs/2606.18060
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}