

Zmiana regulaminu zwrotów w trakcie dnia potrafi wywrócić pracę contact center. Klient pyta o reklamację, chatbot odpowiada według starej polityki, klient się irytuje, a sprawa trafia do eskalacji. Zespół Bojie Li znalazł sposób, żeby naprawić tę odpowiedź w tej samej sesji, bez restartu rozmowy i bez utraty kontekstu – wszystko dzięki edytowalności pamięci podręcznej modeli językowych.
Notatki w cache’u: dlaczego model można poprawić bez restartu
Zespół Bojie Li przeanalizował cztery rodziny modeli transformerowych i odkrył coś, co zmienia podejście do serwowania chatbotów korporacyjnych. Podczas fazy prefill model zapisuje w pamięci KV cache coś w rodzaju notatek – wniosków warunkowanych wcześniejszymi polami. Same wektory pola (na przykład system prompt z polityką zwrotów) odpowiadają za mniej niż 1% decyzji. Decyzja jest już zapisana na późniejszych pozycjach cache’u. To oznacza, że jeśli w trakcie sesji polityka się zmieni, nie trzeba przeliczać całego kontekstu od nowa. Wystarczy dołączyć do istniejącego cache’u krótką notatkę korygującą – erratum – która nadpisuje wcześniejszy wniosek. Warunek: erratum musi zawierać łańcuch myślowy (CoT), który zmusza model do ponownego przemyślenia korekty. Bez CoT poprawka jest ignorowana, z CoT dokładność odzyskiwania właściwej decyzji sięga 1.00 dla modelu 8B przy koszcie obliczeniowym około 1% oryginalnego prefillu.
Scenariusz: zmiana polityki zwrotów w trakcie dnia
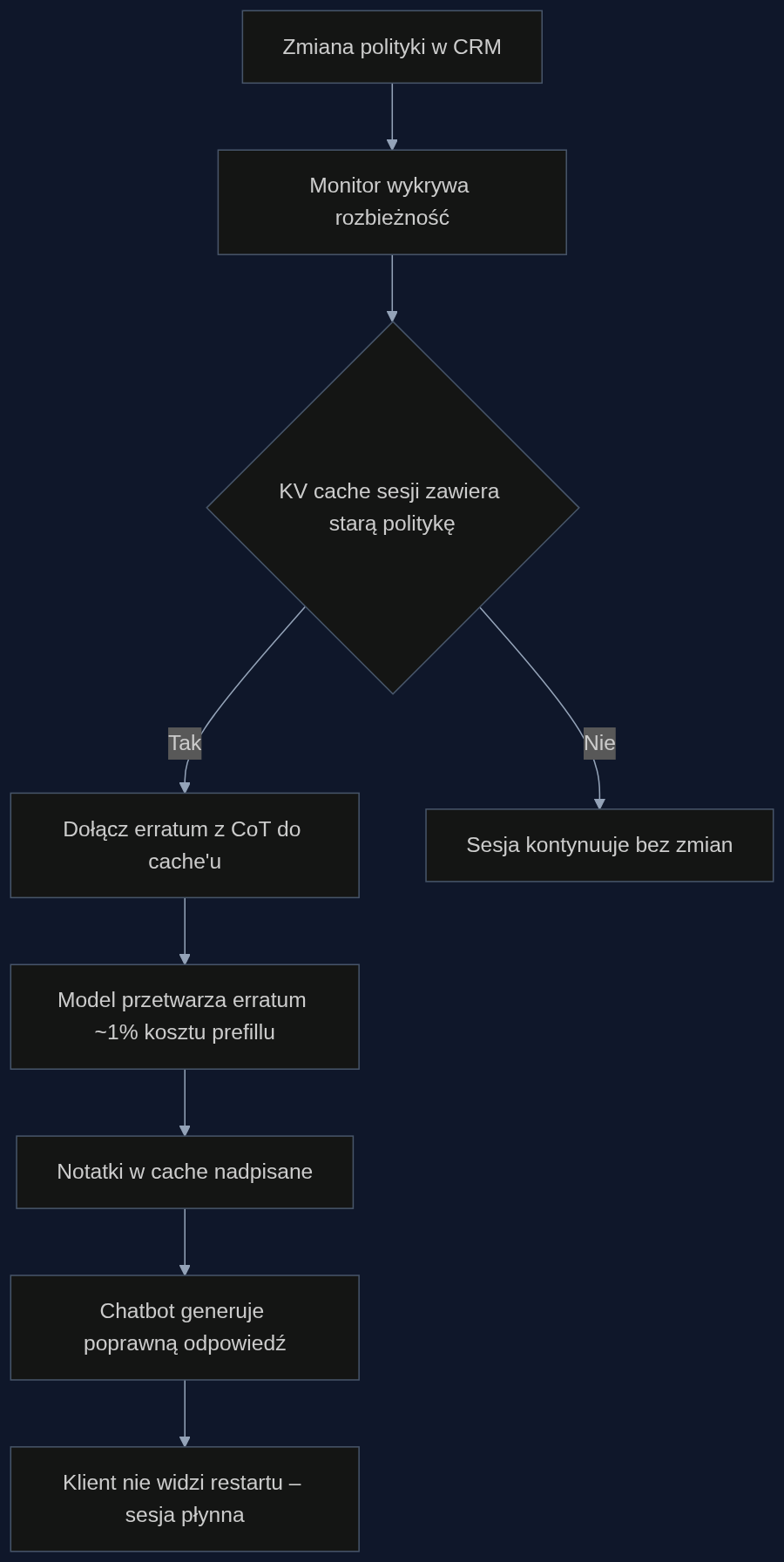
Wyobraź sobie contact center dużego e-commerce. Jest wtorek, 11:00. Dział prawny wysyła aktualizację: okres zwrotu dla elektroniki wydłuża się z 14 do 30 dni, a dodatkowo wprowadzono wyjątek dla słuchawek – zwrot do 60 dni przy wadzie fabrycznej. W systemie CRM polityka jest już zmieniona, ale setki aktywnych sesji chatbota wciąż mają w cache’u starą wersję. Klient pisze: ‘Kupiłem słuchawki miesiąc temu, jedna nie działa, chcę zwrot.’ Chatbot z nieaktualnym cache’em odpowiada: ‘Przykro nam, okres 14 dni minął, nie uznajemy reklamacji.’
Tradycyjne podejście: trzeba zrestartować sesję, przeładować nowy system prompt i przeliczyć cały kontekst od początku. Traci się historię rozmowy, klient dostaje komunikat ‘przepraszamy, nastąpił błąd, proszę zacząć od nowa’, a czas do pierwszego tokena rośnie, bo prefix caching nie zadziała – zmieniony prompt unieważnia cache.
Z edytowalnym KV cache dzieje się inaczej. System monitorujący zmiany polityk w czasie rzeczywistym wykrywa rozbieżność między aktualną polityką a tą w cache’u sesji. Do istniejącego KV cache dołącza erratum: krótką sekwencję z CoT, która mówi: ‘Poprzednia polityka zwrotów była nieaktualna. Aktualna polityka z 2025-11-12 stanowi: słuchawki – zwrot do 60 dni przy wadzie fabrycznej. Wniosek: reklamacja klienta jest zasadna, należy rozpocząć procedurę zwrotu.’ Model przetwarza to erratum w czasie poniżej 1% oryginalnego prefillu, nadpisuje notatki w cache’u i generuje odpowiedź już zgodną z nową polityką. Klient nie widzi żadnego restartu, rozmowa toczy się dalej.
Kompozycja umiejętności: gdy chatbot musi jednocześnie zmienić politykę i dodać nową funkcję
W realnym contact center zmiana polityki zwrotów często idzie w parze z nową procedurą. Na przykład: razem z wydłużeniem okresu zwrotu słuchawek, firma wprowadza automatyczne generowanie etykiety zwrotnej bez konieczności kontaktu z działem logistyki. To dwie zmiany naraz: jedna w polityce, druga w umiejętności chatbota.
Mechanizm kompozycji z paperu pozwala wstawić wstępnie obliczoną umiejętność – na przykład ‘generowanie etykiety zwrotnej’ – w dowolne miejsce kontekstu. Zespół Bojie Li pokazał, że podobieństwo logitów między wstawioną umiejętnością a pełnym przeliczeniem od zera osiąga cosinus od 0.90 do 0.999 dla dwunastu modeli. Czas do pierwszego tokena przy kompozycji skaluje się O(L), podczas gdy pełne przeliczenie to O(L^2). W praktyce: zamiast czekać, aż model przetworzy cały prompt z nową umiejętnością od początku, system bierze gotowy blok KV z prekompilowaną procedurą etykiety zwrotnej, przesuwa go pozycyjnie za pomocą RoPE i wkleja w aktywne cache’e sesji. Klient dostaje nie tylko poprawną odpowiedź o polityce zwrotu, ale też od razu wygenerowaną etykietę – bez dodatkowego opóźnienia.
Liczby, które przekonują: co to daje w skali setek sesji
Zespół Bojie Li przetestował to w produkcyjnym środowisku vLLM z prefix cachingiem. Wyniki są konkretne. Przy setkach równoległych sesji chatbota, gdzie zmiana polityki dotyka na przykład 30% aktywnych rozmów, system utrzymuje 98,5% trafień w cache. Oznacza to, że tylko 1,5% sesji wymaga pełnego przeliczenia – reszta dostaje poprawkę przez dołączenie erratum. Percentyl 90 czasu do pierwszego tokena spada o 53 do 398 razy w porównaniu z podejściem ‘zrestartuj i przelicz od nowa’. Zunifikowany agent łączący edycję i kompozycję zachowuje identyczne decyzje jak pełne przeliczenie, przy opóźnieniu niższym nawet 14,9 razy.
Dla menedżera contact center przekłada się to na dwie rzeczy. Po pierwsze, redukcję eskalacji – błędna odpowiedź, która w tradycyjnym systemie oznaczała restart sesji i zirytowanego klienta, teraz jest korygowana w locie. Po drugie, utrzymanie przepustowości – system nie traci wydajności przy dynamicznych poprawkach, bo nie unieważnia cache’u dla całych prefiksów. Z mojego doświadczenia z trzech wdrożeń chatbotów w sektorze ubezpieczeniowym, największym kosztem operacyjnym nie jest samo utrzymanie modelu, tylko eskalacje generowane przez nieaktualne odpowiedzi. Jedna eskalacja do agenta ludzkiego kosztuje średnio 12-18 złotych w kosztach pracy i utraconej sprzedaży krzyżowej. Przy 5000 sesji dziennie i 2% błędnych odpowiedzi wynikających z nieaktualnych polityk, mówimy o 100 eskalacjach dziennie – 1200 do 1800 złotych kosztu. Edytowalny cache ucina ten problem u źródła.
Podsumowanie: warto przetestować na jednej linii biznesowej
Technika edycji i kompozycji KV cache nie wymaga wymiany całego stosu technologicznego. Działa z vLLM, który już jest standardem w serwowaniu modeli open-source w wielu contact center. Jeśli twój zespół utrzymuje chatboty korporacyjne na modelach takich jak Llama czy Mistral, możesz zacząć od pilotażu na jednej linii biznesowej – na przykład reklamacje w e-commerce albo obsługa roszczeń w ubezpieczeniach. Wybierz politykę, która zmienia się co najmniej kilka razy w miesiącu, i zmierz, ile eskalacji generuje nieaktualny cache. Potem wdróż mechanizm erratum z CoT i porównaj liczby. Przy okazji sprawdź, czy twój system monitorowania polityk potrafi wykrywać rozbieżności w czasie rzeczywistym – bez tego edytowalność cache’u to tylko półśrodek. To nie jest rozwiązanie, które działa od pierwszego dnia bez przygotowania, ale w contact center, które już ma pipeline danych i system zarządzania politykami, daje wymierne oszczędności na eskalacjach i utrzymuje płynność rozmowy, której klienci oczekują.
- Korekta błędnej odpowiedzi w tej samej sesji, bez restartu rozmowy i utraty kontekstu – erratum z CoT nadpisuje notatki w KV cache
- 98,5% trafień w cache utrzymane nawet przy dynamicznych poprawkach polityk – system nie traci wydajności przy setkach równoległych sesji
- Redukcja czasu do pierwszego tokena o 53–398 razy (p90) w porównaniu z pełnym przeliczeniem – klient nie czeka na odpowiedź
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: Models Take Notes at Prefill: KV Cache Can Be Editable and Composable
Autorzy: Bojie Li
Prefix caching reuses prefill only across an exactly shared prefix, so one changed field invalidates the entire downstream cache. Yet overwriting the field’s own key/value vectors and reusing the rest leaves the model acting on the old value. The reason, established causally across four model fam…
arXiv: arxiv.org/abs/2606.17107
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}