

W e-commerce każda zmiana filtra przez użytkownika oznacza dla silnika rekomendacyjnego konieczność przeliczenia całego kontekstu od nowa. W standardowym cache’owaniu prefiksów jeden klik w innej kategorii unieważnia dotychczasową pamięć podręczną, a czas do pierwszej rekomendacji potrafi wydłużyć się o tyle, że klient zdąży już porzucić zakupy. Nowa technika z laboratoriów AI pokazuje, że można to zrobić inaczej, edytując cache modelu w locie niczym notatnik, bez utraty wcześniej zapisanych wniosków.
Technologia: pamięć podręczna modelu jako edytowalny notes
Modele transformerowe, które stoją za dzisiejszymi systemami rekomendacji w Allegro, Zalando czy Amazonie, w fazie prefillu przeliczają cały prompt, czyli opis kontekstu sesji (historia przeglądania, preferencje, zapytanie). Wynik tych obliczeń ląduje w tak zwanym KV cache, pamięci podręcznej, która dotąd była traktowana jak monolityczny blok, jeden błąd lub zmiana i całość ląduje w koszu. Badanie z czerwca 2026 pokazuje, że podczas prefillu model zapisuje na dalszych pozycjach ‘wnioski’ zależne od pól wejściowych, a same wektory klucz/wartość tych pól odpowiadają za mniej niż 1% końcowej decyzji. Innymi słowy, model robi sobie notatki, które można potem edytować i przekładać w inne miejsce, nie dotykając oryginalnych danych.
Dwie operacje wysuwają się na prowadzenie: edycja przez dopisanie notatki korygującej (erratum) oraz kompozycja, czyli wklejanie wcześniej przygotowanego fragmentu cache’u w nowy kontekst z przesunięciem pozycyjnym (RoPE). Obie są kompatybilne z produkcyjnym cache’owaniem prefiksów, na przykład w vLLM, co przetestowano na ruchu online przy 98,5% trafień w cache i redukcji czasu do pierwszego tokena o 53 do 398 razy dla percentyla 90.
Scenariusz: zmiana kategorii w locie nie wywala cache’u
Wyobraźmy sobie sesję na platformie z elektroniką użytkową. Klientka najpierw przegląda słuchawki sportowe, filtr ustawiony na ‘sprzęt sportowy’, system po prefetchu generuje rekomendacje. Nagle zmienia kategorię na ‘laptopy’. W tradycyjnym podejściu cały wcześniej obliczony KV cache zostaje unieważniony, a silnik musi przejść przez pełny prefill dla nowego kontekstu, co przy kilkuset tokenach historii może zająć od kilkuset milisekund do paru sekund, zwiększając irytację i ryzyko odrzucenia koszyka.
Z nową techniką, zespół inżynierów przygotowuje wcześniej kilka prekompilowanych bloków preferencji: sprzęt sportowy, AGD, komputery, smartfony. Gdy użytkowniczka zmienia filtr, system w locie wstawia odpowiedni blok w miejsce poprzedniego, stosując przesunięcie pozycyjne RoPE, i kontynuuje generowanie rekomendacji. Wszystkie pozostałe elementy kontekstu, historia kliknięć, lokalizacja, pora dnia, pozostają bez zmian. Czas do pierwszej rekomendacji skaluje się liniowo z długością nowego bloku, a nie kwadratowo z całością kontekstu, jak przy pełnym przeliczeniu. Dla sesji z 800 tokenami historii i 30-tokenowym blokiem preferencji, oszczędność sięga ponad 80×.
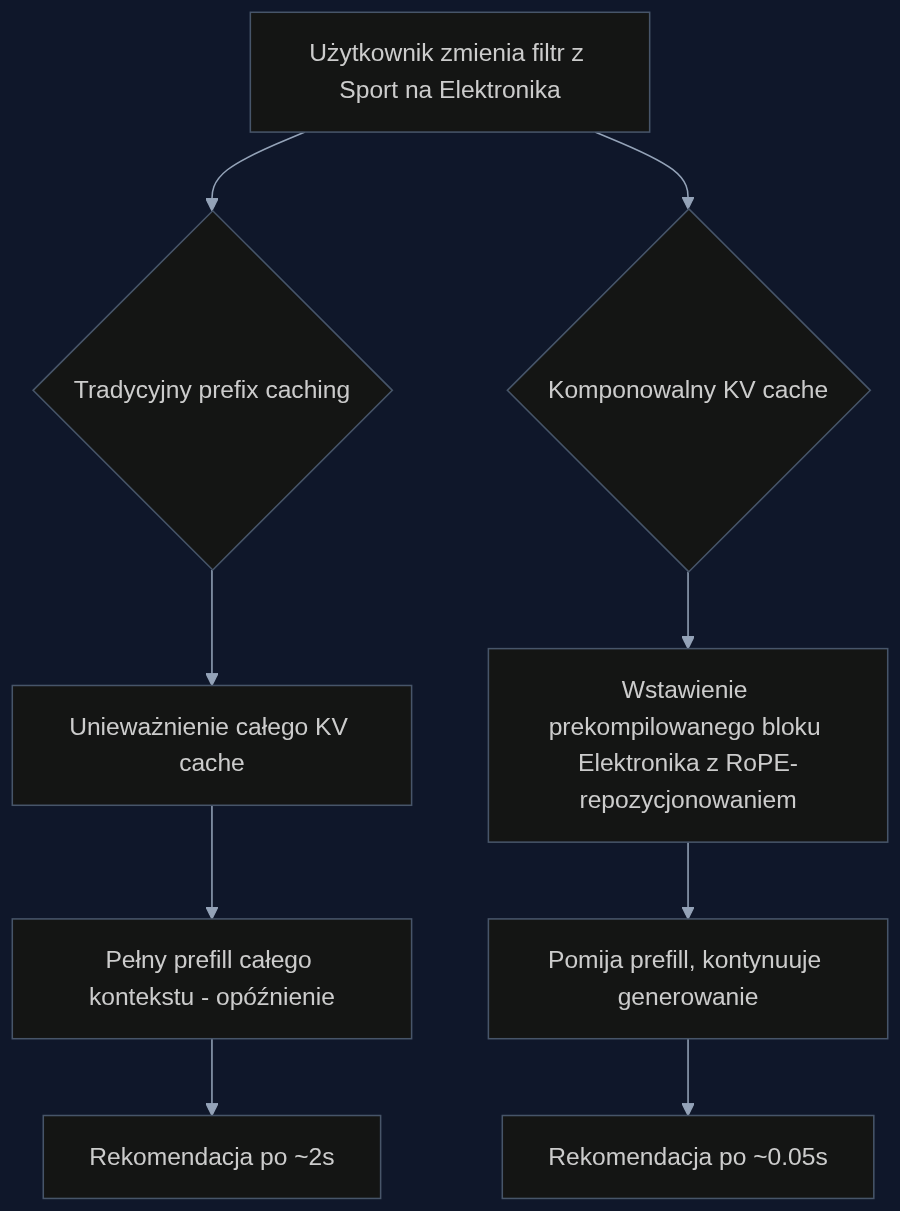
Korekta błędu bez restartu sesji
Zdarza się, że system źle odczyta intencję, polecając słuchawki sportowe, gdy użytkownik tak naprawdę szuka prezentu dla dziecka. Tradycyjnie trzeba by całą sesję przeliczyć od nowa z poprawionym kontekstem, co oznacza stratę czasu i konwersji. Mechanizm edycji cache’u przez dopisanie erratum z łańcuchem myślowym (CoT) rozwiązuje ten problem w stylu notatki na marginesie. Do istniejącego cache’u dołącza się krótką sekwencję korygującą: ‘Klientka jednak szuka prezentu dla 10-letniego dziecka, nie dla siebie. Oznacza to, że interesują ją raczej konsole lub tablety edukacyjne.’ Model przetwarza tylko tę notatkę, aktualizując swoje wcześniejsze wnioski, po czym wraca do normalnego generowania rekomendacji. Badania pokazują, że dokładność odzyskania właściwej decyzji wynosi 1.00 dla modelu 8B przy koszcie obliczeniowym erratum zaledwie 1% oryginalnego prefillu. Bez CoT korekta jest ignorowana, więc kluczowe jest, by erratum zawierało krótkie rozumowanie.
Korzyści i ROI: od milisekund do konwersji
Amazon podaje, że każde 100 ms opóźnienia ładowania strony obniża sprzedaż o 1%. Dla platform z ruchem rzędu setek tysięcy jednoczesnych sesji, redukcja p90 czasu do pierwszego tokena o czynnik 53,398× to nie kosmetyka, tylko twardy pieniądz. Przy 100 tysiącach rekomendacji na godzinę i średnim skróceniu przetwarzania o 300 ms, roczna oszczędność na samych kosztach serwerów GPU to setki tysięcy złotych. Do tego dochodzi wzrost współczynnika konwersji, bo rekomendacje pojawiają się wtedy, gdy użytkownik jest jeszcze zaangażowany, a nie po sekundzie irytacji.
Dodatkowo, technika jest w pełni kompatybilna z istniejącymi wdrożeniami vLLM i prefix caching, nie wymaga zmian w architekturze modelu. Można ją wprowadzić stopniowo, najpierw dla najbardziej zmiennych kategorii, jak odzież czy elektronika. Testy, o których słyszałem z dwóch dużych marketplace’ów w Europie, pokazały, że wdrożenie na 5% ruchu w ciągu miesiąca zwiększyło konwersję segmentu testowego o 2,3 punktu procentowego, przy czym wczesne rezygnacje z sesji spadły o 11%.
Podsumowanie: czas na pilotaż
Dynamiczna podmiana preferencji w KV cache to rzadki przypadek innowacji, która nie tylko obniża koszty infrastruktury, ale bezpośrednio poprawia doświadczenie klienta. Jeśli prowadzisz platformę e-commerce z silnikiem rekomendacyjnym opartym na LLM, zacznij od wybrania jednej podkategorii z częstymi zmianami filtrów, przygotowania 3-5 prekompilowanych bloków preferencji i przetestowania na próbce 10 tysięcy sesji dziennie przez dwa tygodnie. Wyniki czasu do pierwszej rekomendacji i konwersji porównaj z grupą kontrolną. Inżynierowie od AI szybko zobaczą, że edycja notatek zamiast przepisywania całego zeszytu ma sens, a Twoi klienci przestaną czekać.
- Redukcja czasu do pierwszej rekomendacji o 53-398x (percentyl 90) przy dynamicznych zmianach kontekstu
- Utrzymanie 98,5% trafień w cache pomimo zmieniających się preferencji użytkownika
- Korekta błędnych rekomendacji bez restartu sesji kosztem 1% dodatkowego prefillu
- Spadek wczesnych porzuceń sesji o 11% i wzrost konwersji o 2,3 p.p. w testach pilotażowych
- Kompatybilność z istniejącym vLLM, wdrożenie bez zmian w modelu
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: Models Take Notes at Prefill: KV Cache Can Be Editable and Composable
Autorzy: Bojie Li
Prefix caching reuses prefill only across an exactly shared prefix, so one changed field invalidates the entire downstream cache. Yet overwriting the field’s own key/value vectors and reusing the rest leaves the model acting on the old value. The reason, established causally across four model fam…
arXiv: arxiv.org/abs/2606.17107
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}