
Wyobraź sobie test, który zadaje osiem prostych pytań i na tej podstawie odróżnia zdrowe starzenie się od początków alzheimera z niemal stuprocentową skutecznością. Brzmi jak science fiction? Afshan Hashmi zbudowała model, który robi dokładnie to, używając danych z rutynowych badań klinicznych zebranych w ramach projektu ADNI. I, co rzadkie w świecie AI, potrafi pokazać, dlaczego podjął taką, a nie inną decyzję.
Co właściwie mierzymy, gdy mierzymy pamięć
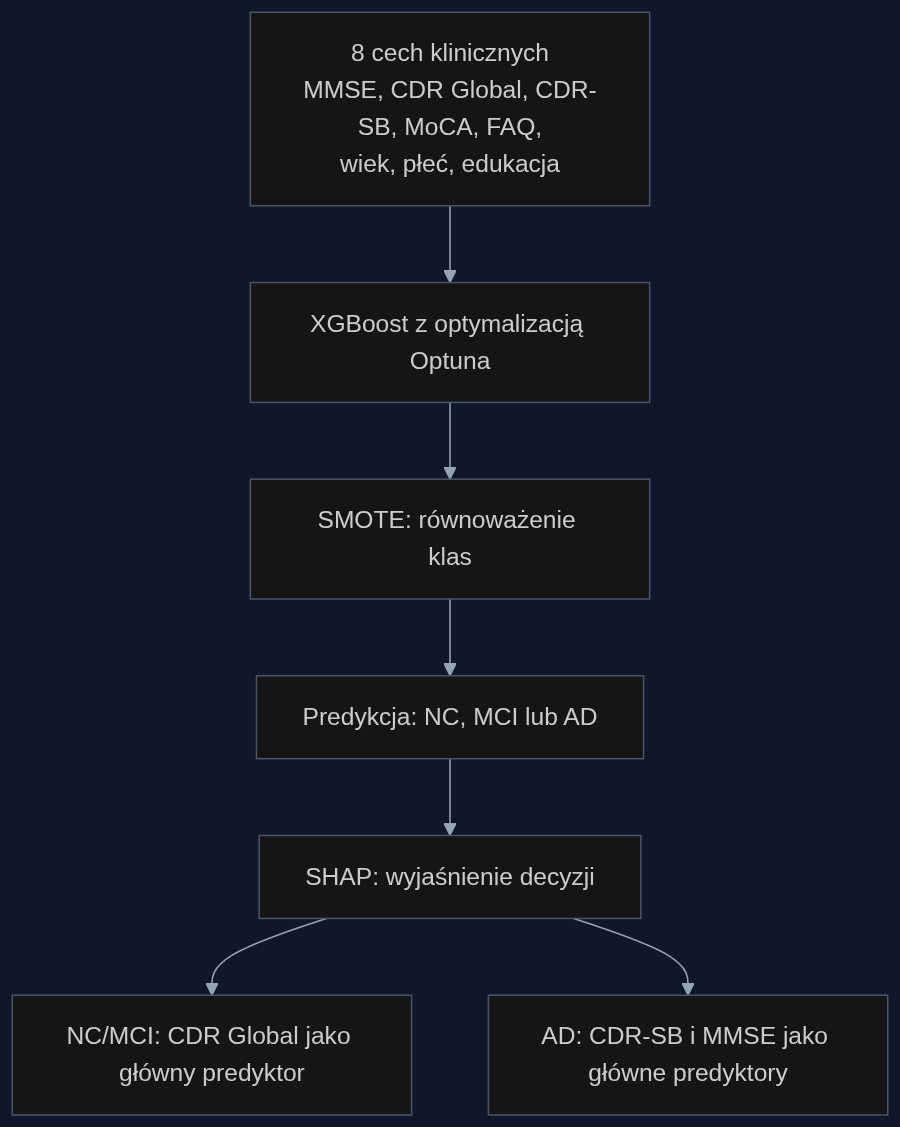
Model Hashmi opiera się na ośmiu zmiennych, które lekarz może zebrać podczas standardowej wizyty. Są wśród nich wyniki testów takich jak MMSE (30-punktowa skala oceny funkcji poznawczych), MoCA (przesiewowe badanie łagodnych zaburzeń), CDR Global (kliniczna ocena stopnia otępienia w skali 0-3), CDR Sum of Boxes (bardziej szczegółowa suma punktów z poszczególnych domen, 0-18) oraz FAQ (kwestionariusz codziennego funkcjonowania wypełniany przez opiekuna). Do tego dochodzą trzy podstawowe dane demograficzne: wiek, płeć i liczba lat edukacji.
Zestaw jest zaskakująco skromny. Żadnych biomarkerów z płynu mózgowo-rdzeniowego, żadnych skanów PET, żadnych kosztownych badań genetycznych. Tylko to, co mieści się w standardowym wywiadzie klinicznym. A jednak model XGBoost wytrenowany na tych danych osiągnął makro AUC na poziomie 0.982 na wydzielonym zbiorze testowym, co oznacza, że niemal perfekcyjnie odróżnia trzy stany: normalne funkcje poznawcze, łagodne zaburzenia poznawcze i chorobę Alzheimera.
Jak wytresować model, który nie kłamie
Kluczowym problemem w danych medycznych jest nierównowaga klas. W zbiorze ADNI było 608 osób zdrowych, 767 z MCI i tylko 266 z Alzheimerem. Gdyby model zgadywał zawsze ‘MCI’, miałby wysoką skuteczność, ale byłby bezużyteczny klinicznie. Hashmi użyła techniki SMOTE, która generuje syntetyczne próbki dla rzadszych klas, zamiast po prostu powielać istniejące dane. Dzięki temu model uczy się granic decyzyjnych, a nie zapamiętuje twarzy pacjentów.
Hiperparametry XGBoost zostały dostrojone przez Optunę w 50 próbach, co brzmi jak magia, ale w praktyce oznacza automatyczne przeszukiwanie przestrzeni parametrów w poszukiwaniu najlepszej konfiguracji. Wyniki zweryfikowano pięciokrotną walidacją krzyżową (średnie makro AUC 0.983, dokładność 0.944) oraz na oddzielnym zbiorze testowym liczącym 247 osób. Zgodność między przewidywaniami a rzeczywistością mierzona współczynnikiem kappa Cohena wyniosła 0.909, co oznacza niemal idealną zgodność po wyeliminowaniu przypadku.
Analiza SHAP zidentyfikowała CDR Global jako dominujący predyktor dla normalnych funkcji poznawczych i łagodnych zaburzeń, podczas gdy CDR-SB i MMSE wspólnie napędzały klasyfikację choroby Alzheimera.
Afshan Hashmi
arXiv:2606.03995
Czarna skrzynka, która mówi ludzkim głosem
Większość modeli uczenia maszynowego to czarne skrzynki: wiesz, co wchodzi i co wychodzi, ale nie masz pojęcia dlaczego. Hashmi użyła wartości SHAP, żeby to zmienić. SHAP to metoda wywodząca się z teorii gier, która przypisuje każdej cesze ‘wartość Shapleya’, czyli jej udział w konkretnej predykcji. Dla klinicysty oznacza to możliwość zobaczenia, które pytanie zaważyło na diagnozie.
I tu pojawia się coś, co ma sens kliniczny. Dla odróżnienia osób zdrowych od tych z MCI dominującym predyktorem był CDR Global, czyli ogólna ocena kliniczna. Ale gdy model wykrywał pełnoobjawowego Alzheimera, na pierwszy plan wysuwały się CDR Sum of Boxes i MMSE. To nie jest losowy zlepek korelacji, to hierarchia, która odzwierciedla postęp choroby. Najpierw pojawia się ogólne wrażenie kliniczne, potem szczegółowe deficyty w codziennym funkcjonowaniu i funkcjach poznawczych.
Co to znaczy dla kogoś, kto nie jest modelem
Afshan Hashmi stwierdza w swojej pracy: ‘Wyjaśnialny model uczenia maszynowego wytrenowany na rutynowych ocenach klinicznych osiąga niemal doskonałą trójklasową detekcję Alzheimera’. To zdanie jest odważne, ale poparte twardymi liczbami. 95-procentowy przedział ufności dla makro AUC na zbiorze testowym wynosi 0.965-0.995, oszacowany metodą bootstrap z tysiącem iteracji. Nawet dolna granica tego przedziału przekracza 0.96, co jest wynikiem rzadko spotykanym w tego typu klasyfikacjach.
Zastanawia mnie jedno: model trenowano na danych z ADNI, czyli na starannie wyselekcjonowanej populacji badawczej. W realnej przychodni, gdzie pacjenci przychodzą z cukrzycą, depresją i niedosłuchem, te same osiem pytań może nie wystarczyć. Hashmi nie testowała modelu na danych spoza ADNI, co jest standardowym ograniczeniem, ale też otwartym zaproszeniem do dalszych badań.
Jest też kwestia SMOTE. Generowanie syntetycznych pacjentów z Alzheimerem na podstawie 266 rzeczywistych przypadków budzi pewien niepokój – model uczy się na danych, które statystycznie przypominają prawdziwe, ale nimi nie są. W medycynie, gdzie rzadkie podtypy choroby mogą nie być reprezentowane w próbce, to ryzyko. Model czeka teraz na walidację na danych spoza ADNI.
- Model XGBoost na ośmiu rutynowych cechach klinicznych osiągnął makro AUC 0.982 w odróżnianiu NC, MCI i AD
- SHAP pokazał klinicznie sensowną hierarchię: CDR Global dla wczesnych stadiów, CDR-SB i MMSE dla zaawansowanych
- SMOTE zrównoważył klasy, ale syntetyczne dane w medycynie pozostają tematem do dyskusji
- Współczynnik kappa Cohena 0.909 oznacza niemal idealną zgodność ponad przypadkiem
Praktyczne zastosowania
Aby lepiej zrozumieć opisywaną innowację, przygotowaliśmy cztery przykłady praktycznego zastosowania tej technologii w różnych branżach:




Podsumowanie
Model Hashmi pokazuje, że nie trzeba drogich biomarkerów, żeby z wysoką skutecznością wykrywać Alzheimera na podstawie rutynowych badań. W praktyce klinicznej taki system mógłby działać jako narzędzie przesiewowe w podstawowej opiece zdrowotnej, odciążając specjalistyczne poradnie pamięci. W sektorze ubezpieczeniowym i w badaniach klinicznych nad lekami antyamyloidowymi mógłby pomóc w szybszej rekrutacji pacjentów we wczesnych stadiach choroby, gdzie interwencja ma największy sens. Najciekawsze jest jednak to, że model nie tylko klasyfikuje, ale też tłumaczy swoje decyzje – a to buduje zaufanie, bez którego żadne AI nie wejdzie do gabinetu lekarskiego.
Metryka artykułu źródłowego
Tytuł oryginalny: Early Detection of Alzheimer’s Disease Using Explainable Machine Learning on Clinical Biomarkers: A Multi-Class Classification Study Using the Alzheimer’s Disease Neuroimaging Initiative (ADNI) Dataset
Autorzy: Afshan Hashmi
Data publikacji: 4 czerwca 2026
arXiv: arxiv.org/abs/2606.03995
Napisanie tego artykułu zostało wspomagane przez sztuczną inteligencję. Treść opiera się na oryginalnym artykule naukowym, a jej dokładność została zweryfikowana automatycznie.