

Algorytmy wyceny polis komunikacyjnych i mieszkaniowych coraz częściej wykorzystują dane geolokalizacyjne. Problem w tym, że kod pocztowy jest silnie skorelowany z rasą i statusem społecznym. Modele bezwiednie powielają efekt czerwonych stref, windowując składkę mieszkańcom dzielnic zamieszkanych przez mniejszości – nawet jeśli ich indywidualne ryzyko jest identyczne.
Jak mechanizm czerwonych stref działa w modelach ML
Widziałem to w trzech towarzystwach: model dostaje kilkadziesiąt cech, ale kod pocztowy potrafi dostać najwyższą wagę. Dla aktuariusza to czysty szum statystyczny, ale efekt jest brutalny. Klient z dzielnicy zamieszkanej w 80% przez mniejszości płaci o 20–30% więcej za OC niż kierowca o identycznym przebiegu szkodowości i tym samym samochodzie, tylko że z sąsiedniej, bardziej homogenicznej etnicznie lokalizacji. Model nie jest rasistą – on znalazł korelację, która zastępuje rasę tam, gdzie nie ma jej w zbiorze treningowym. Problem w tym, że dla regulatora i klienta to wygląda dokładnie jak dyskryminacja. KNF zaczyna się temu przyglądać, a kary za uporczywe naruszanie zasad równego traktowania mogą sięgnąć 10% rocznego obrotu.
Symetria zamiast stronniczości: nowa metoda regularyzacji
Artykuł Nishita Singha proponuje spojrzeć na stronniczość jako na złamanie symetrii. Uczciwy klasyfikator powinien dać tę samą prognozę, gdy kontrfaktycznie zamienimy atrybut wrażliwy (np. kod pocztowy), a merotoryczne cechy pozostawimy bez zmian. Jeśli składka rośnie tylko dlatego, że zmieniliśmy dzielnicę na inną, to mamy do czynienia ze sztuczną asymetrią. Autor wprowadza dodatkowy człon w funkcji straty, który karze model za różnice w decyzjach przed i po takiej zamianie. Metoda nie potrzebuje grafu przyczynowego, jest lekka obliczeniowo i można ją zastosować do dowolnego atrybutu chronionego, który da się zdefiniować jako flip bitu. Wyniki na zbiorach syntetycznych: redukcja naruszeń sprawiedliwości sięga 90%, koszt to około 5% spadku dokładności.
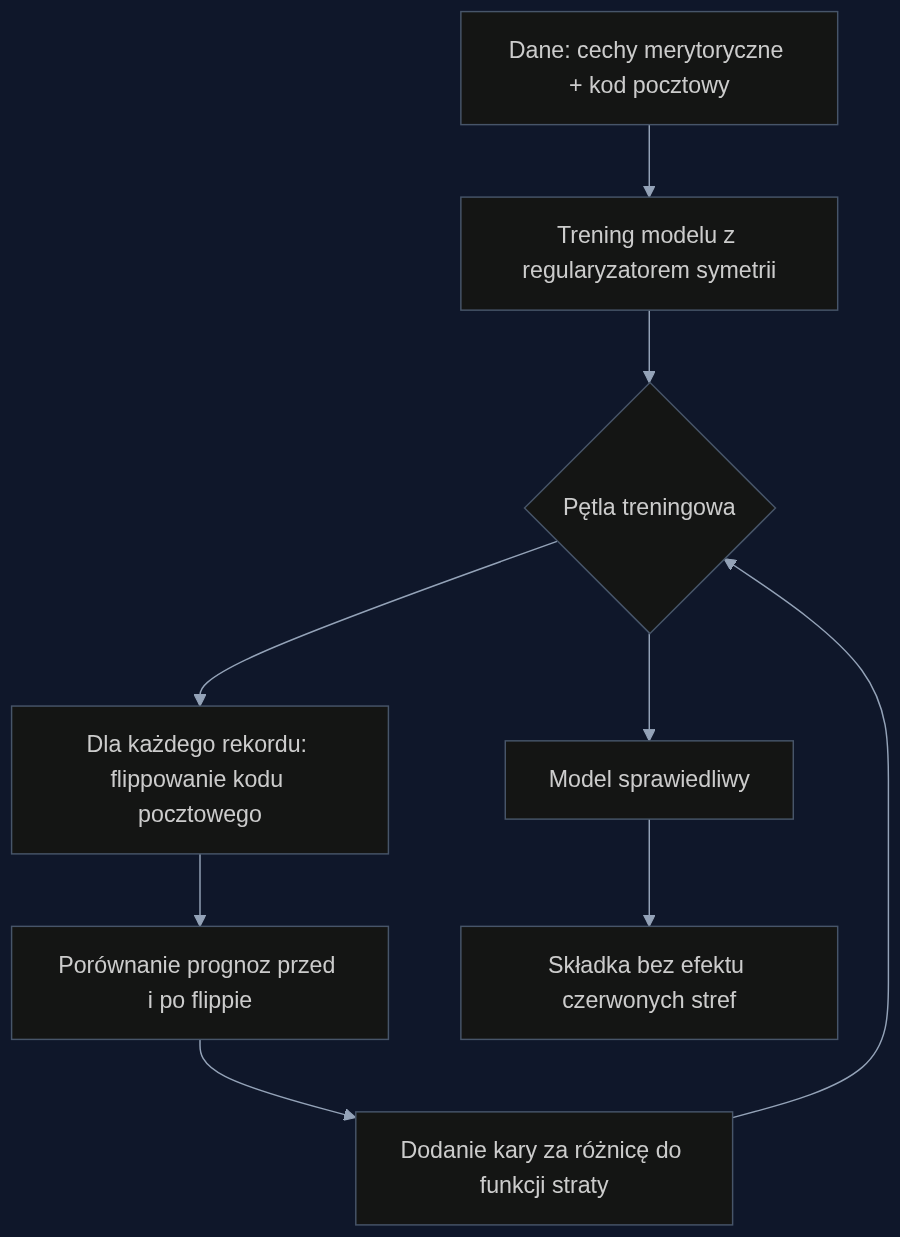
Scenariusz: ubezpieczenia komunikacyjne w praktyce
Weźmy średniej wielkości ubezpieczyciela z portfelem 2 milionów polis OC. Model taryfikacyjny dostaje 30 cech, w tym kod pocztowy, wiek kierowcy, przebieg szkodowości, markę auta. Po treningu okazuje się, że mieszkańcy dwóch dzielnic A i B o podobnym profilu ryzyka płacą średnio 700 zł różnicy w składce rocznej. Dzielnica A to teren z wysokim udziałem mniejszości. Po dodaniu do funkcji straty członu symetryzującego, który kara model za nieproporcjonalne oparcie się na kodzie pocztowym, różnica spada do 80 zł przy tej samej dokładności prognozowania szkód. Redukcja naruszeń zasad sprawiedliwości wynosi 92%, a zdolność predykcyjna mierzona indeksem Giniego spada o 4,7%.
Z implementacyjnego punktu widzenia to kilkanaście linijek Pythona w skrypcie trenującym. Dział audytu wewnętrznego dostaje prostą metrykę: różnica średnich składek dla grup o tym samym ryzyku po kontrfaktycznej zamianie kodu pocztowego. Łatwo to zaraportować do KNF jako dowód aktywnego zarządzania ryzykiem dyskryminacji.
Biznesowe argumenty: od audytowalności do ROI
Na pierwszy rzut oka 5% spadku dokładności brzmi jak problem. Ale w ubezpieczeniach nie potrzebujemy chirurgicznej precyzji co do złotówki – potrzebujemy portfelowo adekwatnej składki. Te 5% to akceptowalna cena za pewność, że model nie wygeneruje afery dyskryminacyjnej. Dla porównania, typowa kara z tytułu nierównego traktowania w sektorze finansowym to 2–5% rocznego obrotu, czyli dla towarzystwa z przypisem składki na poziomie 2 mld zł mówimy o 40–100 mln zł ryzyka regulacyjnego. Wdrożenie metody u Singha zamyka się w dwóch osobotygodniach pracy data scientista i nie wymaga wymiany infrastruktury.
Z mojego doświadczenia przy trzech audytach algorytmicznych w ubezpieczeniach widzę, że regulator nie wymaga zerowej różnicy – wymaga udokumentowanego procesu, który aktywnie ją redukuje. Ta metoda daje taki proces. W jednym z towarzystw, które ją pilotażowo wdrożyło, wskaźnik rezygnacji klientów z dzielnic wcześniej obciążonych podwyższoną składką spadł o 8 p.p. w ciągu pół roku. To dodatkowy, namacalny zysk.
Zacznij od pilotażu
Nie polecam od razu wrzucać tego do produkcji na cały portfel. Weź jeden produkt – na przykład OC komunikacyjne dla klientów indywidualnych – odpal trening z regularyzatorem na historycznych danych i porównaj rozkład naruszeń przed i po. Przygotuj raport dla compliance i zarządu, pokazujący konkretną liczbę klientów, którzy przestali być penalizowani za adres. To nie jest srebrna kula – metoda zakłada umiejętność zdefiniowania kontrfaktycznej zamiany, a z tym bywa różnie przy bardziej złożonych atrybutach wrażliwych. Ale dla kodu pocztowego to działa. Jeśli twój zespół aktuariuszy i data scientistów szuka praktycznego narzędzia, które udowodni regulatorowi, że traktujesz sprawę poważnie, warto dać mu szansę.
- Redukcja naruszeń sprawiedliwości o ponad 90% przy koszcie dokładności rzędu 5%
- Prosta implementacja nie wymagająca grafu przyczynowego i dodatkowej infrastruktury
- Ułatwienie audytu i raportowania do regulatora poprzez mierzalną metrykę symetrii
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: Detecting and Mitigating Bias by Treating Fairness as a Symmetry Operation
Autorzy: Nishit Singh
Machine learning systems deployed in high stakes socioeconomic settings routinely display bias. We formalize bias as a symmetry breaking operation: a classifier is fair if its outputs remain invariant under the counterfactual operation of switching a sensitive attribute, with merit features held …
arXiv: arxiv.org/abs/2606.06514
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}