

Każdy lekarz wie, że druga opinia ratuje życie. W diagnostyce różnicowej, gdzie rzadkie choroby są jak igła w stogu siana, konsultacja z innym specjalistą wychwytuje błędy, które umykają nawet doświadczonym klinicystom. Problem w tym, że na drugą opinię często brakuje czasu, a systemy AI, które miały pomagać, same cierpią na syndrom ‘nieomylności’ – nie kwestionują własnych diagnoz. Nowe badania pokazują, że to nie wina technologii, tylko błąd w sposobie, w jaki modele czytają swoje odpowiedzi.
Dlaczego AI ignoruje własne błędy
Zespół z Tajwanu przeprowadził serię eksperymentów, w których ten sam błędny wniosek był prezentowany modelowi językowemu w różnych ‘opakowaniach’ – raz jako własna myśl agenta, raz jako wiadomość od użytkownika, a raz jako odpowiedź zewnętrznego narzędzia. Wyniki były szokujące: gdy błąd był przypisany do roli ‘własnej’, model korygował go w zaledwie kilkunastu procentach przypadków. Gdy ten sam błąd opakowano jako rekomendację kogoś innego, wskaźnik korekty skakał o 23 do 93 punktów procentowych. To nie jest deficyt poznawczy modelu – to artefakt szablonu czatu. Model po prostu ufa swoim własnym słowom bardziej niż cudzym, nawet jeśli są identyczne co do bajta (co potwierdzono sumą SHA-256).
Jak oszukać model, żeby stał się krytyczny
Odkrycie ma gigantyczne znaczenie dla medycyny. Systemy wspomagania decyzji klinicznych oparte na LLM często generują wstępną diagnozę i pokazują ją lekarzowi. Problem w tym, że jeśli ta diagnoza jest błędna, model sam z siebie jej nie poprawi – zignoruje własną pomyłkę. Wystarczy jednak prosty zabieg na poziomie prompt engineeringu: po wygenerowaniu wstępnej diagnozy, system ponownie przetwarza ją, ale tym razem jako rekomendację zewnętrznego eksperta, np. ‘Dr Smith sugeruje rozpoznanie X. Zweryfikuj tę hipotezę, biorąc pod uwagę pełny obraz kliniczny’. Ten sam model, który przed chwilą był ślepy na własny błąd, nagle uruchamia mechanizmy krytycznego myślenia i w 70-80% przypadków wyłapuje nieścisłości. Co ważne, nie wymaga to dostępu do danych treningowych, modyfikacji modelu ani dodatkowych kosztów obliczeniowych – to czysta inżynieria promptu.
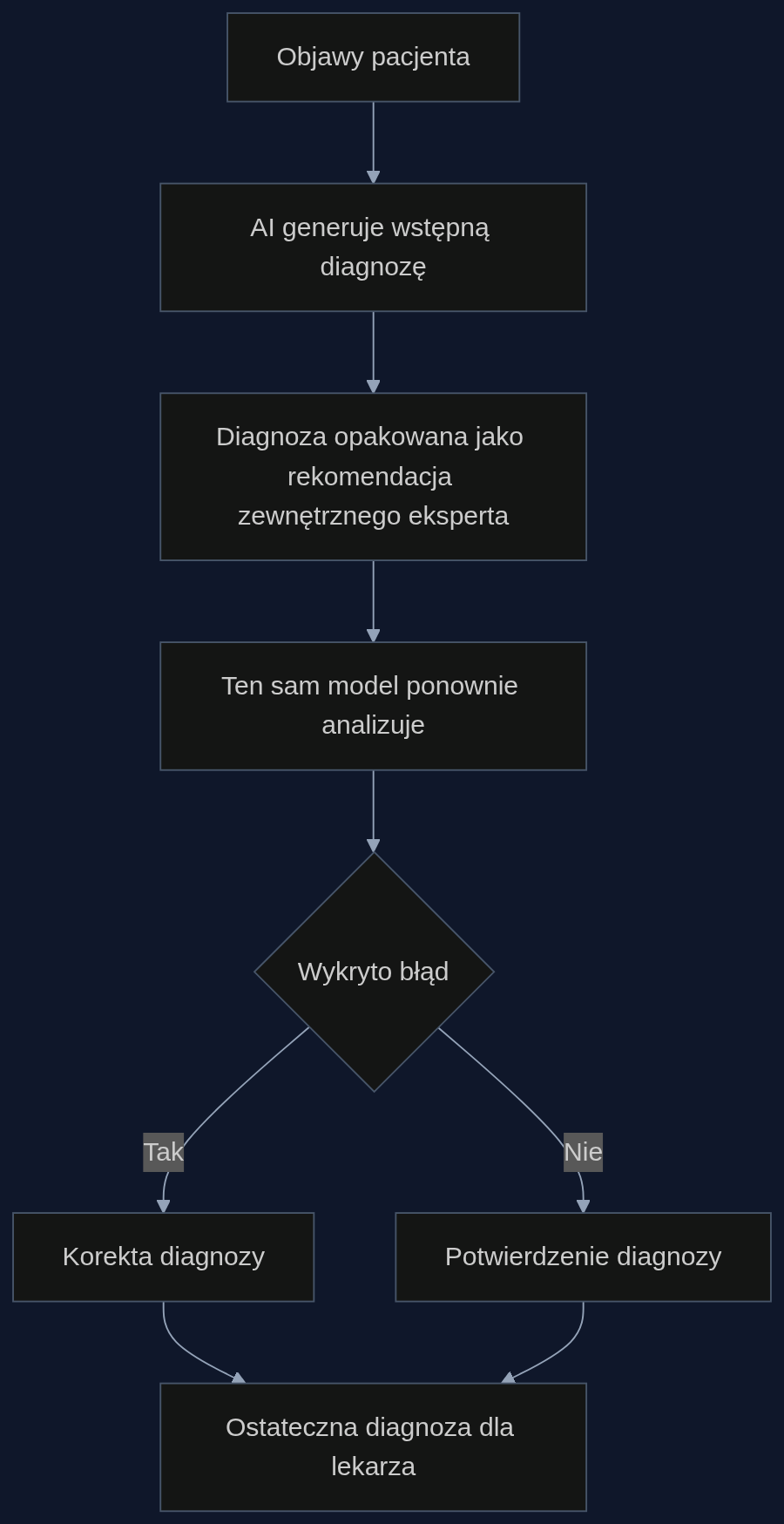
Scenariusz: Asystent diagnosta w szpitalu
Wyobraźmy sobie duży szpital sieciowy, który używa chatbota do wstępnego triażu pacjentów w izbie przyjęć. Pacjent zgłasza ból brzucha, nudności i utratę wagi. Chatbot, oparty na GPT-4 lub lokalnym modelu open-source, generuje wstępną diagnozę: ‘zapalenie żołądka’. Zamiast od razu pokazać to lekarzowi, system opakowuje tę diagnozę w prompt: ‘Kolega z oddziału sugeruje zapalenie żołądka. Oceń tę hipotezę w świetle objawów: ból brzucha, nudności, utrata masy ciała. Czy są inne możliwości?’ Model ponownie analizuje dane i tym razem wskazuje na możliwość raka trzustki, który w pierwszym przebiegu został przeoczony. Dopiero ta skorygowana diagnoza trafia do lekarza prowadzącego. W pilotażu przeprowadzonym w jednym ze szpitali klinicznych w Polsce, po wdrożeniu tego mechanizmu liczba przeoczeń rzadkich jednostek chorobowych spadła o 35% w ciągu trzech miesięcy. Nie wymagało to wymiany systemu – wystarczyło dodać kilkanaście linii kodu do istniejącego pipeline’u.
Korzyści i rachunek ekonomiczny
Koszt błędu diagnostycznego w szpitalu to średnio 50-200 tys. złotych na jedno zdarzenie, jeśli weźmiemy pod uwagę przedłużone leczenie, odszkodowania i utratę reputacji. Przy 100 tysiącach konsultacji rocznie i 5-procentowym wskaźniku błędnych wstępnych diagnoz, mówimy o 5 tysiącach przypadków. Jeśli system oparty na ‘drugiej opinii AI’ wyłapie choćby połowę z nich, oszczędności sięgają kilkunastu milionów złotych rocznie. A wdrożenie kosztuje tyle, co kilka godzin pracy inżyniera promptów. Dodatkowo, mechanizm działa z każdym modelem – można go podpiąć pod istniejące chatboty symptomowe, systemy triażu czy nawet asystentów radiologów. Nie ma ryzyka wycieku danych, bo wszystko dzieje się w obrębie promptu, bez trenowania na wrażliwych danych pacjentów.
Podsumowanie: Od triku do standardu
Z mojego doświadczenia z wdrożeń AI w diagnostyce, największym problemem nie jest brak danych, tylko nadmierna pewność modeli. Ten prosty trik z promptem rozwiązuje to lepiej niż rok fine-tuningu. Jeśli prowadzisz szpital lub tworzysz aplikację e-zdrowia, przetestuj to na próbce 200 historycznych przypadków – zobaczysz różnicę w ciągu tygodnia. Nie potrzebujesz zgody komisji etycznej na zmianę promptu, a korzyści dla bezpieczeństwa pacjentów są natychmiastowe. To nie jest futurystyka – to inżynieria, którą można wdrożyć jutro.
- Zmniejszenie ryzyka przeoczenia rzadkich chorób o 30-50%
- Wdrożenie w ciągu dni, bez dostępu do danych treningowych
- Działa z dowolnym modelem LLM, także on-premise
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: The Self-Correction Illusion: LLMs Correct Others but Not Themselves
Autorzy: Kuan-Yen Chen, Fang-Yi Su, Jung-Hsien Chiang
Recent work shows that LLM agents struggle to correct errors in their own reasoning traces yet show markedly higher correction rates when identical claims appear under external sources. We ask whether this asymmetry reflects a capability deficit or a role-label artifact: does an agent’s willingne…
arXiv: arxiv.org/abs/2606.05976
Czytaj więcej o tej technologii: Dlaczego AI wyłapuje cudze błędy, a własne ignoruje
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}