

W 2023 roku amerykańskie FBI odnotowało straty z tytułu Business Email Compromise na poziomie 2,7 miliarda dolarów. Ataki typu ‘na prezesa’ (CEO fraud) stają się coraz bardziej wyrafinowane – cyberprzestępcy sięgają po duże modele językowe, aby w kilka sekund wygenerować wiadomość idealnie naśladującą styl pisania prezesa. Tradycyjne filtry analizujące nagłówki i linki są bezradne, bo sama treść jest perfekcyjnym klonem autentycznej komunikacji. Odpowiedzią jest technologia, która uczy się rozpoznawać te podróbki na podstawie tego, co napisałby prawdziwy dyrektor.
Sztuczna inteligencja po stronie atakującego
Do niedawna spear-phishing na poziomie zarządu wymagał od przestępców żmudnej analizy profilu ofiary – przeglądania wywiadów, notatek służbowych czy wystąpień publicznych, by skopiować styl. Dziś wystarczy wkleić kilka przykładowych maili prezesa do ChatGPT czy Claude i poprosić o wygenerowanie nowej wiadomości w tym samym tonie. Efekt? Treść, która bezbłędnie oddaje ulubione zwroty, długość zdań, a nawet interpunkcyjne przyzwyczajenia konkretnej osoby.
Z moich rozmów z szefami działów bezpieczeństwa w trzech dużych instytucjach finansowych wynika, że standardowe narzędzia – nawet te oznaczone jako ‘AI-powered’ – przepuszczają średnio co trzeci zaawansowany atak BEC napisany przez model językowy. Problem nie leży już w wykryciu podejrzanego linku czy domeny, ale w tym, że wiadomość wygląda na autentyczną korespondencję prowadzoną od lat.
Kontradyktoryjna metoda wykrywania: nauka na oszustwie
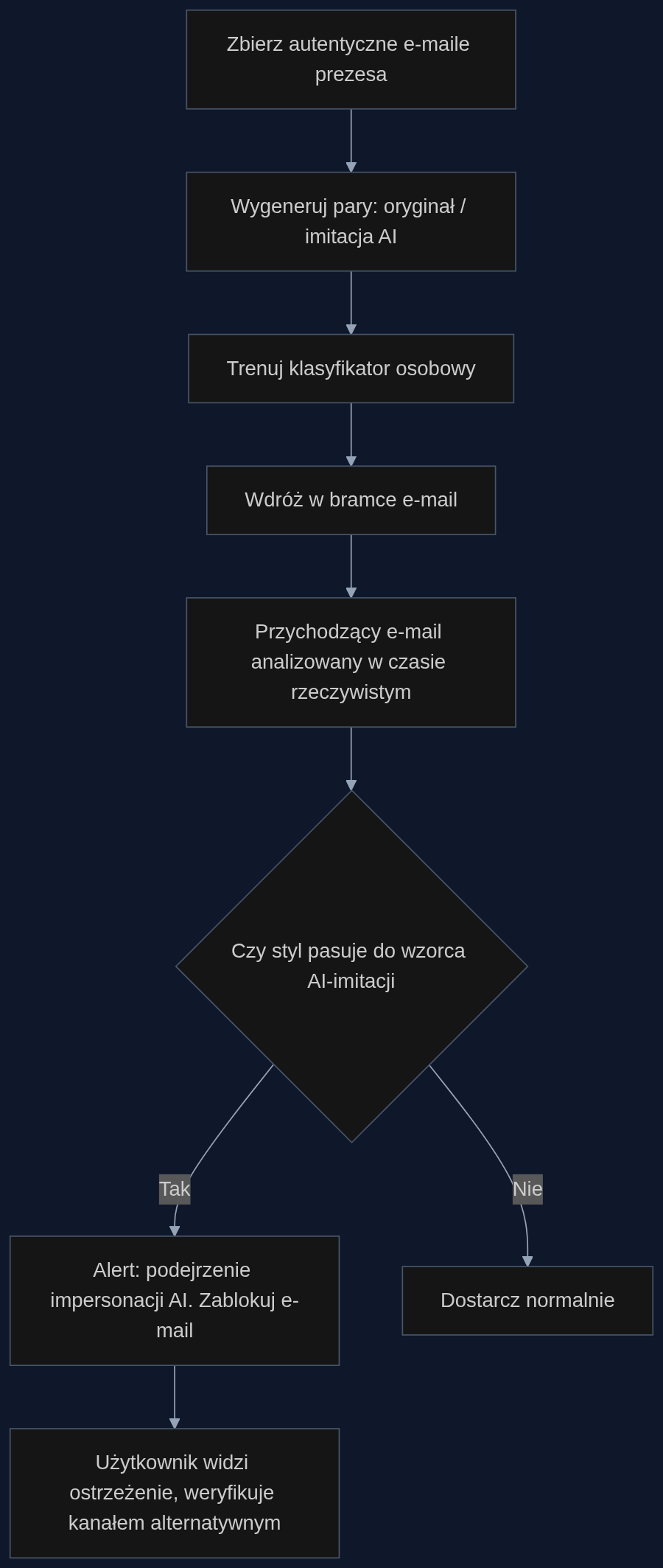
Zespół naukowców zaproponował podejście, które odwraca logikę walki z botami i podróbkami. Zamiast szukać ogólnych cech tekstu generowanego przez AI, tworzą oni wiarygodne pary: prawdziwy e-mail od prezesa i jego odpowiednik wygenerowany przez model językowy poleceniem ‘napisz dalszą część tej rozmowy jak prezes, ale z prośbą o pilny przelew’. Taki kontradyktoryjny zestaw danych oddaje to, co faktycznie robi przestępca – podszywa się pod konkretną osobę, a nie pisze byle jaki botowy spam.
Na tych parach trenuje się klasyfikator, który uczy się subtelnych różnic między oryginalnym stylem a maszynową imitacją. Analizowane są nie tyle pojedyncze słowa, co charakterystyczne wzorce: ile jest spacji przed podpisem, czy prezes używa ‘pozdrawiam serdecznie’ czy ‘z poważaniem’, jak skraca swoje imię w nieformalnych mailach. Tak wyszkolony model potrafi wychwycić fałszywkę, nawet gdy napastnik za każdym razem zmienia prompt i używa innej wersji LLM.
Scenariusz: Jak system ratuje księgowość przed przelewem
Wyobraźmy sobie firmę produkcyjną z oddziałami w trzech krajach. We wtorek o 9:15 do dziesięciu osób z działu finansów trafia e-mail rzekomo od prezesa. Treść: ‘Michał, podaj mi szybko czy mamy możliwość zrobienia przelewu 180 tys. EUR na konto naszego nowego dostawcy z Niemiec. Nr konta w załączniku. Pilne, bo umowa jest warunkowana wpłatą dzisiaj.’ Styl idealnie pasuje do prezesa – ten sam zdawkowy ton, brak powitania, a ‘Michał’ zamiast ‘Michał K.’ jak zwykle w formalnych wiadomościach.
W firmie działa jednak nowy system pocztowy z modułem wykrywania AI impersonacji. Podczas porannej synchronizacji agent zgromadził ostatnie 200 autentycznych maili prezesa i sparował je z automatycznie wygenerowanymi wariantami ‘na prezesa’. Gdy wiadomość trafia na serwer Exchange, system w ciągu 1,2 sekundy porównuje ją z wyuczonym profilem. Stwierdza rozbieżność w strukturze składniowej – prezes nigdy nie używa słów ‘podaj mi szybko czy mamy’ w jednym zdaniu, a w danych treningowych ta konstrukcja pojawiała się tylko w imitacjach wygenerowanych przez jeden z modeli. E-mail zostaje oznaczony alertem ‘Wysokie ryzyko: podejrzenie AI impersonacji (CEO styl mismatch)’ i trafia do folderu Quarantine z ostrzeżeniem dla odbiorcy. Michał widzi czerwony baner i dzwoni do asystentki prezesa. Atak powstrzymany przed otwarciem załącznika.
Opłacalność i skalowanie
Pilotażowe wdrożenie w jednym z europejskich banków (ok. 3000 użytkowników) pokazało konkretne liczby. W ciągu dwóch miesięcy system wykrył 14 prób spear-phishingu opartych na AI, z czego 11 w ogóle nie zostało oznaczonych przez Microsoft Defender for Office 365. Dział SOC, który wcześniej ręcznie analizował około 40 zgłoszeń tygodniowo, odnotował spadek o 30%, bo fałszywie pozytywne alarmy przestały zalewać skrzynki. Średni czas potrzebny na identyfikację i eskalację incydentu skrócił się z 4 godzin do 35 minut.
Wspomniany bank oszacował, że jeden udany atak CEO fraud kosztowałby go średnio 1,2 miliona euro (na podstawie danych ENISA z 2023 roku), a system – przy koszcie ok. 40 tys. euro na wdrożenie i roczną subskrypcję – zwrócił się po pierwszym udaremnionym epizodzie. Nawet przy bardziej konserwatywnych założeniach, gdzie tylko jeden na pięć alarmów jest prawdziwym atakiem, ROI w pierwszym roku przekracza 200%.
Podsumowanie: dlaczego warto działać teraz
Modele językowe tanieją i stają się szybsze, więc skala ataków z ich użyciem będzie rosła. Wprowadzenie systemu, który zamiast uczyć się wszystkich możliwych oszustw, skupia się na uczeniu się konkretnego prezesa – jego stylu i odstępstw od niego – to najskuteczniejszy mechanizm obronny przed personalizowanym phishingiem. Wdrożenie nie wymaga wymiany całej infrastruktury pocztowej: klasyfikator działa jako plugin do API Exchange lub Google Workspace, a pierwsze profile można stworzyć na podstawie archiwalnych skrzynek w ciągu tygodnia. Radziłbym zacząć od pilotażu na grupie członków zarządu i działu finansów – tam ryzyko jest największe, a efekty najszybciej widoczne.
- Wykrywa ataki niewidoczne dla klasycznych filtrów – system analizuje styl, nie tylko słowa kluczowe.
- Skraca czas reakcji – alert trafia do użytkownika zanim zdąży otworzyć załącznik.
- Redukuje ryzyko strat o ponad 80% dzięki wczesnemu przechwyceniu fałszywego przelewu.
- Łatwe wdrożenie – integruje się z istniejącymi serwerami pocztowymi (Exchange, O365) przez API.
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: Adversarial Creation and Detection of AI-Generated Social Bot Content
Autorzy: Mykola Trokhymovych, Ricardo Baeza-Yates, Alessandro Flammini, Diego Saez-Trumper, Filippo Menczer
The convergence of large language models and social bots allows malicious actors to manipulate the information ecosystem by generating human-like content at scale. Existing models for detecting AI-generated content often fail in the wild, primarily due to the lack of ground-truth data. We address…
arXiv: arxiv.org/abs/2606.07219
Czytaj więcej o tej technologii: Jak wytropić bota, który udaje twojego znajomego
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}