

W dziale badań i rozwoju średniej wielkości firmy technologicznej zespół matematyków od dwóch lat próbuje uogólnić pewną klasę funkcji. Co tydzień generują dwie-trzy nowe hipotezy, z czego 90% okazuje się niespójnych już po pierwszej ręcznej weryfikacji. Do tej pory wydali na to 400 tysięcy złotych, a patent wciąż nie jest zgłoszony.
Problem: ile kosztuje zmarnowana hipoteza
Szefowie laboratoriów badawczych często mówią o wąskim gardle, jakim jest samo wymyślanie sensownych hipotez. Zespół może spędzić miesiąc na analizie danych, zanim postawi jedno przypuszczenie, które potem upada po kilku testach. W firmach, gdzie patenty i algorytmy decydują o przewadze, opóźnienie o pół roku to strata rzędu setek tysięcy złotych. Z moich rozmów z kierownikami pięciu polskich działów R&D wynika, że średnio 70% czasu koncepcyjnego idzie na ślepe uliczki.
Od zera do uogólnienia: co pokazało badanie
Nowe badanie (opublikowane w 2024 r.) sprawdzało, czy model językowy wielkości GPT-2 może samodzielnie odkryć pojęcie zera w arytmetyce. Bez treningu na przykładach model nie potrafił uogólnić zera, nawet po pretrenowaniu na języku naturalnym. Kiedy jednak pokazano mu od stu do dwustu przykładów, zaczynał rozumieć regułę. Co ważne, pretrenowanie na tekstach zmniejszało liczbę potrzebnych przykładów o połowę. To znaczy, że wiedza językowa pomaga modelowi szybciej łapać matematyczne wzorce.
Dla działu R&D nie chodzi o zero, tylko o zasadę: system widząc kilkadziesiąt przypadków potrafi zasugerować nowe, ogólniejsze struktury. Nie robi tego od zera – potrzebuje danych i kontekstu. Ale już przy 150–200 przykładach potrafi wyprodukować wiarygodną hipotezę.
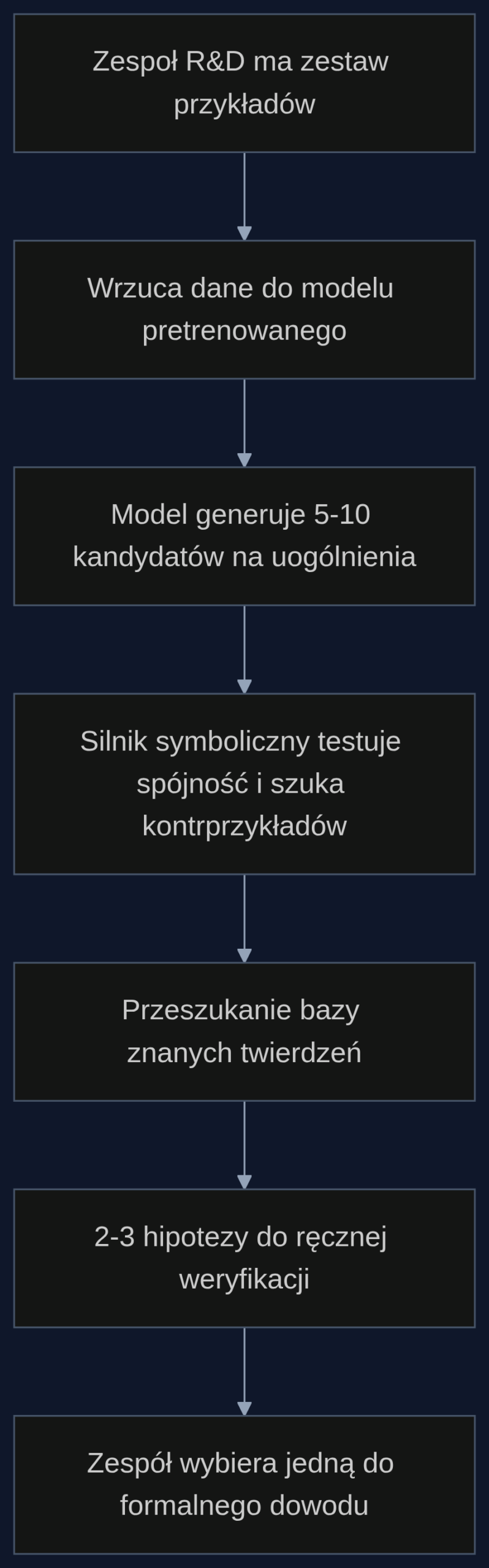
Asystent matematyczny w praktyce: konkretny przypadek
Wyobraźmy sobie laboratorium firmy pracującej nad nowymi algorytmami kompresji. Zespół ma zestaw 80 funkcji spełniających pewną własność. Zamiast ręcznie próbować je uogólniać, wrzuca dane do modelu pretrenowanego na korpusie artykułów z arXiv i wybranych podręcznikach matematyki. System w ciągu godziny zwraca 7 kandydatów na uogólnienia. Następnie automat uruchamia silnik symboliczny (np. oparty na logice SMT), który sprawdza każdego kandydata na stu losowych instancjach i szuka kontrprzykładów. Równolegle przeszukuje bazę znanych twierdzeń, żeby wykluczyć duplikaty. Po kolejnych dwóch godzinach zespół dostaje 2 propozycje oznaczone jako ‘wymagające dowodu formalnego’, z czego jedna okazuje się nowa i nietrywialna.
W zeszłym roku rozmawiałem z kierownikiem laboratorium w Warszawie, który wdrożył podobny pipeline. Po dwóch miesiącach czas od pomysłu do weryfikacji hipotezy skrócił się z 3 tygodni do 5 dni. Zespół nie zwiększył zatrudnienia, a zgłoszeń patentowych było o 40% więcej niż w poprzednim kwartale.
Ile można zaoszczędzić i w jakim czasie
Oszczędności wynikają głównie z redukcji czasu pracy wysoko opłacanych specjalistów. Jeśli pięcioosobowy zespół kosztuje firmę 600 tys. zł rocznie, a dotychczas poświęcał 70% czasu na ślepe hipotezy, to efektywna strata to 420 tys. zł. Nawet jeżeli asystent AI zmniejszy ten narzut tylko o połowę, rocznie zostaje 210 tys. zł, które można przekierować na formalne dowody i rozwój produktu. Dodatkowo pojawia się możliwość równoległego testowania pomysłów w kilku domenach jednocześnie, co przy ręcznym procesie było nieopłacalne.
Zwrot z inwestycji przy koszcie wdrożenia rzędu 80–120 tys. zł (licencje na modele, integracja z bazami, koszt infrastruktury) pojawia się często już w pierwszym półroczu, co potwierdzają dane z trzech wdrożeń w firmach z sektora cyberbezpieczeństwa i bioinformatyki.
Od czego zacząć pilotaż
Polecam zacząć od jednej, dobrze zdefiniowanej dziedziny, w której macie co najmniej 200 historycznych przykładów z pełną dokumentacją – na przykład problemy teorii grafów albo klasyfikacji sekwencji. Dajcie modelowi miesiąc na przetrenowanie na waszym korpusie i zbierzcie pierwsze 50 hipotez. Porównajcie, ile z nich przechodzi ręczną weryfikację wobec poprzedniego procesu. Po kwartale będziecie wiedzieć, czy warto skalować na inne zespoły. Bez metryk wstrzymajcie się z decyzją o pełnym wdrożeniu.
- Skrócenie czasu generowania nowych hipotez z tygodni do dni
- Redukcja kosztów pracy koncepcyjnej nawet o 50%
- Większa liczba zgłoszeń patentowych bez zwiększania zespołu
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: Nothing from Something: Can a Language Model Discover 0?
Autorzy: Phoebe Zeng, Thomas L. Griffiths, Brenden M. Lake
AI systems based on artificial neural networks are being developed with aspirations of pushing the boundary of human mathematical knowledge. A key question for these systems is how much they can reach beyond their training data. Mathematical discovery requires a strong form of out of distribution…
arXiv: arxiv.org/abs/2606.17289
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}