
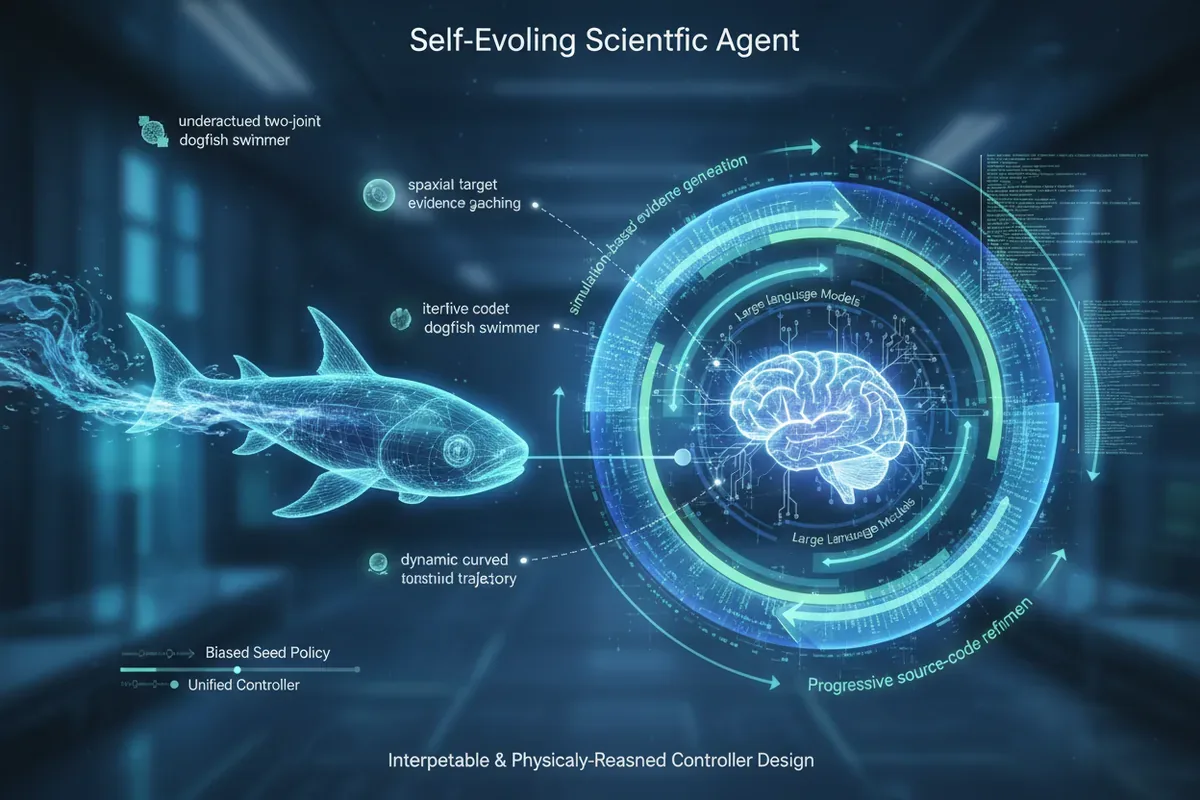
Wyobraźcie sobie program, który nie uczy się przez milion prób i błędów, tylko czyta wyniki symulacji jak raport z eksperymentu i na tej podstawie przepisuje własny kod. Zespół Słońca, Guo, Yu i Yanga pokazał, że taki agent potrafi samodzielnie wymyślić sposób pływania dla robotycznej ryby, a jego odkrycie działa od razu na zupełnie nowych trasach i w dynamicznych pościgach.
Od rybiego ogona do uniwersalnego sterownika
Mechanika płynów nie ułatwia zadania: dwustawowy pływak, który ma tylko dwa przeguby i żadnej płetwy sterowej, teoretycznie nie powinien łatwo skręcać. To tak zwany układ niedosterowany (underactuated), gdzie liczba dostępnych napędów jest mniejsza niż liczba stopni swobody. Badacze dali agentowi na start prostą strategię napędową, która potrafi płynąć do przodu, ale ma silny bias skręcania tylko w jedną stronę. Resztę miał odkryć sam.
Zadanie nie było banalne: robotyczny rekin musiał trafiać do celów rozrzuconych w różnych punktach przestrzeni, używając tylko ruchów tułowia. Agent nie mógł po prostu zapamiętywać trajektorii: symulacja stawiała przed nim za każdym razem nowy statyczny cel albo krzywoliniową ścieżkę, którą musiał śledzić w czasie rzeczywistym.
Ewolucja kodu, nie wag
Zwykle w takich zadaniach stosuje się głębokie uczenie przez wzmacnianie: sieć neuronową trenuje się miesiącami, a na końcu dostajemy czarną skrzynkę, która działa, ale nikt nie wie dlaczego. Tutaj architektura była zupełnie inna. Agent, napędzany dużym modelem językowym, generował jawny kod źródłowy strategii sterowania, a potem testował go w symulacji fizycznej.
Po każdej próbie analizował, co poszło nie tak, patrzył na trajektorie, siły i momenty, a następnie samodzielnie wprowadzał poprawki do kodu. To trochę jak młody inżynier, który puszcza prototyp w basenie, ogląda nagranie i wraca do laptopa, żeby zmienić kilka linijek w sterowniku. Tyle że tu wszystko działo się automatycznie, bez udziału człowieka.
Choć głębokie uczenie przez wzmacnianie oparte na danych może optymalizować złożone polityki sterowania, odkrycia naukowe w systemach fizycznych wymagają łańcucha rozumowania łączącego dowody fizyczne z ustrukturyzowanymi architekturami sterowania.
Boai Sun, Wenjin Guo, Zongmin Yu, Liu Yang
Abstract
Co agent zobaczył w danych z symulacji
Najciekawsze jest to, co ostatecznie powstało. Polityka sterowania nie była przypadkowym zlepkiem reguł; wyłoniła się z niej struktura z wyraźną architekturą fizyczną. Agent odkrył, że kluczem jest propagacja fali biegnącej wzdłuż ciała (jak u prawdziwych ryb), ale z dodatkiem sprzężenia zwrotnego od prędkości kątowej i podpisaną średnią krzywizną ogona.
Do tego doszedł mechanizm, który autorzy nazywają ‘adaptacyjną ulgą rytmu’: gdy pływak jest blisko celu, automatycznie zmniejsza częstotliwość ruchów ogona, żeby nie przestrzelić. Wszystko to wyrażone jest w czytelnym, matematycznym kodzie, a nie w macierzy wag neuronowych. Można prześledzić każdą decyzję.
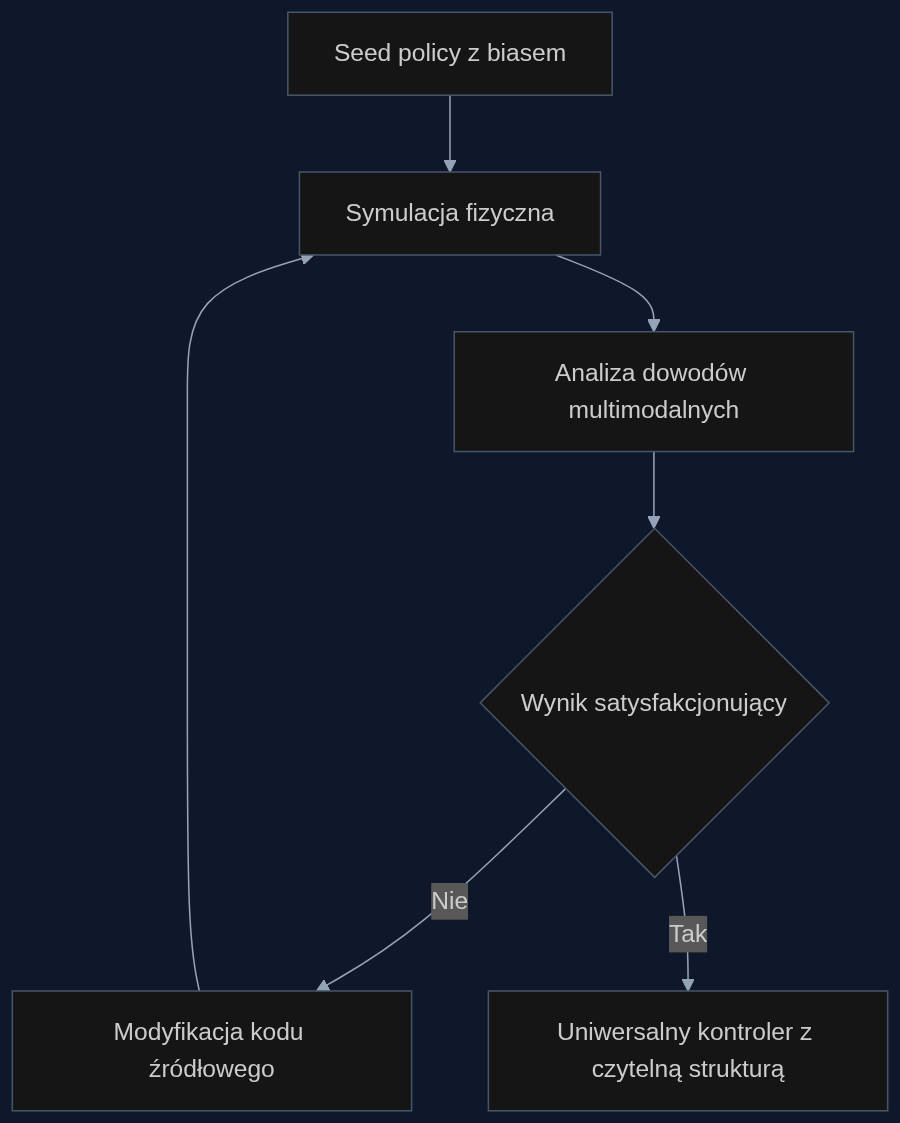
Sukces tam, gdzie sieci neuronowe mają kłopot
Standardowe podejścia oparte na danych często nie radzą sobie z generalizacją: wytrenowany model potrafi działać tylko w warunkach zbliżonych do tych z treningu. Tymczasem agent opracował uniwersalny sterownik, który bez żadnego dodatkowego uczenia radził sobie z zupełnie nowymi statycznymi celami i z dynamicznym śledzeniem zakrzywionych torów. To tak, jakby ktoś nauczył się jeździć rowerem po prostej ścieżce, a potem bez problemu pojechał slalomem między drzewami.
Proces jest w pełni audytowalny: po każdej modyfikacji zostaje log z uzasadnieniem. To ogromna zmiana w stosunku do neuronowych czarnych skrzynek, których decyzji często nie da się wyjaśnić nawet twórcom.
Mam mieszane uczucia, kiedy widzę, jak algorytm przepisuje własne instrukcje w nocy, kiedy nikt nie patrzy, i odkrywa prawa fizyki, które my sami moglibyśmy przegapić. Z jednej strony to przerażająco piękne, z drugiej strony, przypomina, że nasza rola w pętli może się powoli kończyć.
- Agent samodzielnie przekształcił jednostronnie zaburzony seed policy w uniwersalny sterownik zdolny do osiągania celów w pełnym zakresie kątów.
- Odkryty kontroler działa od ręki na nieznanych wcześniej trajektoriach – zarówno statycznych, jak i dynamicznych, bez dodatkowego treningu.
- Proces ewolucji pozostawia pełny, czytelny ślad: wiadomo, dlaczego i kiedy kod został zmieniony.
- Wynikowy kod zawiera fizycznie umotywowane komponenty, takie jak sprzężenie od yaw-rate czy adaptacyjne zmniejszanie częstotliwości ogona.
Praktyczne zastosowania
Aby lepiej zrozumieć opisywaną innowację, przygotowaliśmy cztery przykłady praktycznego zastosowania tej technologii w różnych branżach:



Podsumowanie
Pokazane podejście może zmienić sposób, w jaki projektuje się sterowniki dla dronów podwodnych, turbin wiatrowych wykorzystujących aktywną kontrolę przepływu czy mikrorobotów medycznych poruszających się w cieczach ustrojowych. Zamiast kosztownego uczenia maszynowego dostajemy zrozumiały algorytm, który inżynier może od ręki przeanalizować i poprawić. To pierwszy krok do agentów, które nie tylko optymalizują, ale naprawdę rozumieją fizykę zjawisk.
Metryka artykułu źródłowego
Tytuł oryginalny: Self-Evolving Scientific Agent Discovers Generalizable Physically-Reasoned Fluid Control
Autorzy: Boai Sun, Wenjin Guo, Zongmin Yu, Liu Yang
Data publikacji: 9 czerwca 2026
arXiv: arxiv.org/abs/2606.08405
Napisanie tego artykułu zostało wspomagane przez sztuczną inteligencję. Treść opiera się na oryginalnym artykule naukowym, a jej dokładność została zweryfikowana automatycznie.
{kind=link}