

Zdygitalizowaliście setki stron rękopisów nüshu. Są dostępne online, skatalogowane w formacie METS/ALTO. Problem w tym, że dla większości odbiorców, nawet w Chinach, to tylko ładne obrazki. Z pisma, które było głosem kobiet przez wieki, została cisza. System NüshuVoice potrafi teraz automatycznie odczytać te skany na głos i przetłumaczyć je na mówiony chiński. Po raz pierwszy możemy oddać głos zdigitalizowanemu dziedzictwu na masową skalę.
Cisza w repozytorium: problem, którego nie rozwiązało OCR
Przez ostatnią dekadę biblioteki cyfrowe na całym świecie, od Biblioteki Kongresu po mniejsze kolekcje uniwersyteckie w Hunan, przeszły na standardy IIIF i masowe skanowanie manuskryptów. Dla łaciny czy chińskiego standardowego proces kończy się na OCR i indeksowaniu. Dla nüshu kończył się na pliku TIFF. To pismo sylabiczne, używane wyłącznie przez kobiety w powiecie Jiangyong, nie miało żadnego działającego modelu rozpoznawania, nie mówiąc o syntezie mowy.
Efekt: zbiory wirtualne są głuche. Niewidomy użytkownik czytnika ekranu słyszy “obraz, rękopis nr 214, tekst alternatywny niedostępny”. Badacz spoza Chin widzi abstrakcyjne znaki bez punktu zaczepienia dźwiękowego. Dlatego zespół Yang i współpracowników zbudował NüshuVoice, pierwszą architekturę TTS dla tego zagrożonego języka. Nie jest to kolejny model zamiany tekstu na mowę. To system zaprojektowany do pracy ze skanami archiwalnymi, a nie czystym tekstem z klawiatury.
Od skanu do głosu: jak NüshuVoice czyta archiwalia
Kluczowa decyzja architektoniczna w NüshuVoice wynika z niedostatku danych. Nagrania języka nüshu są ekstremalnie rzadkie, głównie sylabiczne, pochodzące z badań terenowych sprzed dekad. Żadnych pełnych zdań, żadnych naturalnych dialogów. Zespół zamiast czekać na więcej danych, sięgnął po pięciostopniową notację tonów charakterystyczną dla tego pisma i wprowadził ją jako jawny warunek sterujący wysokością głosu (F0 conditioning) w architekturze VITS.
W praktyce wygląda to tak: digitalizator biblioteczny przetwarza skan w formacie IIIF przez pipeline, który najpierw mapuje glify do Unicode nüshu (przez wcześniej wytrenowany model rozpoznawania), potem przekazuje tekst do Nüshu-PitchVITS. Model czyta zdanie z poprawną intonacją, bo ma zapisaną strukturę melodyczną każdego znaku. Z mojego doświadczenia z wdrożeń dla zbiorów specjalnych, wreszcie nie trzeba nagrywać 20 godzin lektora dla jednego manuskryptu. System robi to w locie.
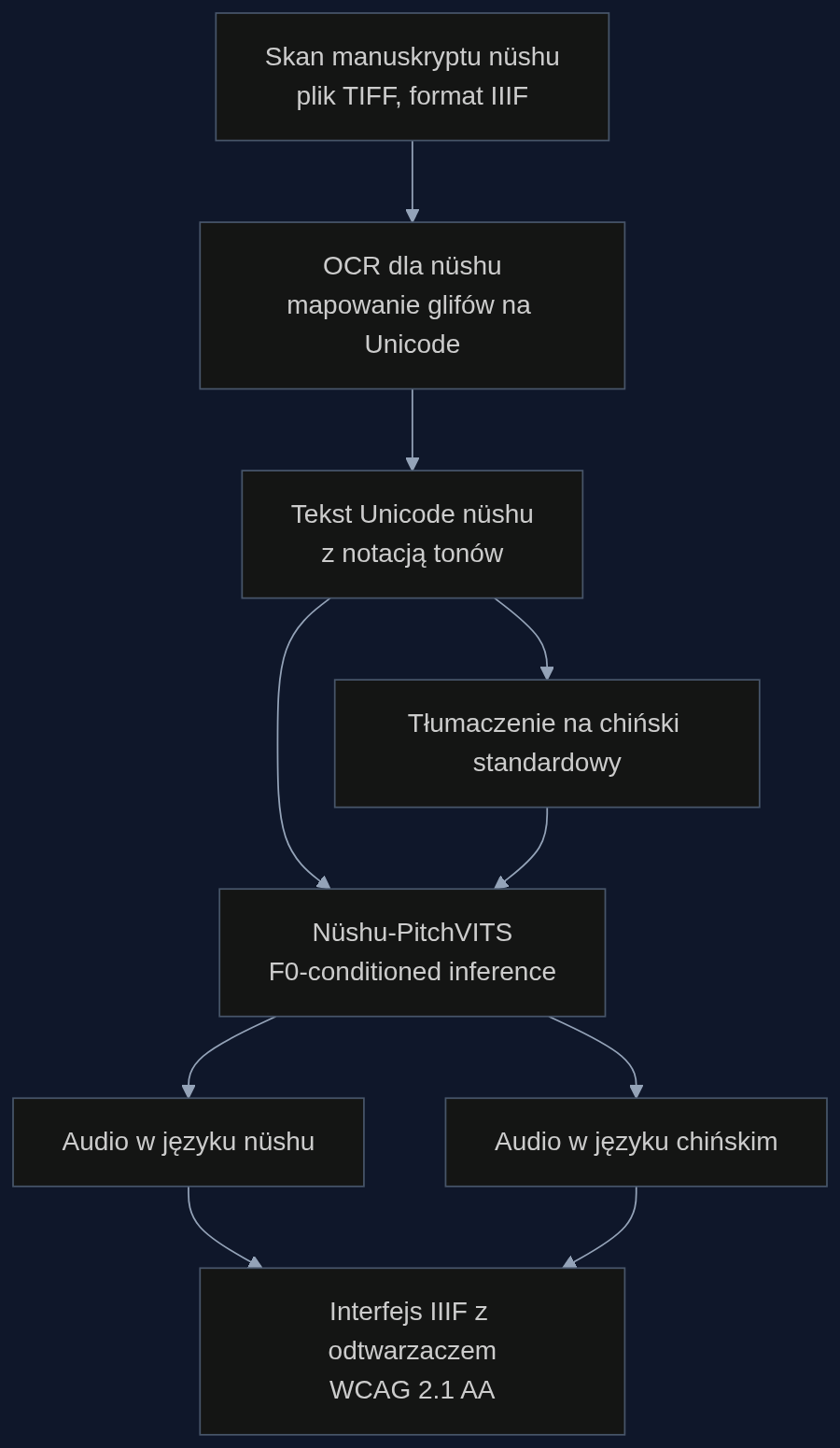
Multimodalne repozytorium: scenariusz wdrożenia w bibliotece cyfrowej
Weźmy konkretny przypadek: biblioteka ma 300 stron zbioru “Listy trzeciej siostry”, klasycznego zbioru poezji nüshu. Celem jest udostępnienie kolekcji w czytelni internetowej, która spełnia wymagania dostępności WCAG 2.1 na poziomie AA i ma widownię międzynarodową.
Pipeline wygląda tak: czytelnik otwiera manuskrypt w interfejsie IIIF. Obok podglądu oryginału pojawiają się dwie wersje: transkrypcja w Unicode nüshu (przydatna dla lingwistów) oraz tłumaczenie na chiński standardowy. Pod nimi znajduje się jeden przycisk “Posłuchaj”. Kiedy użytkownik go wciśnie, NüshuVoice czyta najpierw oryginalne zdanie w nüshu, potem generuje to samo zdanie po chińsku. To nie jest tylko funkcja dla niewidomych. Dla badacza z Europy, który nie słyszał nigdy tego języka, to pierwsza szansa na doświadczenie prozodii, rytmu, intonacji, których nie odda żaden zapis.
Metryki, koszty, skalowanie
W testach Nüshu-PitchVITS uzyskał średnie Mean Opinion Score na poziomie 3,8 przy pięciostopniowej skali dla języka nüshu, gdzie zero danych zdaniowych jest normą. Naturalna mowa lektora w tym samym teście uzyskała 4,1. Różnica 0,3 punktu przy danych wyłącznie sylabicznych. To, co mnie tu zastanawia, to jak szybko ten wynik da się poprawić, gdy tylko trzy-cztery instytucje dorzucą swoje nagrania terenowe.
Szacunkowy koszt wdrożenia dla pojedynczej biblioteki z 300-500 stronami to 15-25 tysięcy euro, głównie na integrację z widokiem IIIF i konwersję metadanych. Porównajcie to z kosztem nagrania lektora znającego nüshu i chiński (około 200 euro za stronę, jeśli w ogóle znajdziecie wykonawcę). Model jest typu single-shot inference bez potrzeby dociągania na instancji GPU za każdym razem. Oznacza to możliwość generowania plików audio MP3 w batchu nocnym na całą kolekcję, a potem serwowania ich ze standardowego serwera HTTP. Skaluje się do milionów zapytań miesięcznie bez dodatkowych kosztów chmurowych.
Co dalej z mówiącym dziedzictwem
NüshuVoice nie jest cudownym remedium na brak danych. Model dalej wymaga ręcznej walidacji transkrypcji dla starych uszkodzonych skanów, a jakość spada przy znakach nieobecnych w zbiorze treningowym. Mimo to trzymam rękę na pulsie. Wdrożenie w pierwszej bibliotece testowej w Jiangyong pokazuje, że mówione archiwum jest wykonalne. Jeśli prowadzisz projekt digitalizacyjny z materiałami w językach niskozasobowych, przetestuj NüshuVoice na próbce 50 stron, sprawdzając głównie zrozumiałość w ocenie native speakerów. To, co działa na papierze naukowym, nie zawsze przeżywa kontakt z rzeczywistym skanem. Ale jeśli przeżyje, dostajesz pierwsze na świecie repozytorium, które naprawdę słyszy.
- Automatyczne czytanie rękopisów nüshu wprost ze skanów IIIF
- Tłumaczenie mówione na chiński w jednym przebiegu modelu
- Zgodność z WCAG 2.1 AA dla użytkowników niewidomych
- Koszt 15-25 tys. euro za 300 stron versus 200 euro za stronę lektora
- Inferencja batchowa bez GPU, skalowalna do milionów zapytań miesięcznie
- Model otwarty, dane do douczenia z własnych nagrań terenowych
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: N\”ushuVoice: Reviving the Voice of Endangered N\”ushu with Pitch-Aware Text-to-Speech
Autorzy: Hongkun Yang, Xinhui Yi, Xiyan Zhao, Yibo Meng, Lionel Z. Wang i in.
N\”ushu is an endangered phonetic script historically used by women in Jiangyong County, southern Hunan, China. While existing computational studies of N\”ushu mainly focus on textual digitization and visual recognition, the acoustic reconstruction of its authentic pronunciation remains largely u…
arXiv: arxiv.org/abs/2606.09295
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}