
Nüshu to pismo, którym przez stulecia posługiwały się kobiety w południowych Chinach. Dziś jest na skraju wymarcia. Dzięki połączeniu archiwalnych nagrań i modelu rozpoznającego melodię języka badacze stworzyli system, który potrafi wypowiedzieć na głos każdy zapisany znak. To nie tylko techniczna ciekawostka: to szansa, że język, który prawie zamilkł, znów będzie słyszalny.
Pismo tylko dla kobiet: krótka historia nüshu
Nüshu to coś więcej niż zbiór znaków. To jedyny na świecie system pisma stworzony i używany wyłącznie przez kobiety. Powstał w powiecie Jiangyong w Hunanie i przez setki lat służył do pisania listów, poezji, pieśni, a nawet dekorowania haftów. Język ten był przekazywany z matki na córkę, z przyjaciółki na przyjaciółkę, tworząc intymną nić porozumienia poza oficjalnym, męskim światem chińskich znaków.
Problem w tym, że w XX wieku zwyczaj zanikł. Zabrakło nowych użytkowniczek, a ostatnia osoba biegle władająca nüshu zmarła w 2004 roku. Dziś pozostało około kilkuset znaków, kilka książek i garść archiwalnych nagrań. Właśnie z tą garścią musieli zmierzyć się autorzy NüshuVoice.
‘Nüshu jest zagrożonym skryptem fonetycznym używanym historycznie przez kobiety w powiecie Jiangyong w południowych Chinach.’
Yang et al., NüshuVoice paper, 2026
To, że nüshu jest pismem fonetycznym, ma tu ogromne znaczenie. Każdy znak odpowiada sylabie, a znaczenie zależy od tonu, czyli od tego, czy sylabę wypowiadamy wysoko, nisko, opadająco czy wznosząco. Dlatego nie wystarczy zamienić tekstu na dźwięk. Trzeba oddać tę melodię.
Skąd wziąć głos, gdy nagrań prawie nie ma?
Budowa systemu zamiany tekstu na mowę wymaga tysięcy godzin starannie odczytanych zdań. W wypadku nüshu autorzy mogli liczyć na nagrania sylab, krótkie fragmenty wypowiedzi, czasem pojedyncze słowa. Naturalnych wypowiedzi zdaniowych praktycznie nie było.
‘Budowa systemu zamiany tekstu na mowę dla nüshu jest szczególnie trudna, ponieważ dostępne nagrania są bardzo ograniczone i w większości składają się z izolowanych wymówień sylabicznych, a nie naturalnych wypowiedzi zdaniowych.’
Yang et al., NüshuVoice paper, 2026
Zespół zebrał wszystko, co dało się odszukać w archiwach, po czym scalił to z tekstami zapisanymi w standardzie Unicode, transkrypcjami fonetycznymi i tłumaczeniami na chiński standardowy. Powstał pierwszy w historii zbiór danych zdaniowych dla nüshu. Jest mały, nieidealny, ale realny. I okazał się wystarczający, by wytrenować model generujący mowę z zaskakującą precyzją.
Nüshu jest zagrożonym skryptem fonetycznym używanym historycznie przez kobiety w powiecie Jiangyong w południowych Chinach.
Yang et al.
NüshuVoice paper, 2026
Ton ma znaczenie: jak model uczy się melodii
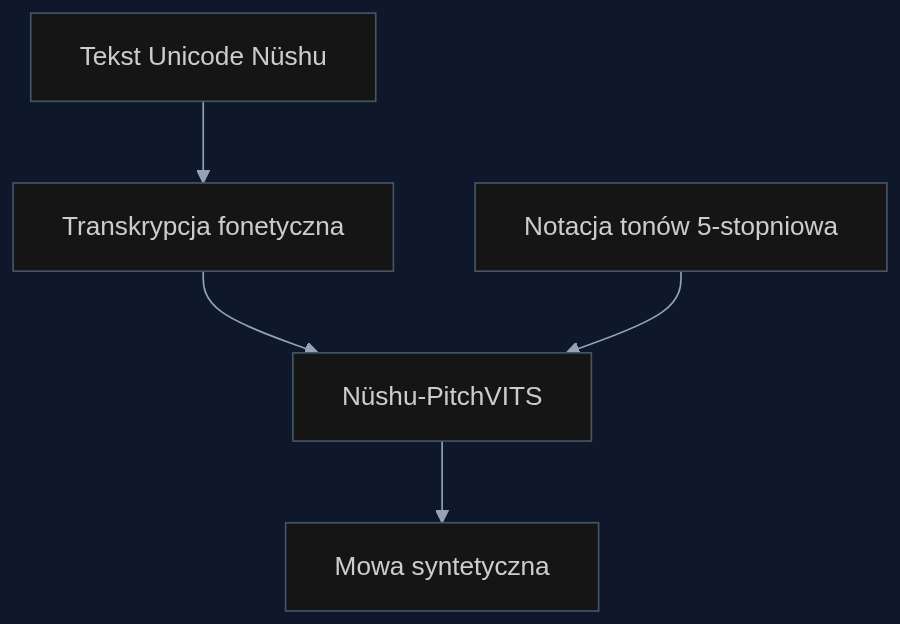
W zwykłym systemie TTS tekst wchodzi, dźwięk wychodzi. Często jednak takie modele gubią prozodię, czyli rytm, intonację i barwę głosu. W językach tonalnych, takich jak nüshu, to katastrofa. Inny ton to inne słowo. Autorzy postawili na architekturę VITS, która od razu generuje czystą falę dźwiękową, bez pomocniczego wokodera. Brzmi to technicznie, ale w praktyce oznacza mniej błędów i bardziej naturalny głos.
Kluczowym dodatkiem było jawne podanie wysokości tonu. Nüshu ma własny system notacji: pięciostopniową skalę, gdzie 1 oznacza ton najniższy, a 5 najwyższy. Model Nüshu-PitchVITS dostaje tę informację razem z tekstem i od razu wie, z jaką melodią ma wypowiedzieć każdą sylabę.
‘Proponujemy Nüshu-PitchVITS, framework VITS warunkowany częstotliwością podstawową (F0), który wykorzystuje pięciostopniową notację wysokości tonu nüshu jako jawną indukcyjną wskazówkę prozodyczną.’
Yang et al., NüshuVoice paper, 2026
Efekt? Syntezator nie zgaduje tonu na podstawie kontekstu, tylko odtwarza go zgodnie z zapisem. To jak podpowiedź dla śpiewaka: nie musisz zgadywać nuty, masz ją przed sobą.
Brzmi jak człowiek? Testy i odsłuchy
Badacze porównali Nüshu-PitchVITS z kilkoma silnymi modelami TTS, oceniając zarówno parametry techniczne, jak i wrażenia słuchaczy. Pod kątem widmowym mowa była czystsza, bliższa oryginalnym nagraniom. Największą różnicę zrobiła jednak właśnie dokładność odtwarzania tonu. W języku, gdzie ton zmienia znaczenie, to nie kosmetyka, to zrozumiałość.
W testach odsłuchowych osoby oceniające wskazywały, że mowa generowana przez Nüshu-PitchVITS brzmi bardziej naturalnie i łatwiej zrozumieć poszczególne słowa. Co ciekawe, nawet na tak skromnym materiale treningowym model nie popadł w przeuczenie. Nadal radzi sobie z nowymi zdaniami, których nigdy nie słyszał w oryginale.
Nie oznacza to, że system jest idealny. Od czasu do czasu gubi drobne niuanse melodyczne, a w bardzo długich frazach intonacja pod koniec potrafi lekko osunąć się w monotonię. Ale jak na pierwszy TTS dla wymierającego języka, to wynik więcej niż obiecujący.
Co dalej z głosem nüshu?
Technologia nie zastąpi żywych nosicielek kultury, ale może być protezą pamięci. NüshuVoice mógłby trafić do audioprzewodników w muzeach, gdzie zwiedzający usłyszeliby wiersze czytane syntetycznym, ale bliskim oryginałowi głosem. Mógłby stać się częścią aplikacji, która pokazuje znak nüshu, tłumaczy go i wypowiada na głos, pomagając kolejnym pokoleniom uczyć się tego pisma nie tylko wizualnie, ale i słuchowo.
Co mnie uderza, to odwrócenie logiki typowego projektu AI. Zwykle brak danych dyskwalifikuje język. Tu brak danych stał się wyzwaniem, które zmusiło do wymyślenia czegoś celniejszego: modelu, który słucha podpowiedzi o tonie. Może podobne podejście sprawdzi się dla innych zagrożonych języków tonalnych, których na świecie są setki.
- Pierwszy w historii system TTS dla języka nüshu i dedykowany zbiór danych zdaniowych.
- Model Nüshu-PitchVITS skutecznie radzi sobie z ekstremalnie małą liczbą nagrań, głównie sylabicznych.
- Wykorzystanie historycznej pięciostopniowej notacji tonów poprawia naturalność i zrozumiałość syntezowanej mowy.
- W testach odsłuchowych system osiągnął wyższą wierność tonu i lepszą zrozumiałość niż modele bazowe.
Praktyczne zastosowania
Aby lepiej zrozumieć opisywaną innowację, przygotowaliśmy cztery przykłady praktycznego zastosowania tej technologii w różnych branżach:




Podsumowanie
Technologia NüshuVoice może zostać wykorzystana do tworzenia audioprzewodników w muzeach i na wystawach poświęconych kulturze nüshu, do budowy aplikacji edukacyjnych pomagających uczyć się wymowy tego pisma, a także jako narzędzie dla lingwistów badających języki tonalne. Dzięki temu, co było pisane, może znów zabrzmieć.
Metryka artykułu źródłowego
Tytuł oryginalny: N\”ushuVoice: Reviving the Voice of Endangered N\”ushu with Pitch-Aware Text-to-Speech
Autorzy: Hongkun Yang, Xinhui Yi, Xiyan Zhao, Yibo Meng, Lionel Z. Wang, Lixu Wang, Yaqi Zhang, Ruiqi Chen, Xuanyue Zhao, Lanxin Zhang, Yu Zeng, Weijia Chu, Yiming Ma, Chenyu Liu, Jianghao Lin, Xin Xu
Data publikacji: 9 czerwca 2026
arXiv: arxiv.org/abs/2606.09295
Napisanie tego artykułu zostało wspomagane przez sztuczną inteligencję. Treść opiera się na oryginalnym artykule naukowym, a jej dokładność została zweryfikowana automatycznie.