

Kursy nauki nüshu, pisma używanego przez kobiety z Jiangyong, zaczynają przyciągać potomków i pasjonatów. Problem? Prawie nie ma z kim ćwiczyć wymowy. Ostatnie nagrania native speakerów pochodzą sprzed dekad, a znalezienie lektora, który poprawnie odda pięciostopniową notację tonów, graniczy z cudem. NüshuVoice może to zmienić.
Czym jest NüshuVoice i dlaczego działa mimo braku danych
NüshuVoice to pierwszy system zamiany tekstu na mowę dla zagrożonego języka nüshu. Zbudowany na architekturze VITS, warunkowanej częstotliwością podstawową (F0), wykorzystuje historyczną, pięciostopniową notację tonów jako jawną wskazówkę prozodyczną. Dzięki temu potrafi wygenerować wyraźną, naturalnie brzmiącą mowę z zaledwie kilkuset nagranych sylab – to sytuacja, w której większość konwencjonalnych modeli TTS po prostu by się poddała. W testach porównawczych model Nüshu-PitchVITS uzyskał wyższą wierność widmową, dokładniejszą rekonstrukcję tonu i lepszą ocenę zrozumiałości od oceniających go słuchaczy. Mówiąc wprost: to nie jest ciekawostka laboratoryjna, tylko działające narzędzie do odtwarzania zaginionego języka.
Scenariusz: laboratorium językowe ze smartfona
Wyobraźmy sobie kurs online organizowany przez stowarzyszenie w Jiangyong lub przez diasporę w Wielkiej Brytanii. Uczestnicy pobierają apkę, która po zeskanowaniu kodu Unicode danego znaku nüshu (standard Unicode obejmuje dziś ponad 500 znaków tego pisma) odtwarza poprawną wymowę sylaby z precyzyjną intonacją tonalną. Użytkownik słucha, a potem nagrywa swoje powtórzenie. Aplikacja analizuje przebieg częstotliwości podstawowej nagrania i porównuje go z wzorcem generowanym przez NüshuVoice – od razu dostaje informację, czy ton ‘wysoki opadający’ faktycznie opadł z poziomu 5 na 2, czy raczej został płaski lub narastający. System można wykorzystać zarówno w trybie samodzielnej nauki, jak i w interaktywnych warsztatach online, gdzie uczestnicy pracują w parach, korygując swoje próby na podstawie precyzyjnego sprzężenia zwrotnego.
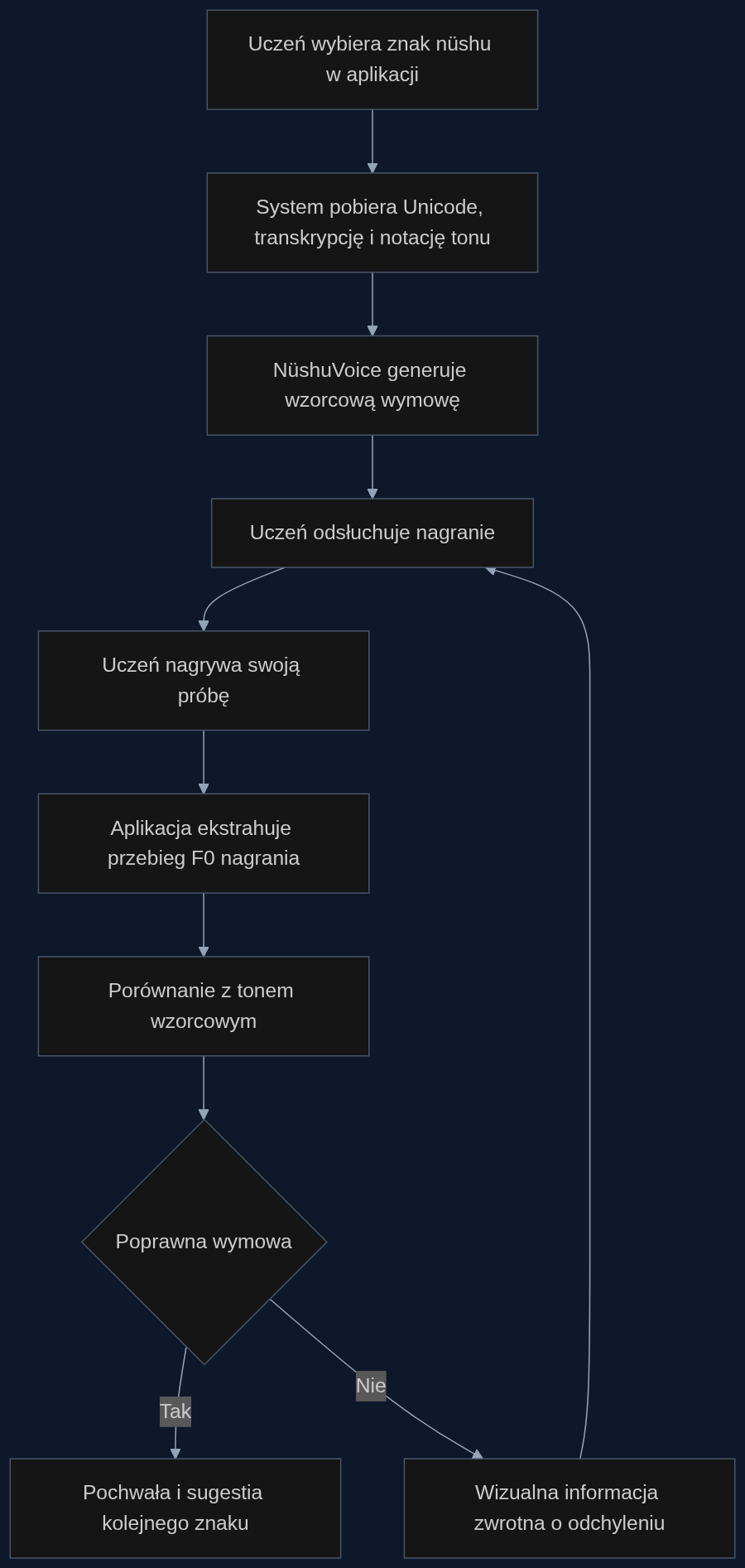
Co zyskują organizatorzy kursów i aktywiści
Dla organizatora kursu oszczędność jest wymierna: zamiast opłacać rzadkiego native speakera za każdą dodatkową sesję ćwiczeniową, może udostępnić każdemu słuchaczowi osobistego tutora pracującego 24 godziny na dobę. Przy grupie 50 osób, które ćwiczą średnio 30 minut dziennie, to 25 godzin tygodniowo – czas, który lektor może przeznaczyć na bardziej złożone aspekty językowe, jak frazeologia czy kontekst kulturowy. Dla aktywistów rewitalizacji językowej stawka jest wyższa: każdy nowy użytkownik, który dzięki regularnym ćwiczeniom z wymową osiągnie poziom swobodnej konwersacji, staje się żywym ogniwem w społeczności mówiącej nüshu. To przesuwa akcent z biernego dokumentowania na aktywną transmisję języka.
Podsumowanie: głos, który budzi język
NüshuVoice to więcej niż ciekawostka technologiczna – to narzędzie do odtwarzania kompetencji mówionej w języku, który prawie całkowicie zamilkł. Działa na danych, które są już dostępne, i nie wymaga kosztownych sesji nagraniowych. Jeśli prowadzisz kurs lub działasz na rzecz rewitalizacji nüshu, warto przetestować system na próbce 20 znaków o różnych tonach podczas najbliższego warsztatu. Koszt integracji z własną apką edukacyjną to kwestia lekkiego interfejsu webowego podłączonego do API modelu – a dane wejściowe w postaci transkrypcji Unicode i notacji tonów są publicznie dostępne.
- Osobisty tutor wymowy dostępny 24/7 dla każdego ucznia
- Oszczędność 25 godzin pracy lektora tygodniowo przy grupie 50 osób
- Dokładność tonów wyższa niż w dotychczasowych systemach TTS – potwierdzona testami słuchaczy
Informacje o artykule
Ten artykuł powstał w oparciu o paper naukowy opublikowany w serwisie arXiv.
Paper: N\”ushuVoice: Reviving the Voice of Endangered N\”ushu with Pitch-Aware Text-to-Speech
Autorzy: Hongkun Yang, Xinhui Yi, Xiyan Zhao, Yibo Meng, Lionel Z. Wang i in.
N\”ushu is an endangered phonetic script historically used by women in Jiangyong County, southern Hunan, China. While existing computational studies of N\”ushu mainly focus on textual digitization and visual recognition, the acoustic reconstruction of its authentic pronunciation remains largely u…
arXiv: arxiv.org/abs/2606.09295
Artykuł wygenerowany ze wsparciem sztucznej inteligencji.
{kind=link}