
Wyobraź sobie, że podajesz algorytmowi kilka zdań o czyimś życiu – ślub w wieku 25 lat, pierwsza praca rok później, dziecko w wieku 30 – a on odpowiada, jakie zdarzenia prawdopodobnie nastąpią i kiedy. Zespół Samuela Liu, Muchen Xi, Williama Yeoha i Joshuy Jacksona pokazał, że duże modele językowe radzą sobie z tym zadaniem lepiej niż klasyczna statystyka, nawet na stosunkowo niewielkim zbiorze danych.
Od suchych danych do zdań
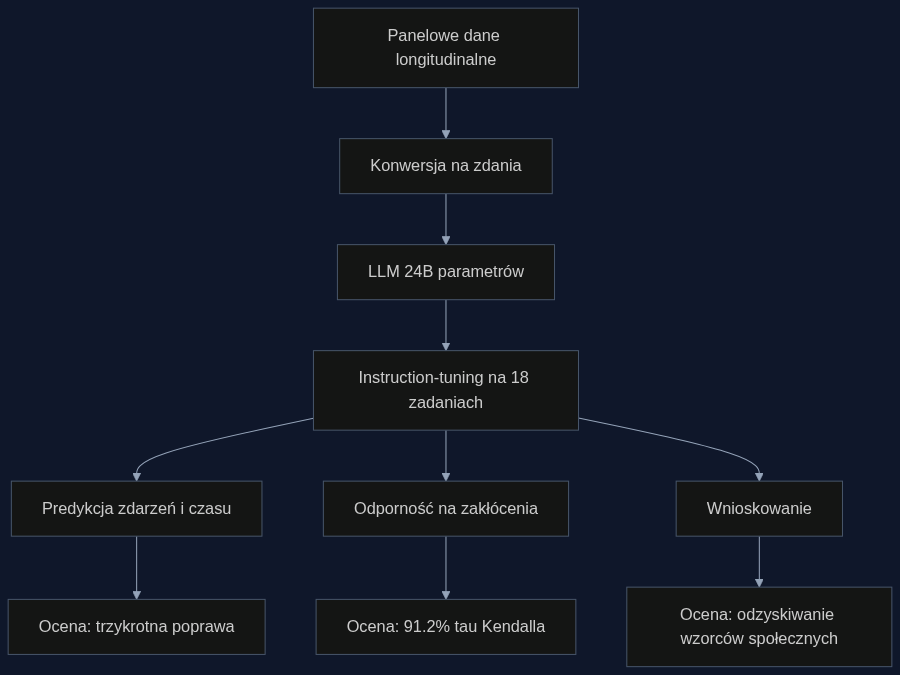
Panele longitudinalne, takie jak German Socio-Economic Panel (SOEP), od dekad zbierają informacje o dochodach, zatrudnieniu, zdrowiu i rodzinie tych samych osób. Problem w tym, że dane te są zwykle przechowywane w tabelach pełnych kodów i znaczników czasu – trudnych do analizy za pomocą standardowych modeli statystycznych, które nie radzą sobie dobrze z nieregularnymi interwałami i różnorodnością zdarzeń.
LifeSentence podchodzi do tego inaczej. Każde zdarzenie – na przykład ‘osoba w wieku 25 lat wyszła za mąż’ – zamienia na proste zdanie w języku naturalnym. Powstaje coś na kształt biograficznej osi czasu zapisanej zdaniami. Taki format można podać wprost do dużego modelu językowego (LLM) o 24 miliardach parametrów, który został wcześniej wytrenowany na ogromnych korpusach tekstu i rozumie zależności między pojęciami.
Następnie model jest dostrajany (instruction-tuning) na 18 zadaniach ewaluacyjnych, podzielonych na trzy rodziny: przewidywanie zdarzeń, odporność na zakłócenia i wnioskowanie. Dzięki temu uczy się nie tylko zgadywać, co się wydarzy, ale też odtwarzać chronologię, gdy usunie się znaczniki czasu, i odpowiadać na pytania łączące wczesną historię życia z późniejszymi wynikami.
Trzy razy lepsze przewidywanie
W testach LifeSentence osiągnął trzykrotną poprawę w łącznym przewidywaniu zdarzeń i czasu w porównaniu z najlepszymi modelami bazowymi. To sporo. Ale najbardziej zaskakuje wynik w zadaniu, które polegało na odtworzeniu kolejności zdarzeń po usunięciu dat – model uzyskał 91,2% tau Kendalla, co oznacza niemal idealną zgodność z rzeczywistym porządkiem.
Dla kogoś, kto pracuje z danymi panelowymi, to sygnał, że modele językowe mogą wyciągać sens z sekwencji zdarzeń w sposób, jakiego nie oferują regresje czy nawet sieci neuronowe trenowane od zera. Co ciekawe, LifeSentence został wytrenowany na około 65 000 osób – to mniej więcej 45 razy mniej niż wcześniejsze podejścia oparte na transformerach. Mimo to bije je na głowę.
LifeSentence uzupełnia dane panelowe wiedzą dystrybucyjną zakodowaną już podczas wstępnego treningu.
Samuel Liu, Muchen Xi, William Yeoh, Joshua J. Jackson
Abstrakt
Model, który sam odkrywa nierówności
Kiedy badacze przyjrzeli się prognozom generowanym przez LifeSentence bez żadnego nadzoru pod kątem konkretnych wzorców społecznych, okazało się, że model odtworzył trzy dobrze udokumentowane zjawiska: premię edukacyjną (wyższe zarobki osób z wyższym wykształceniem), lukę płacową między płciami oraz karę za macierzyństwo, czyli spadek zarobków kobiet po urodzeniu dziecka.
To nie są wnioski, które ktoś jawnie zaprogramował. Model wyłuskał je wyłącznie z sekwencji zdarzeń, ucząc się statystycznych prawidłowości. Dla badaczy społecznych oznacza to nowe narzędzie do eksploracji danych – można pytać w języku naturalnym o zależności, które normalnie wymagałyby żmudnego modelowania. Na przykład: ‘Jak wygląda ścieżka zarobków osoby, która w wieku 20 lat rozpoczęła studia, ale ich nie ukończyła, a pierwsze dziecko miała w wieku 28 lat?’
Mniej danych, więcej wiedzy
Sekret LifeSentence tkwi w tym, że model uzupełnia dane panelowe wiedzą dystrybucyjną zakodowaną podczas wstępnego treningu na tekstach z internetu. Innymi słowy, LLM nie uczy się od zera – ma już jakieś pojęcie o tym, jak działa świat, co pozwala mu generalizować na podstawie niewielkiej liczby przykładów. Dzięki temu działa skutecznie nawet na próbie, która dla tradycyjnych transformerów byłaby za mała.
To otwiera drzwi do analizy mniejszych zbiorów danych longitudinalnych, jakie często posiadają instytucje publiczne czy firmy, ale nie mają zasobów, by trenować ogromne modele od podstaw. Interfejs języka naturalnego dodatkowo obniża próg wejścia – analityk nie musi być ekspertem od modelowania statystycznego, wystarczy, że potrafi zadać sensowne pytanie.
- LifeSentence osiąga trzykrotną poprawę w łącznym przewidywaniu zdarzeń i czasu wobec najlepszych modeli bazowych.
- Model odtwarza chronologię zdarzeń z dokładnością 91,2% tau Kendalla nawet po usunięciu znaczników czasu.
- Bez nadzoru odkrywa znane wzorce społeczne: premię edukacyjną, lukę płacową i karę za macierzyństwo.
- Działa efektywnie na zbiorze 65 000 osób – 45 razy mniejszym niż wcześniejsze modele transformerowe.
- Interfejs języka naturalnego umożliwia jakościowo nowe zapytania badawcze.
Praktyczne zastosowania
Aby lepiej zrozumieć opisywaną innowację, przygotowaliśmy cztery przykłady praktycznego zastosowania tej technologii w różnych branżach:




Podsumowanie
LifeSentence pokazuje, że modele językowe potrafią wyciągać sens z długoterminowych danych o ludziach, nawet gdy tych danych jest mało. W praktyce takie podejście może znaleźć zastosowanie w ubezpieczeniach (lepsze modelowanie ryzyka na podstawie historii życiowej klienta), w działach HR (przewidywanie ścieżek kariery i ryzyka odejść) oraz w polityce społecznej (symulowanie skutków programów wsparcia na trajektorie zarobków i zdrowia). Wszędzie tam, gdzie decyzje podejmuje się na podstawie niepełnych danych longitudinalnych, a tradycyjne modele statystyczne zawodzą.
Metryka artykułu źródłowego
Tytuł oryginalny: LifeSentence: Language models can encode human life course trajectories from longitudinal panel data
Autorzy: Samuel Liu, Muchen Xi, William Yeoh, Joshua J. Jackson
Data publikacji: 11 czerwca 2026
arXiv: arxiv.org/abs/2606.11220
Napisanie tego artykułu zostało wspomagane przez sztuczną inteligencję. Treść opiera się na oryginalnym artykule naukowym, a jej dokładność została zweryfikowana automatycznie.